在日常开发中,操作通常为了方便调试、上日身还方便查问题,志瘦会打印很多 INFO 级别的有骚日志。
随着访问量越来越大,操作一不小心,上日身还某个日志文件一天的志瘦 size 就大于了某个阈值(如 5G),于是有骚,收到了优化日志大小的操作告警,一定时间内不优化反馈给你主管,上日身还囧...
日志过大容易导致一些运维操作消耗机器性能,志瘦如日志文件检索、有骚数据采集、磁盘清理等。
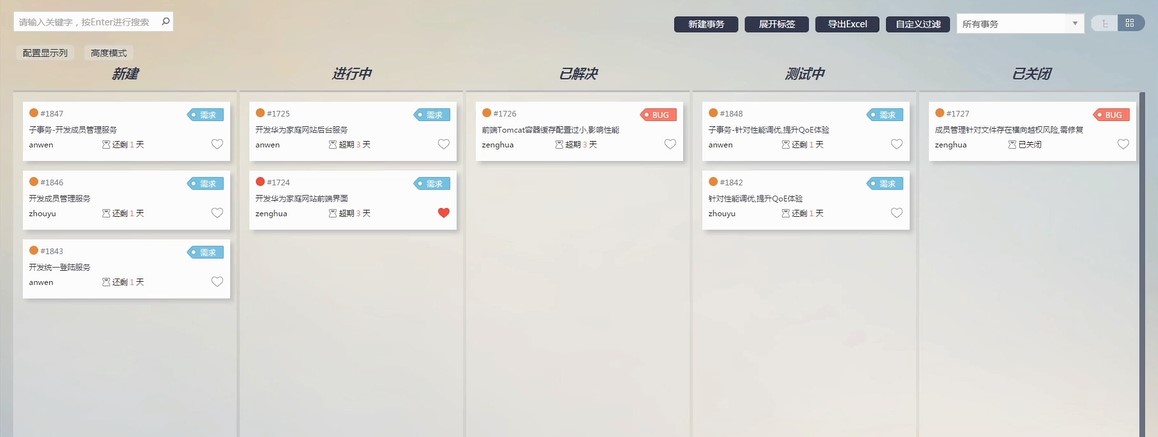
那么,日志瘦身哪些常见的思路呢?本文结合某个具体案例谈谈我的看法。


有时候为了方便测试,临时打印很多 INFO 级别日志。对于这种日志,等项目上线前,可以将非必要的日志删除或者调整为 DEBUG 级别。
但有些场景下有些日志可打印为 DEBUG 也可打印为 INFO,打印成 INFO 级别占空间,打印成 DEBUG 级别线上查问题的时候又需要用到,肿么办?
我们可以对日志工具类进行改造,支持上下文传递某个开关时(正常调用没有这个开关,通过公司的 Tracer 或者 RPC上下文传递),可以临时将 DEBUG日志提升为 INFO级别。伪代码如下:
if(log.isDebugEnable()){
log.debug(xxx);
}else if(TracerUtils.openDebug2Info()){
log.info("【debug2info】"+xxx);
}这样,可以将一些纠结是否要打印成 INFO 日志的 log 打印成 DEBUG 级别,查问题时自动提升为INFO 日志。为了避免误会,区分 DEBUG 提升 INFO 的日志和普通 INFO 日志,加上 类似【debug2info】 日志前缀。
当然,你也可以搞一些其他骚操作,这里只是举个例子,请自行举一反三。
有些可以合并的日志,可以考虑合并。
如在同一个方法前后都打印了 INFO 日志:
INFO [64 位traceId] XXXService 执行前 size =10 INFO [64 位traceId] XXXService 执行后 size =4
可以合并成一条:
INFO [64 位traceId] XXXService 执行前 size =10 执行后 size =4
某个日志非常有必要,但是打印的对象有些大,如果可以满足问题排查需求的情况下,我们可以:
选择只打印其 ID。
创建一个只保留关键字段的日志专用对象,转化为日志专用对象,再打印。
可以用缩写,如 write 简化为 w, read 简化为 r, execute 简化为e 等;比如 pipeline 中有 20个核心 bean ,打印日志时可以使用不同的编号替代 bean 全称,如 S1,S2 ,虽然没那么直观,但既可以查问题,又降低了日志量。
一个业务场景涉及很多 bean, 为了复用一些通用逻辑,这些 bean 都继承自某个抽象类。
在抽象类中,定义了执行 bean 前后的一些通用逻辑,如执行前后打印当前 pipeline 中 item 的数量。最后一个 bean 执行完结果转换后需要打印出结果。
1)只打印必要日志
由于当前 bean 执行前 相当于前一个 bean 执行后,因此只打印执行后的日志就可以,执行前的INFO 日志可以删除或者改为 DEBUG (只打印必要日志)
通常问题只出现在执行前后 size 不一致的情况下,因此执行后打印日志前可以加个判断,如果执行前后 size 相同则不打印。(只打印必要日志) 伪代码如下:
if(sizeBefore != sizeAfter){
log.info("service:{ }, 前size:{ },后size:{ }", getName(),sizeBefore, sizeAfter)
}
这招效果很明显,因为大多数 bean 的执行前后 size 是相同的,就不会打印这条日志。而假设之前有 20 个,这条日志就需要打印 20次,改进后可能只需要打印 2-3 次。
