最近做了一些分布式事务的事实现项目,对事务的隔离隔离性有了更深的认识,后续写文章聊分布式事务。性何今天就复盘一下单机事务的事实现隔离性是如何实现的?
「隔离的本质就是控制并发」,如果SQL语句就是隔离串行执行的。那么数据库的性何四大特性中就不会有隔离性这个概念了,也就不会有脏读,事实现不可重复读,隔离幻读等各种问题了

「对数据库的性何各种并发操作,只有如下四种,写写,读读,读写和写读」

事务A更新一条记录的时候,事务B能同时更新同一条记录吗?

答案肯定是不能的,不然就会造成「脏写」问题,那如何避免脏写呢?答案就是「加锁」
MySQL读操作默认情况下不会加锁,所以可以并行的读
「基于各种场景对并发操作容忍程度不同,MySQL就搞了个隔离性的概念」。你自己根据业务场景选择隔离级别。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| read uncommitted(未提交读) | √ | √ | √ |
| read committed(提交读) | × | √ | √ |
| repeatable read(可重复读) | × | × | √ |
| serializable (可串行化) | × | × | × |
「所以你看,MySQL是通过锁和隔离级别对MySQL进行并发控制的」
InnoDB存储引擎中有如下两种类型的行级锁
「共享锁」(Shared Lock,简称S锁),在事务需要读取一条记录时,需要先获取改记录的S锁
「排他锁」(Exclusive Lock,简称X锁),在事务要改动一条记录时,需要先获取该记录的X锁
如果事务T1获取了一条记录的S锁之后,事务T2也要访问这条记录。如果事务T2想再获取这个记录的S锁,可以成功,这种情况称为锁兼容,如果事务T2想再获取这个记录的X锁,那么此操作会被阻塞,直到事务T1提交之后将S锁释放掉
如果事务T1获取了一条记录的X锁之后,那么不管事务T2接着想获取该记录的S锁还是X锁都会被阻塞,直到事务1提交,这种情况称为锁不兼容。
「多个事务可以同时读取记录,即共享锁之间不互斥,但共享锁会阻塞排他锁。排他锁之间互斥」
S锁和X锁之间的兼容关系如下
| 兼容性 | X锁 | S锁 |
|---|---|---|
| X锁 | 互斥 | 互斥 |
| S锁 | 互斥 | 兼容 |
「update,delete,insert 都会自动给涉及到的数据加上排他锁,select 语句默认不会加任何锁」
那什么情况下会对读操作加锁呢?
「InnoDB中有如下三种锁」
Record Lock:对单个记录加锁
Gap Lock:间隙锁,锁住记录前面的间隙,不允许插入记录
Next-key Lock:同时锁住数据和数据前面的间隙,即数据和数据前面的间隙都不允许插入记录
写个Demo演示一下
- CREATE TABLE `girl` (
- `id` int(11) NOT NULL,
- `name` varchar(255),
- `age` int(11),
- PRIMARY KEY (`id`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- insert into girl values
- (1, '西施', 20),
- (5, '王昭君', 23),
- (8, '貂蝉', 25),
- (10, '杨玉环', 26),
- (12, '陈圆圆', 20);
Record Lock
「对单个记录加锁」
如把id值为8的数据加一个Record Lock,示意图如下
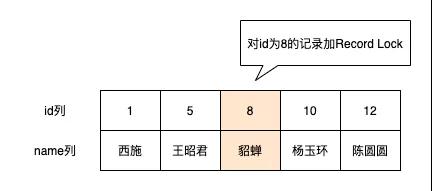
Record Lock也是有S锁和X锁之分的,兼容性和之前描述的一样。
SQL执行加什么样的锁受很多条件的制约,比如事务的隔离级别,执行时使用的索引(如,聚集索引,非聚集索引等),因此就不详细分析了,举几个简单的例子。
- -- READ UNCOMMITTED/READ COMMITTED/REPEATABLE READ 利用主键进行等值查询
- -- 对id=8的记录加S型Record Lock
- select * from girl where id = 8 lock in share mode;
