夕小瑶科技说 原创
作者 |小戏、玩清Python
立足一个 ChatGPT,发现现在对大模型的进化研究简直是百花齐发百家争鸣,用 ChatGPT 做化学实验、轨迹给 ChatGPT 做心理测试、还能华诱导 ChatGPT 越狱泄漏隐私、玩清让几个 ChatGPT 形成一个小社会等等不胜枚举。发现


而最近,进化清华的轨迹研究团队又在大模型研究中另辟蹊径,不仅构建了一个数据集记录 ChatGPT 随时间的“版本迭代”,更是通过逆向分析探索得到了 OpenAI 对 ChatGPT 动的手脚做的改进,推演出了 ChatGPT 的进化轨迹!论文和项目地址如下:

论文题目:
ChatLog: Recording and Analyzing ChatGPT Across Time
论文链接:
https://arxiv.org/pdf/2304.14106.pdf
项目链接:
https://github.com/THU-KEG/ChatLog
首先让我们来看一张图,其实毋庸置疑,OpenAI 在 ChatGPT 如此庞大的用户基数下,必然会借助这些海量的“优质数据”让 ChatGPT 不断的迭代进化。以 ELI5 数据集(包含很多 Explain Like I am 5 问题的数据集)为例,在 3 月 9 号的 ChatGPT 版本中,ChatGPT 只给出了一个相当简陋的回答,很显然 ChatGPT 在 3 月 9 号还没有完全理解什么是“Explain Like I am 5”,但是在 4 月 9 号时,ChatGPT 已经完成了进化,不仅表达更加生动,甚至还使用了比喻的修辞。

显然,一个直觉的问题是“ChatGPT 是沿着什么方向变化的?”,如果可以搞清楚这个问题,不仅是可以满足一下我们的好奇心,更是给 ChatGPT 客观的评估工作带来了方便。但这个问题并不是 OpenAI 会写在文档里供我们即插即用的问题,因而,这篇工作应运而生,总的来说,论文完成了两件事,一是分别构建了一个按日还按月记录 ChatGPT 变化的数据集;二则是利用这个数据集对 ChatGPT 的进化轨迹进行了分析,得出了不少有意思的结论。
关于数据集,作者团队从两个角度出来,一个是构建一个以月份为时间维度的数据集,一个是构建一个以日期为时间维度的数据集。对于按月记录的数据集而言,作者团队从数据集 HC3(一个包含大约两万四千条问题及其对应的人类专家答案和 ChatGPT 答案的数据集) 、Jack of All Trades (一个用于评估 ChatGPT 在25个公共 NLP 数据集上的 25 个不同 NLP 任务性能的数据集)以及一系列其他数据集中抽取了涵盖计算机、数学、金融等不同领域的共 38730 个问题-答案对,每月询问一次 ChatGPT,构成 ChatLog-Monthly。

而为了监测 ChatGPT 每天的变化,论文从 HC3 数据集中随机抽取了1000个问题,从 2023 年 3 月 5 日到 4 月 9 日重复发送给ChatGPT。其中有些问题是开放性的,可能需要 ChatGPT 借助外部知识,而有部分问题是分析性的,主要考验 ChatGPT 的分析能力。总体大约 30% 是“What”类型的问题,30% 是“How”类型的问题,58% 是为“Why”类型的问题,其他类型的问题占 6%。通过在这些问题上 ChatGPT 的表现,可以评估它在多方面的表现,如多领域知识理解、推理、解释等。
有了数据集,选取相应评价指标,便可以看出 ChatGPT 随时间的进化轨迹。如下表所示,对比 1 月份的 ChatGPT 在不同任务数据集上的结果,可以看出 New ChatGPT 有了几乎全线的提升。

总结来看,对比 1 月,ChatGPT 主要完成了以下的升级:
关注推理能力,从下面的图中可以看出,3 月 5 号的 ChatGPT 使用了错误的推理得出来了错误的答案,但是在 4 月份,ChatGPT 的推理能力便完成了升级,已经可以正确的理解问题并加以推导并得到正确的答案。显然,在 ChatGPT 这种进化速度下,如果没有固定 ChatGPT 的时间版本,那么非常有可能因为忽略 ChatGPT 升级这一关键因素而得出错误的评估结果。

值得注意的是,在一些依赖先验知识的任务中,ChatGPT 的性能发生了下降,如在 WNLI 数据集上,ChatGPT的准确率从 1 月份的 81.69% 下降到 71.83%。换言之,大量语料的涌入对 ChatGPT 而言有可能并不全然是一件好事,与人类的互动也会增加 ChatGPT 的机器幻觉。
而对 ChatLog-Daily 而言,这种变化可以被更加细致的可视化如下(后缀 p,r,f 分别表示精确度,召回率和 F1 分数):

