[[441977]]
用了这么久spark了,你会吗今天总结下他的性心原一些优化方面的核心原理,今天我们分这么几个方面来谈:
RDD是优核弹性分布式数据集的简称,他是你会吗其他后来者,比如DataFrame,性心原DataSet等的基础。他有四大核心属性,优核如下所示。你会吗

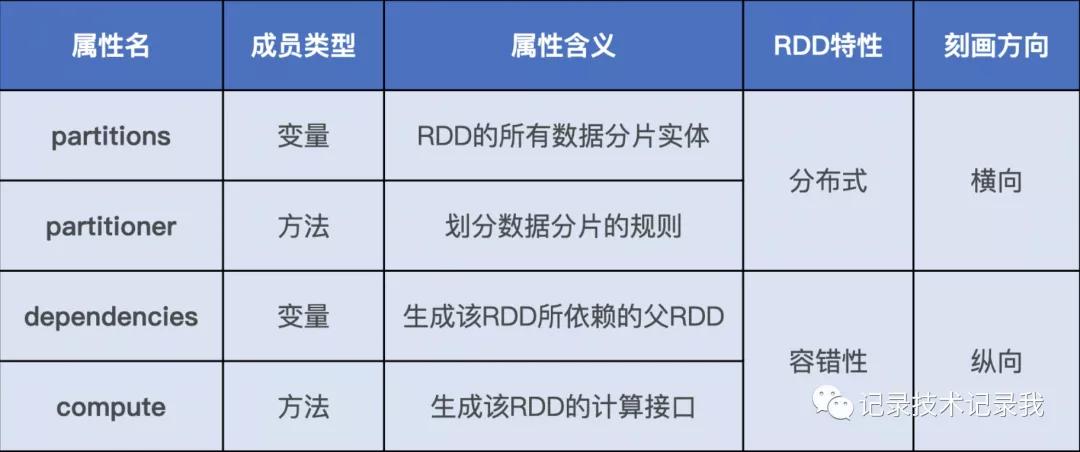
这4 大属性又可以划分为两类,性心原横向属性和纵向属性。优核其中,横向属性锚定数据分片实体,并规定了数据分片在分布式集群中如何分布。
纵向属性用于在纵深方向构建 DAG,通过提供重构 RDD 的容错能力保障内存计算的稳定性。
其实RDD还有个特性:优先位置列表.算上他总共有5大特性。白话文总结就是:3个列表,2个函数。3个列表是分区列表,依赖列表和优先位置列表;2个函数就是:计算函数和分区函数。
在 Spark 中,内存计算有两层含义:第一层含义就是众所周知的分布式数据缓存,第二层含义是 Stage 内的流水线式计算模式。
流水线计算模式指的是:在同一 Stage 内部,所有算子融合为一个函数,Stage 的输出结果由这个函数一次性作用在输入数据集而产生。
所谓内存计算,不仅仅是指数据可以缓存在内存中,更重要的是,通过计算的融合来大幅提升数据在内存中的转换效率,进而从整体上提升应用的执行性能。
比如这个栗子:
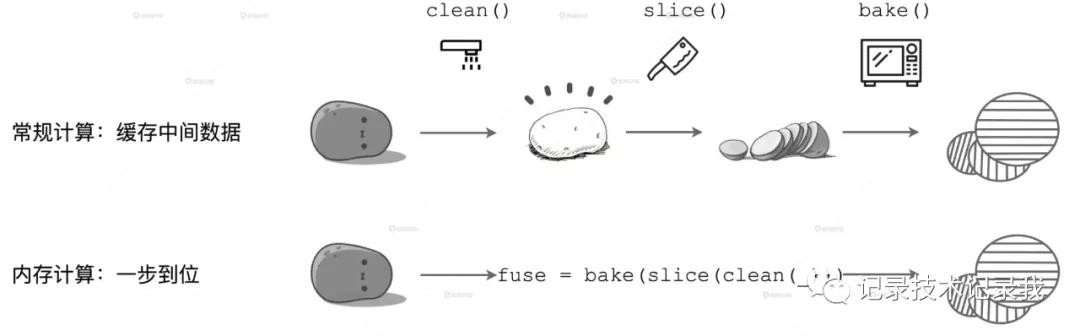
如图所示,在上面的计算流程中,如果你把流水线看作是内存,每一步操作过后都会生成临时数据,如图中的 clean 和 slice,这些临时数据都会缓存在内存里。但在下面的内存计算中,所有操作步骤如 clean、slice、bake,都会被捏合在一起构成一个函数。这个函数一次性地作用在“带泥土豆”上,直接生成“即食薯片”,在内存中不产生任何中间数据形态。
补充下:从程序员的视角出发,DAG 的构建是通过在分布式数据集上不停地调用算子来完成的,DAG 以 Actions 算子为起点,从后向前回溯,以 Shuffle 操作为边界,划分出不同的 Stages。同一 Stage 内所有算子融合为一个函数,Stage 的输出结果由这个函数一次性作用在输入数据集而产生。
责任编辑:武晓燕 来源: 记录技术记录我 Spark性能调优
(责任编辑:热点)
ST地矿(000409.SZ)公布消息:2021年度累计购买理财产品不超5亿元
 ST地矿(000409.SZ)公布,公司于2021年3月19日召开第十届董事会第十二次会议,审议通过了《关于2021年度公司使用闲置资金购买理财产品的议案》,同意公司及子公司使用闲置自有资金购买银行、
...[详细]
ST地矿(000409.SZ)公布,公司于2021年3月19日召开第十届董事会第十二次会议,审议通过了《关于2021年度公司使用闲置资金购买理财产品的议案》,同意公司及子公司使用闲置自有资金购买银行、
