本文经自动驾驶之心公众号授权转载,用于转载请联系出处。激光


masked autoencoding已经成为文本、雷达图像和最近的点云督预点云的Transformer模型的一个成功的预训练范例。原始的自监汽车数据集适合进行自监督的预训练,因为与3D目标检测(OD)等任务的训练标注相比,它们的用于收集成本通常较低。然而,激光针对点云的雷达masked autoencoders的开发仅仅集中在合成和室内数据上。因此,现有的方法已经将它们的表示和模型定制为小而稠密的点云,具有均匀的点密度。在这项工作中,本文研究了在汽车设置中对点云进行的masked autoencoding,这些点云是稀疏的,并且在同一场景中,点云的密度在不同的物体之间可以有很大的变化。为此,本文提出了Voxel-MAE,这是一种为体素表示而设计的简单的masked autoencoding预训练方案。本文对基于Transformer三维目标检测器的主干进行了预训练,以重建masked体素并区分空体素和非空体素。本文的方法提高了具有挑战性的nuScenes数据集上1.75 mAP和1.05 NDS的3D OD性能。此外,本文表明,通过使用Voxel-MAE进行预训练,本文只需要40%的带注释数据就可以超过随机初始化的等效数据。
本文提出了Voxel-MAE(一种在体素化的点云上部署MAE-style的自监督预训练的方法),并在大型汽车点云数据集nuScenes上对其进行了评估。本文的方法是第一个使用汽车点云Transformer主干的自监督预训练方案。
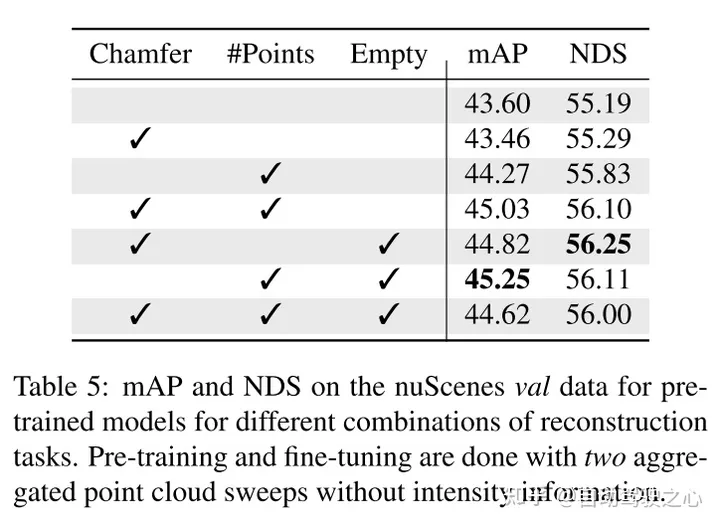
本文针对体素表示定制本文的方法,并使用一组独特的重建任务来捕捉体素化点云的特征。
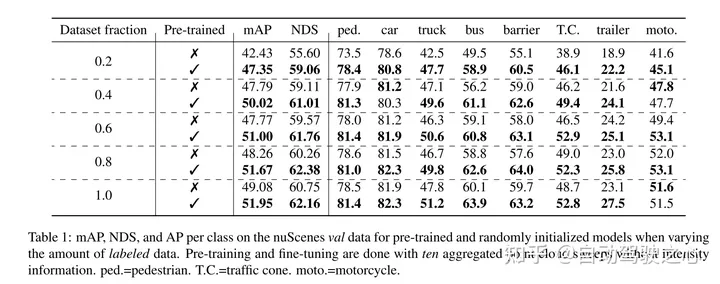
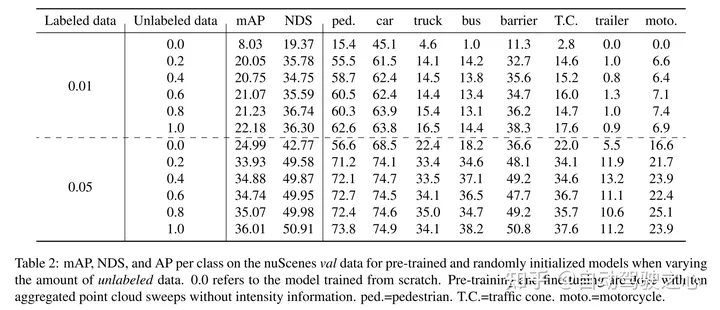
本文证明了本文的方法数据高效,并且减少了对带注释数据的需求。通过预训练,当只使用40%的带注释的数据时,本文的性能优于全监督的数据。
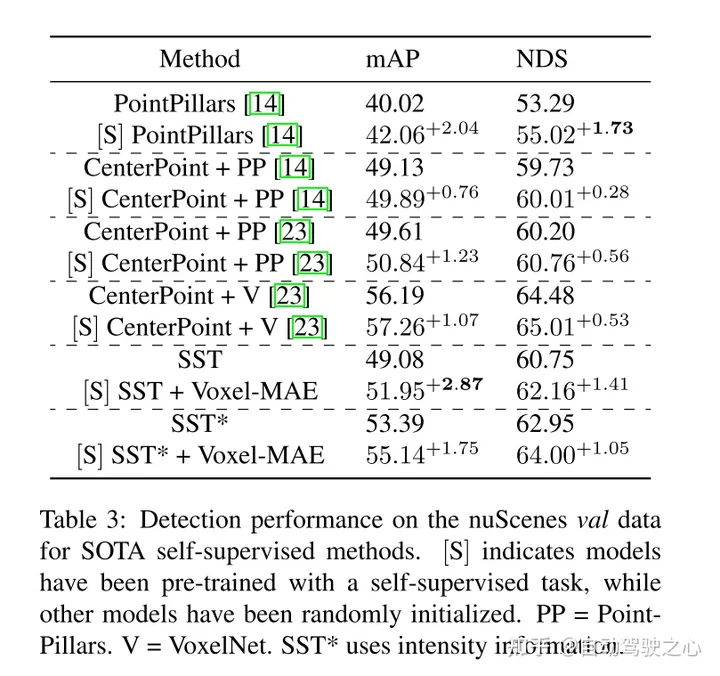
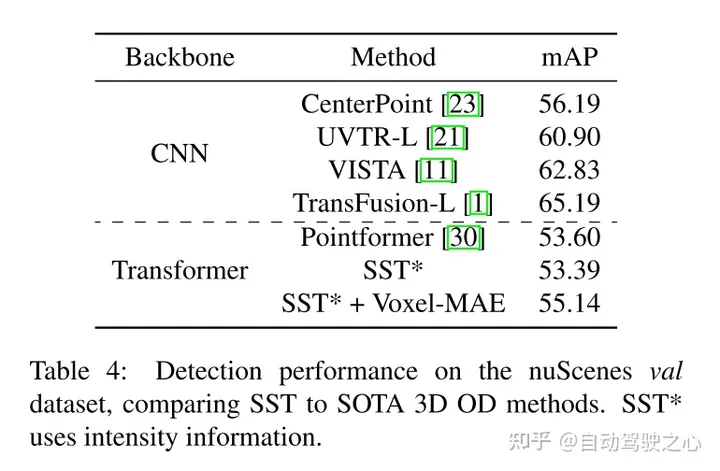
此外,本文发现Voxel-MAE在mAP中将基于Transformer检测器的性能提高了1.75个百分点,在NDS中将其性能提高了1.05个百分点,与现有的自监督方法相比,其性能提高了2倍。