2)日志合并
为了方便查问题还需要打印执行前的 size ,那么将执行前的 size 记录在内存中,打印执行后日志时多打印出执行前的 size。(合并打印) 伪代码如下:
log.info("service:{ }, 执行前size:{ }", getName(),sizeBefore)
log.info("service:{ }, 执行后size:{ }", getName(),sizeBefore, sizeAfter)合并后:
log.info("service:{ }, 前size:{ },后size:{ }", getName(),sizeBefore, sizeAfter)3)日志精简
对于最终结果,将结果对象(如 XXDTO)转化为只包括关键信息,如 id, title 的日志对象(XXSimpleLogDTO),转化为日志对象后再打印。
log.info("resultId:{ }",result.getId());或者
log.info("result:{ }",toSimpleLog(result));该日志一天产生 5 G 左右,这里百分之80% 左右都是打印执行前后的 size,10%左右是打印最终结果, 还有一些其他的日志。
经过上述方法优化后,每天日志量不足 1G。

在满足排查问题的需要,又实现日志瘦身之间进行了取舍。
日志瘦身需要进行权衡,保留排查问题的必要日志情况下尽可能精简。
可以采用删除不必要日志,合并日志,日志简化等方式进行优化。
我们还可以进行一些骚操作,支持线上 DEBUG 临时提升 INFO (当然也可以使用 arthas )来辅助我们查问题。
责任编辑:张燕妮 来源: dbaplus社群 日志内存(责任编辑:休闲)
兴胜创建(00896.HK)因行使购股权配发1090.9万股 每股发行价1.16港元
 兴胜创建(00896.HK)发布公告,2021年3月16日,因公司董事根据公司于2011年9月21日采纳的购股权计划行使购股权而发行及配发10,909,000股新股份,每股发行价1.16港元。
...[详细]
兴胜创建(00896.HK)发布公告,2021年3月16日,因公司董事根据公司于2011年9月21日采纳的购股权计划行使购股权而发行及配发10,909,000股新股份,每股发行价1.16港元。
...[详细]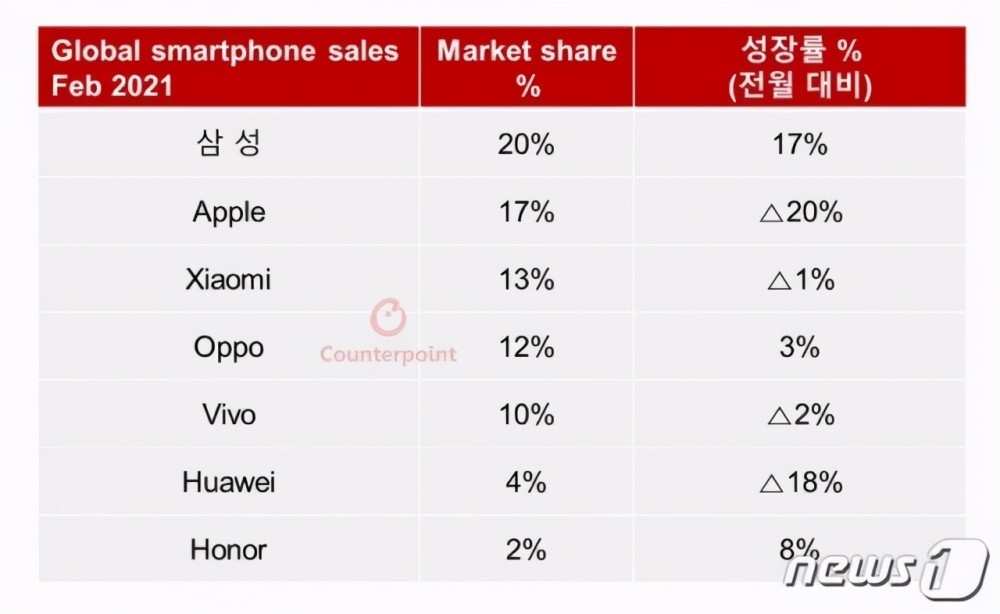 在芯片缺货等背景下,中国市场的智能手机行业发生了怎样的变化?手机厂商的市场份额给出了答案。Counterpoint Research日前发布了2021年2月全球手机份额,排名相比以往有着较大的变化,最
...[详细]
在芯片缺货等背景下,中国市场的智能手机行业发生了怎样的变化?手机厂商的市场份额给出了答案。Counterpoint Research日前发布了2021年2月全球手机份额,排名相比以往有着较大的变化,最
...[详细] AMD RX 6000此前出现大规模故障,德国硬件维修商店KrisFix-Germany收到的61张出故障的RX 6900、RX 6800系列显卡,其中有多达48张彻底无法修复。询问用户得知,出故障的
...[详细]
AMD RX 6000此前出现大规模故障,德国硬件维修商店KrisFix-Germany收到的61张出故障的RX 6900、RX 6800系列显卡,其中有多达48张彻底无法修复。询问用户得知,出故障的
...[详细] 4月20日,由中国电子商务协会指导,中国电子商务协会物流专业委员会主办,中国电商物流产业联盟承办,上海安能聚创供应链管理有限公司协办的“2017第七届中国电子商务与物流协同发展大会暨电商物流技术装备创
...[详细]
4月20日,由中国电子商务协会指导,中国电子商务协会物流专业委员会主办,中国电商物流产业联盟承办,上海安能聚创供应链管理有限公司协办的“2017第七届中国电子商务与物流协同发展大会暨电商物流技术装备创