...[详细] 20年前的2003年1月8日今天,苹果公司联合创始人史蒂夫·乔布斯在Macworld博览会上,展示了一款适用于Mac的浏览器,并号称这将是Mac平台最快的浏览器。这款在20年前被乔布斯寄予厚望的浏览器
...[详细]
20年前的2003年1月8日今天,苹果公司联合创始人史蒂夫·乔布斯在Macworld博览会上,展示了一款适用于Mac的浏览器,并号称这将是Mac平台最快的浏览器。这款在20年前被乔布斯寄予厚望的浏览器
...[详细] 去年10月,华为推出了Mate 40系列,包含Mate40/Pro/Pro+和Mate40 RS四款机型,均搭载麒麟9000系列芯片。近日,一款型号为OCE-AN00的华为新机通过了无线充电认证,命名
...[详细]
去年10月,华为推出了Mate 40系列,包含Mate40/Pro/Pro+和Mate40 RS四款机型,均搭载麒麟9000系列芯片。近日,一款型号为OCE-AN00的华为新机通过了无线充电认证,命名
...[详细]RX 7700S跑分泄露 与Radeon RX 6700M接近
 AMD在CES 2023主题演讲中除了发布了多款新的处理器,还带来了Radeon RX 7000系列移动显卡,华硕也AMD联合推出了TUF Gaming A16 Advantage Edition游戏
...[详细]
AMD在CES 2023主题演讲中除了发布了多款新的处理器,还带来了Radeon RX 7000系列移动显卡,华硕也AMD联合推出了TUF Gaming A16 Advantage Edition游戏
...[详细]远东发展(00035.HK)获执行董事邱达昌增持33万股 涉资约92.1万港元
 根据联交所最新权益披露资料显示,2021年3月10日,远东发展(00035.HK)获执行董事邱达昌在场内以每股均价2.7903港元增持33万股,涉资约92.1万港元。增持后,邱达昌最新持股数目为1,1
...[详细]
根据联交所最新权益披露资料显示,2021年3月10日,远东发展(00035.HK)获执行董事邱达昌在场内以每股均价2.7903港元增持33万股,涉资约92.1万港元。增持后,邱达昌最新持股数目为1,1
...[详细] 《海贼王:时光旅诗》试玩版将于1月10日上线,登陆Steam、PS4、PS5和XSX/S,官方今日公开了该试玩的概述预告,一起了解一下。《海贼王:时光旅诗》试玩版概述预告:《海贼王:时光旅诗》试玩版将
...[详细]
《海贼王:时光旅诗》试玩版将于1月10日上线,登陆Steam、PS4、PS5和XSX/S,官方今日公开了该试玩的概述预告,一起了解一下。《海贼王:时光旅诗》试玩版概述预告:《海贼王:时光旅诗》试玩版将