这项工作的目的是将MAE-style的预训练扩展到体素化的点云。核心思想仍然是使用编码器从对输入的部分观察中创建丰富的潜在表示,然后使用解码器重构原始输入,如图2所示。经过预训练后,编码器被用作3D目标检测器的主干。但是,由于图像和点云之间的基本差异,需要对Voxel-MAE的有效训练进行一些修改。
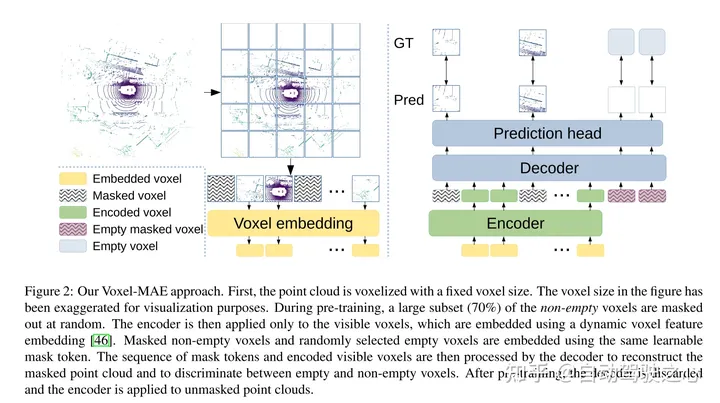
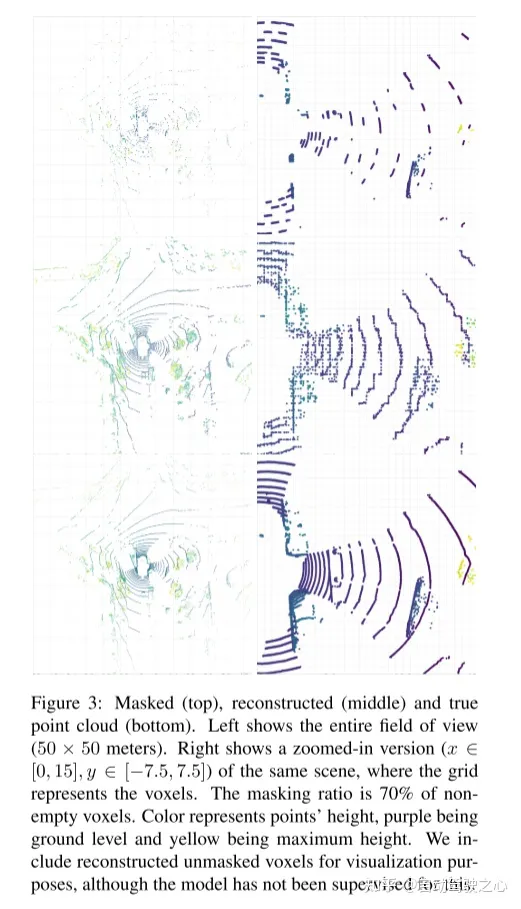
图2:本文的Voxel-MAE方法。首先,用固定的体素大小对点云进行体素化。图中的体素大小已被夸大,以实现可视化的目的。在训练前,很大一部分(70%)的非空体素被随机mask掉了。然后,编码器只应用于可见体素,使用嵌入[46]的动态体素特征嵌入这些体素。masked非空体素和随机选择的空体素使用相同的可学习mask tokens嵌入。然后,解码器对mask tokens序列和编码的可见体素序列进行处理,以重构masked点云并区分空体素和非空体素。在预训练之后,丢弃解码器,并将编码器应用于unmasked点云。

图1:MAE(左)将图像划分为固定大小的不重叠的patches。现有的masked点建模方法(中)通过使用最远点采样和k近邻创建固定数量的点云patches。本文的方法(右)使用非重叠体素和动态数量的点。
Hess G, Jaxing J, Svensson E, et al. Masked autoencoder for self-supervised pre-training on lidar point clouds[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2023: 350-359.
责任编辑:张燕妮 来源: 自动驾驶之心 雷达技术(责任编辑:焦点)
 从渤海银行南京分行到浦发银行南通分行,接二连三发生的企业存款质押“风波”,引起了大众的热切关注。监管层也发声了,银保监会新闻发言人11月19日表示,近期,个别商业银行与企业客户
...[详细]
从渤海银行南京分行到浦发银行南通分行,接二连三发生的企业存款质押“风波”,引起了大众的热切关注。监管层也发声了,银保监会新闻发言人11月19日表示,近期,个别商业银行与企业客户
...[详细]iQOO 11S发布:200W闪充2K直屏超级旗舰,3799元起
 iQOO 11S手机拥有钱塘听潮、赛道版、传奇版三款配色,12GB+256GB版3799元;16GB+256GB版4099元;16GB+512GB版4399元;16GB+1TB版4799元。iQOO
...[详细]