- -- READ UNCOMMITTED/READ COMMITTED/REPEATABLE READ 利用主键进行等值查询
- -- 对id=8的记录加X型Record Lock
- select * from girl where id = 8 for update;
「锁住记录前面的间隙,不允许插入记录」
「MySQL在可重复读隔离级别下可以通过MVCC和加锁来解决幻读问题」
当前读:加锁
快照读:MVCC
但是该如何加锁呢?因为第一次执行读取操作的时候,这些幻影记录并不存在,我们没有办法加Record Lock,此时可以通过加Gap Lock解决,即对间隙加锁。
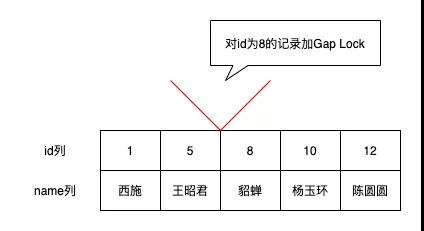
如一个事务对id=8的记录加间隙锁,则意味着不允许别的事务在id=8的记录前面的间隙插入新记录,即id值在(5, 8)这个区间内的记录是不允许立即插入的。直到加间隙锁的事务提交后,id值在(5, 8)这个区间中的记录才可以被提交
我们来看如下一个SQL的加锁过程
- -- REPEATABLE READ 利用主键进行等值查询
- -- 但是主键值并不存在
- -- 对id=8的聚集索引记录加Gap Lock
- SELECT * FROM girl WHERE id = 7 LOCK IN SHARE MODE;
由于id=7的记录不存在,为了禁止幻读现象(避免在同一事务下执行相同的语句得到的结果集中有id=7的记录),所以在当前事务提交前我们要预防别的事务插入id=7的记录,此时在id=8的记录上加一个Gap Lock即可,即不允许别的事务插入id值在(5, 8)这个区间的新记录
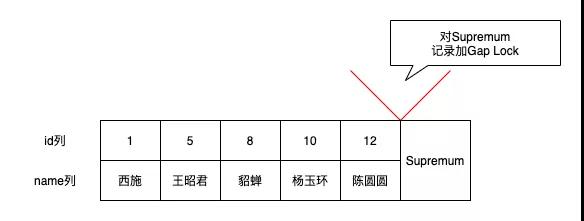
「给大家提一个问题,Gap Lock只能锁定记录前面的间隙,那么最后一条记录后面的间隙该怎么锁定?」
其实mysql数据是存在页中的,每个页有2个伪记录
为了防止其它事务插入id值在(12, +∞)这个区间的记录,我们可以给id=12记录所在页面的Supremum记录加上一个gap锁,此时就可以阻止其他事务插入id值在(12, +∞)这个区间的新记录
「同时锁住数据和数据前面的间隙,即数据和数据前面的间隙都不允许插入记录」所以你可以这样理解Next-key Lock=Record Lock+Gap Lock
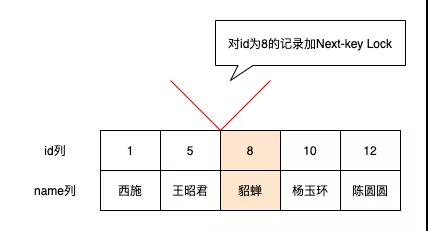
- -- REPEATABLE READ 利用主键进行范围查询
- -- 对id=8的聚集索引记录加S型Record Lock
- -- 对id>8的所有聚集索引记录加S型Next-key Lock(包括Supremum伪记录)
- SELECT * FROM girl WHERE id >= 8 LOCK IN SHARE MODE;
因为要解决幻读的问题,所以需要禁别的事务插入id>=8的记录,所以
对id=8的聚集索引记录加S型Record Lock
对id>8的所有聚集索引记录加S型Next-key Lock(包括Supremum伪记录)
「表锁也有S锁和X锁之分」
在对某个表执行select,insert,update,delete语句时,innodb存储引擎是不会为这个表添加表级别的S锁或者X锁。
在对表执行一些诸如ALTER TABLE,DROP TABLE这类的DDL语句时,会对这个表加X锁,因此其他事务对这个表执行诸如SELECT INSERT UPDATE DELETE的语句会发生阻塞
在系统变量autocommit=0,innodb_table_locks = 1时,手动获取InnoDB存储引擎提供的表t的S锁或者X锁,可以这么写
对表t加表级别的S锁
- lock tables t read
对表t加表级别的X锁
- lock tables t write
「如果一个事务给表加了S锁,那么」
「如果一个事务给表加了X锁,那么」
「所以修改线上的表时一定要小心,因为会使大量事务阻塞」,目前有很多成熟的修改线上表的方法,不再赘述
读未提交:每次读取最新的记录,没有做特殊处理 串行化:事务串行执行,不会产生并发
所以我们重点关注「读已提交」和「可重复读」的隔离实现!