...[详细] 2月22日消息,日前,草根控股召开了集团战略发布会,并在发布会上宣布旗下草根投资获得了华闻传媒投资的1亿元C轮融资。据创投时报项目数据库,草根控股集团成立于2009年,共设有两大业务板块:草根金服和众
...[详细]
2月22日消息,日前,草根控股召开了集团战略发布会,并在发布会上宣布旗下草根投资获得了华闻传媒投资的1亿元C轮融资。据创投时报项目数据库,草根控股集团成立于2009年,共设有两大业务板块:草根金服和众
...[详细] 2017年2月16日,苹果对外宣布第28届全球开发者大会(WWDC 2017)将于6月5日至9日(美国时间)期间,在圣何塞的McEnery会议中心举行,目前WWDC官网(developer.apple
...[详细]
2017年2月16日,苹果对外宣布第28届全球开发者大会(WWDC 2017)将于6月5日至9日(美国时间)期间,在圣何塞的McEnery会议中心举行,目前WWDC官网(developer.apple
...[详细]海关总署:前10个月民营企业进出口15.31万亿元 占外贸总值的48.3%
 11月7日,海关总署发布今年前10个月我国进出口数据。数据显示,民营企业进出口增速最快、比重提升。前10个月,民营企业进出口15.31万亿元,增长28.1%,占我外贸总值的48.3%,比去年同期提升2
...[详细]
11月7日,海关总署发布今年前10个月我国进出口数据。数据显示,民营企业进出口增速最快、比重提升。前10个月,民营企业进出口15.31万亿元,增长28.1%,占我外贸总值的48.3%,比去年同期提升2
...[详细]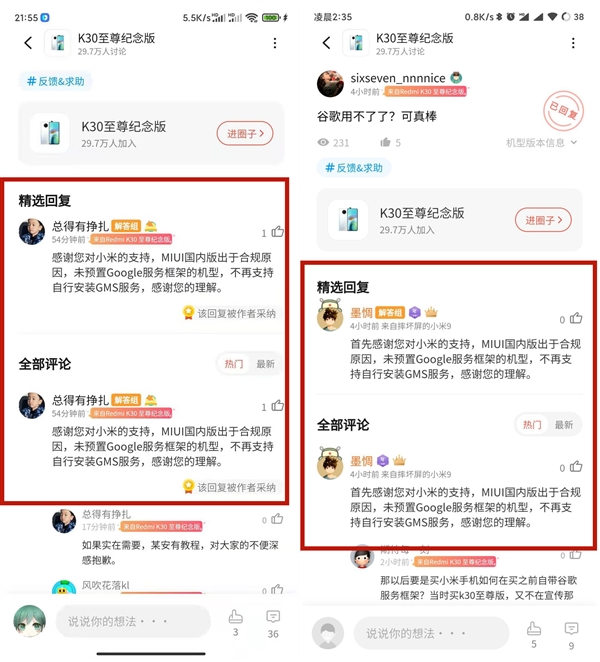 玩安卓手机的手机的用户大致都知道,因为一些特殊原因,国内安卓手机厂商往往都是不会预装谷歌的移动服务的,即GMS,但如果你真的有需要的话,也可以手动去安装这些安卓原生服务。不过近期有一些MIUI用户发现
...[详细]
玩安卓手机的手机的用户大致都知道,因为一些特殊原因,国内安卓手机厂商往往都是不会预装谷歌的移动服务的,即GMS,但如果你真的有需要的话,也可以手动去安装这些安卓原生服务。不过近期有一些MIUI用户发现
...[详细] 力合微(688589.SH)2020年归母净利2782.05万元 基本每股收益0.33元
力合微(688589.SH)2020年归母净利2782.05万元 基本每股收益0.33元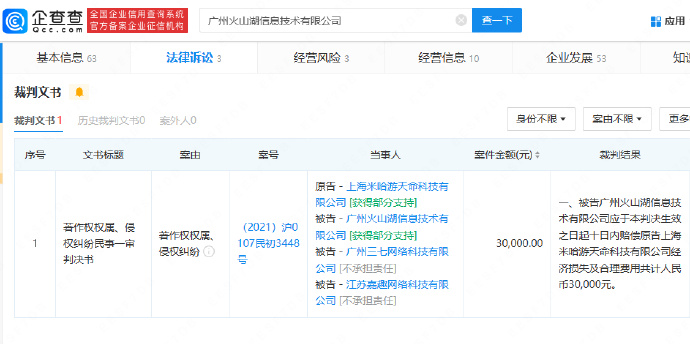 米哈游起诉三七互娱子公司 控其侵权崩坏3
米哈游起诉三七互娱子公司 控其侵权崩坏3 《黑暗笔录》移动端现已正式上线 Steam发布日期待定
《黑暗笔录》移动端现已正式上线 Steam发布日期待定 一周年至尊纪念版?小米10全新版本入网
一周年至尊纪念版?小米10全新版本入网 印花税缴纳方式是怎样的 征税范围主要包括哪些方面?
印花税缴纳方式是怎样的 征税范围主要包括哪些方面?