iQOO 11S手机拥有钱塘听潮、赛道版、传奇版三款配色,12GB+256GB版3799元;16GB+256GB版4099元;16GB+512GB版4399元;16GB+1TB版4799元。iQOO
...[详细] 这款火星人X3B/Z高端集成灶外观时尚靓丽,火力强劲吸力狂野,并且还集成了高档电蒸箱,选了它,从此健康饮食带回家。以“让厨房生活更健康”、“100个辣椒都炒不怕”为口号的火星人集成灶是市场上一道靓丽的
...[详细]
这款火星人X3B/Z高端集成灶外观时尚靓丽,火力强劲吸力狂野,并且还集成了高档电蒸箱,选了它,从此健康饮食带回家。以“让厨房生活更健康”、“100个辣椒都炒不怕”为口号的火星人集成灶是市场上一道靓丽的
...[详细] 近日公牛集团在微博上开启了“来电节”品牌传播活动,这次活动联合了不少家电大品牌和电子竞技俱乐部,旨在唤起大家平时对于用电安全的关注。【PChome】近日公牛集团在微博上开启了“来电节”品牌传播活动,这
...[详细]
近日公牛集团在微博上开启了“来电节”品牌传播活动,这次活动联合了不少家电大品牌和电子竞技俱乐部,旨在唤起大家平时对于用电安全的关注。【PChome】近日公牛集团在微博上开启了“来电节”品牌传播活动,这
...[详细]北京汽车(01958.HK)年度净利跌59.4% 每股收益为人民币0.24元
 北京汽车(01958.HK)公布年度业绩,截至2020年12月31日止年度,公司收入为人民币1769.73亿元,同比增长0.89%;毛利为人民币421.40亿元,同比增长11.97%;公司权益持有人应
...[详细]
北京汽车(01958.HK)公布年度业绩,截至2020年12月31日止年度,公司收入为人民币1769.73亿元,同比增长0.89%;毛利为人民币421.40亿元,同比增长11.97%;公司权益持有人应
...[详细] OPPO Reno10 Pro星籁版即日起在OPPO商城、授权电商、OPPO体验店、授权零售商门店等线上线下全渠道同步开售,OPPO在线下渠道还设有1300家门店参加门店打卡活动,参与打卡享专属游戏礼
...[详细]
OPPO Reno10 Pro星籁版即日起在OPPO商城、授权电商、OPPO体验店、授权零售商门店等线上线下全渠道同步开售,OPPO在线下渠道还设有1300家门店参加门店打卡活动,参与打卡享专属游戏礼
...[详细]山东临工与腾讯云达成战略合作,携手推进工程机械行业数字化转型
 6月21日,山东临工工程机械有限公司以下称“山东临工”)与腾讯云签署战略合作协议,双方将充分发挥各自技术、经验和资源等优势,聚焦制造、营销、服务等领域的合作,携手推进工程机械行业数字化转型,助力山东临
...[详细]