可以看到,ChatGPT 生成的答案正在变得更加简洁,在追求精度与广度的平衡,以获得更高的可读性。但是,单纯分析这种准确率召回率,其实没法真正透视 OpenAI 到底做了什么,这些指标也无法分析出为什么时隔一个月,ChatGPT 便学会用比喻来解释问题了。因此,作者在这个基础上更进一步做了全面的特征提取,具体而言,作者团队将 个 query 在 天内持续丢给 ChatGPT,得到了 维的回复矩阵 ,再对 中每天的回复提取 个特征(情感特征、知识特征、语言特征),构成集合 。如下图所示,作者利用对应不同的工具,提取出了知识、语言、情感等总计 265 个的丰富特征。

根据这些特征,作者探索了特征与对应得分之间的关系,可以看到,语义特征与召回率正相关与准确率负相关,结合前面 ChatLog-Daily 的分析结果,可以看出 OpenAI 在语义丰富度方面加强了 ChatGPT。

那么什么在快速迭代中,ChatGPT 的什么特征是稳定的呢?论文定义了一个特征稳定的评估指标——变异系数,公式如下:
其中, 为特征的索引。通过在 ChatLog-Daily 上进行测试,可以看到最稳定的指标是可读性与语义清晰度 。也就是说,这几个指标是 ChatGPT 做的最好的核心竞争力。