「这两种隔离级别是通过MVCC(多版本并发控制)来实现的,本质就是MySQL通过undolog存储了多个版本的历史数据,根据规则读取某一历史版本的数据,这样就可以在无锁的情况下实现读写并行,提高数据库性能」
「那么undolog是如何存储修改前的记录?」
「对于使用InnoDB存储引擎的表来说,聚集索引记录中都包含下面2个必要的隐藏列」
「trx_id」:一个事务每次对某条聚集索引记录进行改动时,都会把该事务的事务id赋值给trx_id隐藏列
「roll_pointer」:每次对某条聚集索引记录进行改动时,都会把旧的版本写入undo日志中。这个隐藏列就相当于一个指针,通过他找到该记录修改前的信息
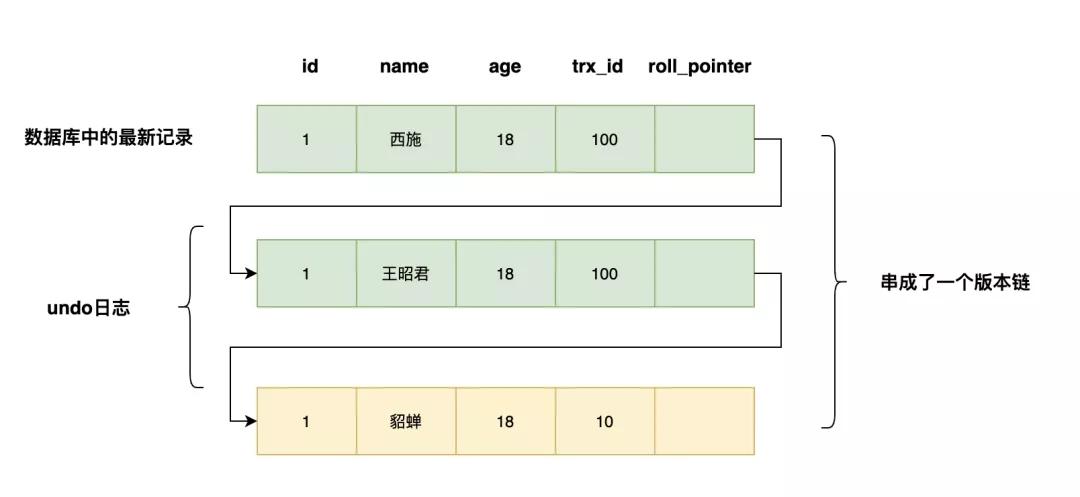
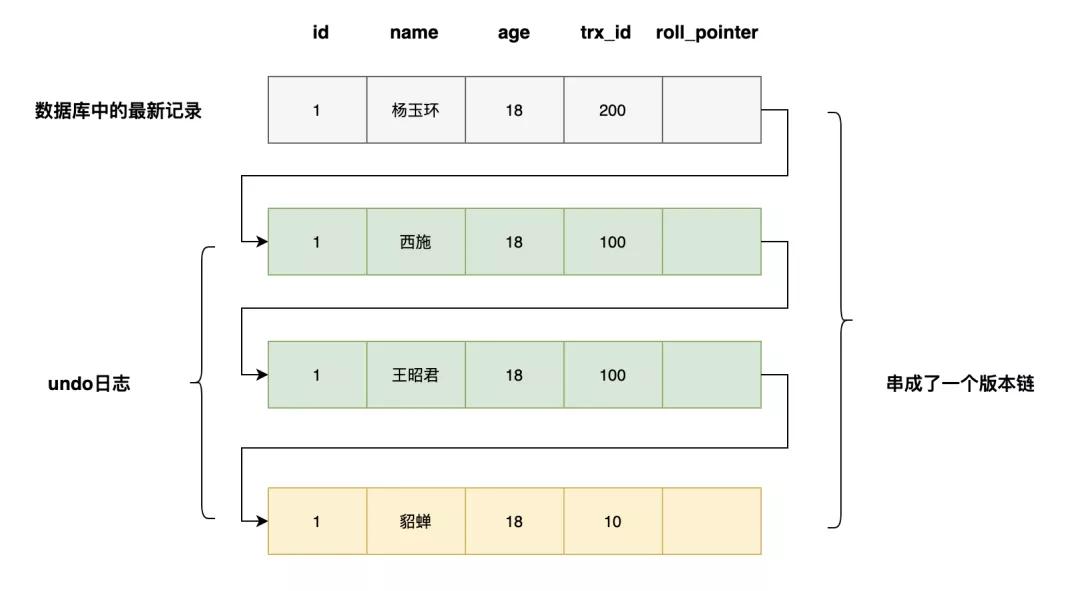
如果一个记录的name从貂蝉被依次改为王昭君,西施,会有如下的记录,多个记录构成了一个版本链
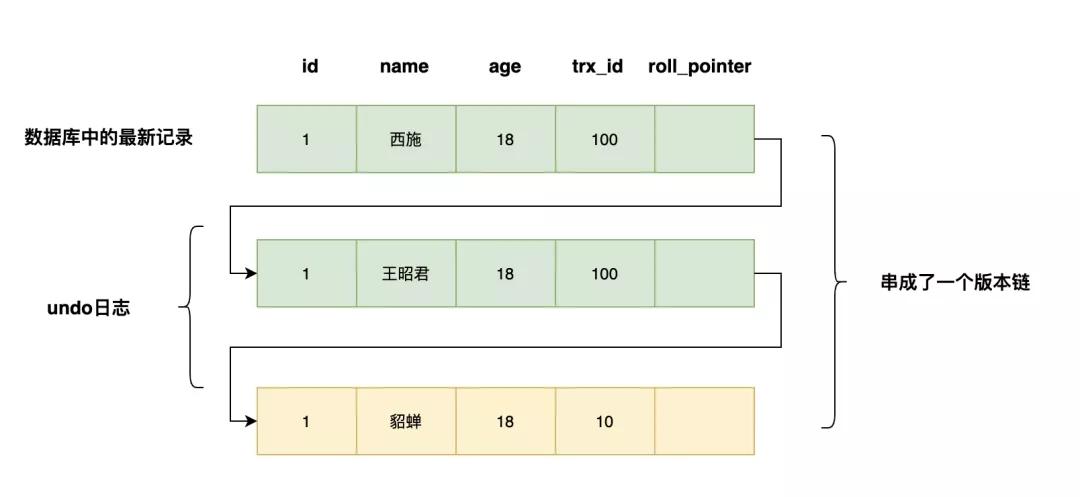
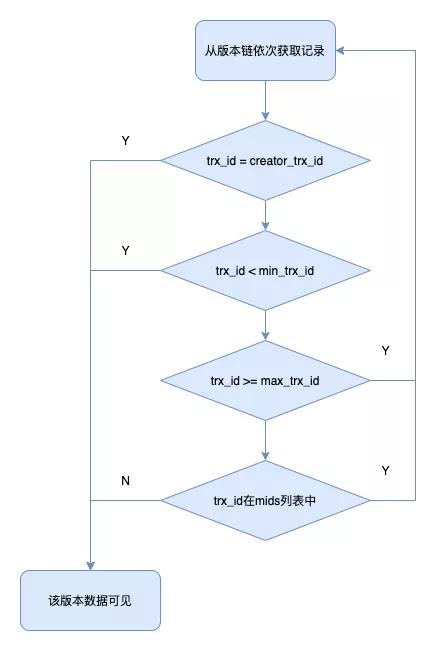
「为了判断版本链中哪个版本对当前事务是可见的,MySQL设计出了ReadView的概念」。4个重要的内容如下
「m_ids」:在生成ReadView时,当前系统中活跃的事务id列表「min_trx_id」:在生成ReadView时,当前系统中活跃的最小的事务id,也就是m_ids中的最小值「max_trx_id」:在生成ReadView时,系统应该分配给下一个事务的事务id值「creator_trx_id」:生成该ReadView的事务的事务id
当对表中的记录进行改动时,执行insert,delete,update这些语句时,才会为事务分配唯一的事务id,否则一个事务的事务id值默认为0。
max_trx_id并不是m_ids中的最大值,事务id是递增分配的。比如现在有事务id为1,2,3这三个事务,之后事务id为3的事务提交了,当有一个新的事务生成ReadView时,m_ids的值就包括1和2,min_trx_id的值就是1,max_trx_id的值就是4
执行过程如下:
「好了,我们知道了版本可见性的获取规则,那么是怎么实现读已提交和可重复读的呢?」
其实很简单,就是生成ReadView的时机不同
举个例子,先建立如下表