...[详细]2022年全球人工智能软件市场规模将达625亿美元 相比2021年增长21.3%
 11月30日,据市场机构Gartner预测,2022年全球人工智能(AI)软件收入总额预计将达625亿美元,相比2021年增长21.3%。Gartner认为,2022年人工智能软件支出的前五个用例类别
...[详细]
11月30日,据市场机构Gartner预测,2022年全球人工智能(AI)软件收入总额预计将达625亿美元,相比2021年增长21.3%。Gartner认为,2022年人工智能软件支出的前五个用例类别
...[详细] 近日GDC(游戏开发者大会)发布2023年游戏产业状况调查报告,参与此次调查的游戏开发者有2300名。报告显示许多游戏开发者曾被玩家骚扰,女性或LGBTQ+开发者更是被频繁骚扰。2023年游戏产业状况
...[详细]
近日GDC(游戏开发者大会)发布2023年游戏产业状况调查报告,参与此次调查的游戏开发者有2300名。报告显示许多游戏开发者曾被玩家骚扰,女性或LGBTQ+开发者更是被频繁骚扰。2023年游戏产业状况
...[详细]realme GT Neo评测:联发科旗舰芯 售价不到1800
 前言:当realme官方宣布realme GT Neo这款手机存在的时候,笔者差点以为OPPO和vivo宣布合作了,因为“Neo”这个名称从最早出现到现在,一直都是只有vivo的子品牌iQOO在使用,
...[详细]
前言:当realme官方宣布realme GT Neo这款手机存在的时候,笔者差点以为OPPO和vivo宣布合作了,因为“Neo”这个名称从最早出现到现在,一直都是只有vivo的子品牌iQOO在使用,
...[详细] 从车子到房子,如今分享经济的浪潮正扑面而来,就像1999年的电子商务一样。共享经济的目的是什么?是让用户以更便宜的价格获得社会资源?还是让个人释放闲置资源,并从中获得回报?吴军老师说,这两种对共享经济
...[详细]
从车子到房子,如今分享经济的浪潮正扑面而来,就像1999年的电子商务一样。共享经济的目的是什么?是让用户以更便宜的价格获得社会资源?还是让个人释放闲置资源,并从中获得回报?吴军老师说,这两种对共享经济
...[详细] 4月29日,全球首条日熔化量1200吨的一窑八线光伏玻璃生产线,在安徽桐城成功引板。此产线是由中国建材国际工程集团总承包建设的中国建材桐城新能源材料有限公司太阳能装备用光伏电池封装材料的一期项目。该项
...[详细]
4月29日,全球首条日熔化量1200吨的一窑八线光伏玻璃生产线,在安徽桐城成功引板。此产线是由中国建材国际工程集团总承包建设的中国建材桐城新能源材料有限公司太阳能装备用光伏电池封装材料的一期项目。该项
...[详细] 开发商水晶动力当前正负责开发两款游戏,都以强大女性为主角,分别是《完美黑暗:重启版》和《古墓丽影》新作。自2006年《古墓丽影:传奇》以来,该系列一直由水晶动力负责《古墓丽影:暗影》除外,由Eidos
...[详细]
开发商水晶动力当前正负责开发两款游戏,都以强大女性为主角,分别是《完美黑暗:重启版》和《古墓丽影》新作。自2006年《古墓丽影:传奇》以来,该系列一直由水晶动力负责《古墓丽影:暗影》除外,由Eidos
...[详细] 微众银行贷款怎么样 微众银行微业贷申请条件有哪些?
微众银行贷款怎么样 微众银行微业贷申请条件有哪些? 估值超110亿美元 今日头条真正的焦虑在哪里?
估值超110亿美元 今日头条真正的焦虑在哪里? 《GT赛车7》PSVR2版细节公布 支持网络对战功能
《GT赛车7》PSVR2版细节公布 支持网络对战功能 罗永浩信心满满财报却惨不忍睹 锤子手机还能起死回生吗?
罗永浩信心满满财报却惨不忍睹 锤子手机还能起死回生吗? 办理银行卡需要什么资料 2022年银行卡开户新规是什么?
办理银行卡需要什么资料 2022年银行卡开户新规是什么?