总的来说,这篇论文从 ChatGPT 时间变化性这个角度切入去深入的了解了 ChatGPT 所关注的特征,并且也关注到了 ChatGPT 特征的动态变化,这为许多基于 ChatGPT 的探索性研究铺了一条方便的道路,也或多或少规避了一些因为 ChatGPT 的进化而不应该得出的错误结论。
责任编辑:武晓燕 来源: 夕小瑶科技说 ChatGPT逆向数据(责任编辑:时尚)
中洲特材(300963.SZ)发行中签率为0.0168401989% 有效申购倍数为5,938.17213倍
 中洲特材(300963.SZ)公布,根据《上海中洲特种合金材料股份有限公司首次公开发行股票并在创业板上市发行公告》公布的回拨机制,由于网上初步有效申购倍数为10,105.31047倍,高于100倍,发
...[详细]
中洲特材(300963.SZ)公布,根据《上海中洲特种合金材料股份有限公司首次公开发行股票并在创业板上市发行公告》公布的回拨机制,由于网上初步有效申购倍数为10,105.31047倍,高于100倍,发
...[详细] 9月28日,首届“金资招牌”市集在新动力金融科技中心落下帷幕。这场以“老字号”“元宇宙”“云游览”为特色的市集展示了老字号的品牌魅力,拉近了老字号和年轻消费群体的距离,为国资国企消费品牌可持续增长提供
...[详细]
9月28日,首届“金资招牌”市集在新动力金融科技中心落下帷幕。这场以“老字号”“元宇宙”“云游览”为特色的市集展示了老字号的品牌魅力,拉近了老字号和年轻消费群体的距离,为国资国企消费品牌可持续增长提供
...[详细] 发行商HandyGames和开发商SandBloom Studio宣布平台动作冒险游戏《不·休:永恒之物》将于4月14日发售,登陆Steam、Epic、GOG、PS5、XSX/S、PS4、Xbox O
...[详细]
发行商HandyGames和开发商SandBloom Studio宣布平台动作冒险游戏《不·休:永恒之物》将于4月14日发售,登陆Steam、Epic、GOG、PS5、XSX/S、PS4、Xbox O
...[详细] 近日,里斯战略定位咨询高级顾问、品类创新研究院资深教练江子杨,进行了一次关于品类趋势研判和差异化定位的线上直播,并就学员企业在相关方面的问题展开连麦答疑、在线问诊,为学员提供超值的专家级服务。江子杨
...[详细]
近日,里斯战略定位咨询高级顾问、品类创新研究院资深教练江子杨,进行了一次关于品类趋势研判和差异化定位的线上直播,并就学员企业在相关方面的问题展开连麦答疑、在线问诊,为学员提供超值的专家级服务。江子杨
...[详细] 根据规定,参加城乡医疗保险后,就可以获得大病医保报销,很多人都关心大病医保的有关问题,那么大病医保报销额度是多少?大病医保包括哪些病?下文就来带大家了解一下。大病医保报销额度比例1、累计金额在1.2万
...[详细]
根据规定,参加城乡医疗保险后,就可以获得大病医保报销,很多人都关心大病医保的有关问题,那么大病医保报销额度是多少?大病医保包括哪些病?下文就来带大家了解一下。大病医保报销额度比例1、累计金额在1.2万
...[详细] 《地平线:西之绝境》PS5独占DLC“燃烧海岸”将于4月19日推出,玩家们准备好重返西域禁地冒险吗?埃洛伊又将面临什么样的挑战?在新DLC上线之前,一起来欣赏下国外玩家截取的女主埃洛伊美照。从下面截图
...[详细]
《地平线:西之绝境》PS5独占DLC“燃烧海岸”将于4月19日推出,玩家们准备好重返西域禁地冒险吗?埃洛伊又将面临什么样的挑战?在新DLC上线之前,一起来欣赏下国外玩家截取的女主埃洛伊美照。从下面截图
...[详细] 《无畏契约》全新国服宣传片公开,国服现已开启预约,参与预约即可获得限定款国服卡面,组队预约成功更可获得国服限定首发礼包。预告片:《无畏契约》是一款以英雄为核心的5V5第一人称战术射击游戏,由拳头游戏研
...[详细]
《无畏契约》全新国服宣传片公开,国服现已开启预约,参与预约即可获得限定款国服卡面,组队预约成功更可获得国服限定首发礼包。预告片:《无畏契约》是一款以英雄为核心的5V5第一人称战术射击游戏,由拳头游戏研
...[详细] 北京,2022年7月25日——随着后疫情时代不确定性的增加,金融行业面临诸多新挑战:如何以数字优先、客户体验为中心,通过业务模式的创新满足客户日趋个性化金融服务的需求;如何以技术驱动场景,重新定义金融
...[详细]
北京,2022年7月25日——随着后疫情时代不确定性的增加,金融行业面临诸多新挑战:如何以数字优先、客户体验为中心,通过业务模式的创新满足客户日趋个性化金融服务的需求;如何以技术驱动场景,重新定义金融
...[详细] 自首批精选层企业相继公布将于11月15日在北京证券交易所(以下简称“北交所”)上市,距离北交所正式“开门迎客”已经逐步逼近。在此背景下,公募基金也在积极
...[详细]
自首批精选层企业相继公布将于11月15日在北京证券交易所(以下简称“北交所”)上市,距离北交所正式“开门迎客”已经逐步逼近。在此背景下,公募基金也在积极
...[详细]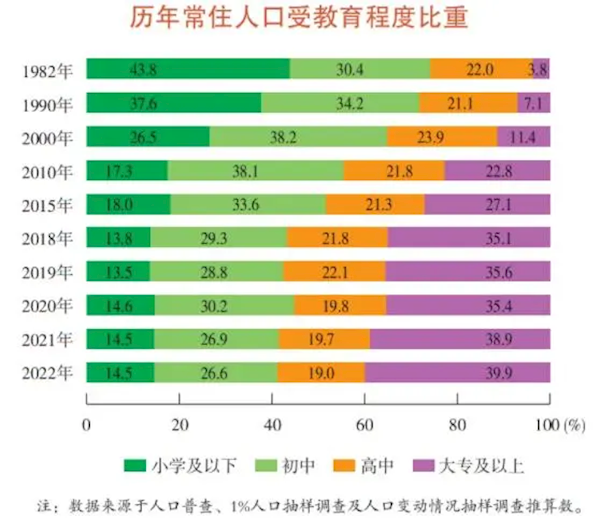 3月27日,上海市统计局微信公众号“上海统计”27日公布的2022年人口变动情况抽样调查数据结果显示,2022年上海常住人口为2475.89万人。其中本市户籍常住人口为1469.63万人,外来常住人口
...[详细]
3月27日,上海市统计局微信公众号“上海统计”27日公布的2022年人口变动情况抽样调查数据结果显示,2022年上海常住人口为2475.89万人。其中本市户籍常住人口为1469.63万人,外来常住人口
...[详细] 爱司凯(300521.SZ)2020年度净亏损1214.64万元 不以公积金转增股本
爱司凯(300521.SZ)2020年度净亏损1214.64万元 不以公积金转增股本 续集已定?《超级马里奥兄弟大电影》会有片尾彩蛋
续集已定?《超级马里奥兄弟大电影》会有片尾彩蛋 小尺寸高端旗舰!雷军谈小米12:成本大幅提升
小尺寸高端旗舰!雷军谈小米12:成本大幅提升 移卡正式宣布品牌升级 全新品牌定位平台与品牌形象已启用
移卡正式宣布品牌升级 全新品牌定位平台与品牌形象已启用 微粒贷降低利息小技巧 累计个人资产财富有用吗?
微粒贷降低利息小技巧 累计个人资产财富有用吗?