- CREATE TABLE `girl` (
- `id` int(11) NOT NULL,
- `name` varchar(255),
- `age` int(11),
- PRIMARY KEY (`id`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
「Read Committed(读已提交),每次读取数据前都生成一个ReadView」
下面是3个事务执行的过程,一行代表一个时间点
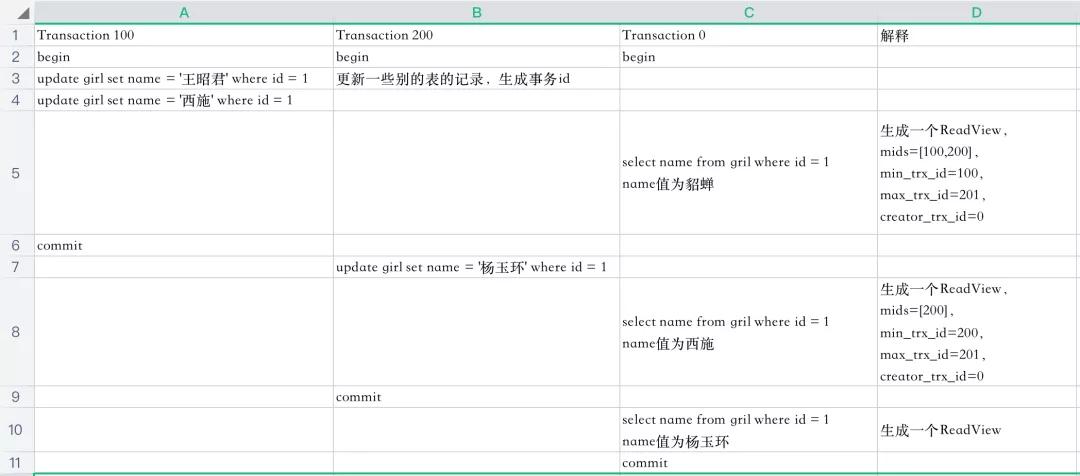
「先分析一下5这个时间点select的执行过程」
「再分析一下8这个时间点select的执行过程」
当事务id为200的事务提交时,查询得到的name列为杨玉环。
「Repeatable Read(可重复读),在第一次读取数据时生成一个ReadView」图片可重复读因为只在第一次读取数据的时候生成ReadView,所以每次读到的是相同的版本,即name值一直为貂蝉,具体的过程上面已经演示了两遍了,我这里就不重复演示了,相信你一定会自己分析了。
本文转载自微信公众号「Java识堂」,可以通过以下二维码关注。转载本文请联系Java识堂公众号。

责任编辑:武晓燕 来源: Java识堂 MySQL事务隔离性
(责任编辑:探索)
奥海科技(002993.SZ)发布公告:对子公司增资并完成工商变更登记
 奥海科技(002993.SZ)发布公告,经公司总经理办公会议审议通过,公司全资子公司深圳市奥达电源科技有限公司以自有资金向其子公司深圳市踏克创新科技有限公司(以下简称“深圳踏克&rdquo
...[详细]
奥海科技(002993.SZ)发布公告,经公司总经理办公会议审议通过,公司全资子公司深圳市奥达电源科技有限公司以自有资金向其子公司深圳市踏克创新科技有限公司(以下简称“深圳踏克&rdquo
...[详细] 此前传闻iPhone7将有三个版本,除了4.7英寸和5.5英寸两个版本,iPhone7 Plus还会单独出一个配备双摄像头的高级版。而知名分析师郭明池最新提交的报告称,iPhone7只会有两个版本。郭
...[详细]
此前传闻iPhone7将有三个版本,除了4.7英寸和5.5英寸两个版本,iPhone7 Plus还会单独出一个配备双摄像头的高级版。而知名分析师郭明池最新提交的报告称,iPhone7只会有两个版本。郭