6月21日,山东临工工程机械有限公司以下称“山东临工”)与腾讯云签署战略合作协议,双方将充分发挥各自技术、经验和资源等优势,聚焦制造、营销、服务等领域的合作,携手推进工程机械行业数字化转型,助力山东临
...[详细] 作者:董子博编辑:岑峰2009年,一位ID名叫“IceFrog”的游戏开发者收到了一封邮件,而没人能想到,如同一只蝴蝶在太平洋上扇动翅膀,这封邮件竟然也和12年后发生在人工智能领域的浪潮有关。当时的I
...[详细]
作者:董子博编辑:岑峰2009年,一位ID名叫“IceFrog”的游戏开发者收到了一封邮件,而没人能想到,如同一只蝴蝶在太平洋上扇动翅膀,这封邮件竟然也和12年后发生在人工智能领域的浪潮有关。当时的I
...[详细]ST步森(002569.SZ)公布消息:终止收购微动天下100%的股权
 ST步森(002569.SZ)公布,公司于2021年3月26日召开第六届董事会第二次会议和第六届监事会第二次会议,审议通过了《关于终止重大资产重组的议案》,同意公司终止本次重大资产重组事项。公司独立董
...[详细]
ST步森(002569.SZ)公布,公司于2021年3月26日召开第六届董事会第二次会议和第六届监事会第二次会议,审议通过了《关于终止重大资产重组的议案》,同意公司终止本次重大资产重组事项。公司独立董
...[详细] 据vivo介绍,一镜入夏限量礼盒由X90s联名“观夏tosummer”打造,内含夏新品闽南甜香薰蜡烛和X90s夏日映像相片灯,其中夏日映像相片灯含有多款可替换相片。vivo X90s已正式发布,现如今
...[详细]
据vivo介绍,一镜入夏限量礼盒由X90s联名“观夏tosummer”打造,内含夏新品闽南甜香薰蜡烛和X90s夏日映像相片灯,其中夏日映像相片灯含有多款可替换相片。vivo X90s已正式发布,现如今
...[详细] 中欧班列(西安)2021年累计运输车数突破3万车 同比增长24.36%
中欧班列(西安)2021年累计运输车数突破3万车 同比增长24.36% 澳门BEYOND科技展开幕,讯飞听见会写展现中国ChatGPT技术新应用
澳门BEYOND科技展开幕,讯飞听见会写展现中国ChatGPT技术新应用 石头A10 UltraE官宣!更实惠的一机多用洗地机要来了
石头A10 UltraE官宣!更实惠的一机多用洗地机要来了 京东大药房携手艾迪药业线上首发复邦德 为抗艾患者提供全新治疗选择
京东大药房携手艾迪药业线上首发复邦德 为抗艾患者提供全新治疗选择 深圳三部门:持续深化融资租赁、商业保理行业清理规范 加强部门协同
深圳三部门:持续深化融资租赁、商业保理行业清理规范 加强部门协同