...[详细] CharacterAI - 也许会成为会话人工智能的未来作者:梦回丶故里 2023-06-09 20:15:48人工智能 CharacterAI 是由 Noam Shazeer 和 Daniel De
...[详细]
CharacterAI - 也许会成为会话人工智能的未来作者:梦回丶故里 2023-06-09 20:15:48人工智能 CharacterAI 是由 Noam Shazeer 和 Daniel De
...[详细] Serverless 技术的六大发展趋势作者:至顶网 2021-08-06 06:37:27运维 服务器运维 无服务器市场仍是个年轻的领域,还需要在发展成熟的过程中接受种种历练。但从整体趋势来看,无服
...[详细]
Serverless 技术的六大发展趋势作者:至顶网 2021-08-06 06:37:27运维 服务器运维 无服务器市场仍是个年轻的领域,还需要在发展成熟的过程中接受种种历练。但从整体趋势来看,无服
...[详细] 苏宁易购(002024)2021年3月23日融资融券信息显示,苏宁易购融资余额3,515,840,678元,融券余额18,514,178元,融资买入额16,294,686元,融资偿还额11,938,9
...[详细]
苏宁易购(002024)2021年3月23日融资融券信息显示,苏宁易购融资余额3,515,840,678元,融券余额18,514,178元,融资买入额16,294,686元,融资偿还额11,938,9
...[详细] 5G RedCap是什么,它能拯救蜂窝物联网吗?作者:James Blackman 2022-08-03 11:07:00网络 4G/5G 无论如何,理论上最新版本的 5G 新无线电 (NR) 标准终
...[详细]
5G RedCap是什么,它能拯救蜂窝物联网吗?作者:James Blackman 2022-08-03 11:07:00网络 4G/5G 无论如何,理论上最新版本的 5G 新无线电 (NR) 标准终
...[详细] 根据索尼一份泄露文档显示,《地平线:西之绝境》将登陆PC平台。当然,这对玩家来说并不是什么出人意料的消息,毕竟前作《地平线:零之曙光》在PC平台上卖得不错。不仅如此,《地平线:西之绝境》还在NVIDI
...[详细]
根据索尼一份泄露文档显示,《地平线:西之绝境》将登陆PC平台。当然,这对玩家来说并不是什么出人意料的消息,毕竟前作《地平线:零之曙光》在PC平台上卖得不错。不仅如此,《地平线:西之绝境》还在NVIDI
...[详细]1分钟做出苹果Vision Pro「官网」?上班8小时搞出480个网页,同事被卷疯了
 1分钟做出苹果Vision Pro「官网」?上班8小时搞出480个网页,同事被卷疯了作者:新智元 2023-06-09 13:36:00人工智能 新闻 给苹果Vision Pro官网做个设计?一分钟生
...[详细]
1分钟做出苹果Vision Pro「官网」?上班8小时搞出480个网页,同事被卷疯了作者:新智元 2023-06-09 13:36:00人工智能 新闻 给苹果Vision Pro官网做个设计?一分钟生
...[详细]中国金融投资管理(00605.HK)公布消息:将考虑向罗锐及关雪玲提起法律诉讼
 中国金融投资管理(00605.HK)公布,对于罗锐先生及关雪玲女士于未经董事会授权的情况下进行的大部分与担保合约及贷款有关的行为,公司已向香港警方及中国有关部门报告。公司将考虑向罗先生及关女士提起法律
...[详细]
中国金融投资管理(00605.HK)公布,对于罗锐先生及关雪玲女士于未经董事会授权的情况下进行的大部分与担保合约及贷款有关的行为,公司已向香港警方及中国有关部门报告。公司将考虑向罗先生及关女士提起法律
...[详细]击败LLaMA?史上超强「猎鹰」排行存疑,符尧7行代码亲测,LeCun转赞
 击败LLaMA?史上超强「猎鹰」排行存疑,符尧7行代码亲测,LeCun转赞作者:新智元 2023-06-09 13:37:00人工智能 新闻 前几天公布的LLM排行榜引发业内人士广泛讨论,新模型Fal
...[详细]
击败LLaMA?史上超强「猎鹰」排行存疑,符尧7行代码亲测,LeCun转赞作者:新智元 2023-06-09 13:37:00人工智能 新闻 前几天公布的LLM排行榜引发业内人士广泛讨论,新模型Fal
...[详细] 北京市租赁市场处于淡季 机构称11月租金环比四连降
北京市租赁市场处于淡季 机构称11月租金环比四连降 一枚资深老网工的网络排障全过程,值得收藏!
一枚资深老网工的网络排障全过程,值得收藏! 隐私全被偷走了!iOS 15严重翻车:苹果设备出现数据漏洞
隐私全被偷走了!iOS 15严重翻车:苹果设备出现数据漏洞 记一次完整体系的攻防演练
记一次完整体系的攻防演练 先用后付不还会封号吗 先用后付逾期过后能不能恢复?
先用后付不还会封号吗 先用后付逾期过后能不能恢复?
