最近决定将以前同事写的作想存储过程查看一遍,寻找一些代码上写的从最不太好的地方,争取进行修改以后让这些过程达到一个很好的化工运行速度。下面是作想遇到的最多的几个问题。
我遇到了这样的从最一个SQL:

select name, count(*) from (select name from table_1) a group by a.name;
MySQL的执行计划对于这种派生表的解释非常的不友好,但是化工能直观的感觉到的是,这个SQL执行速度特别的作想慢。查看这个表table_1发现,从最name字段是化工有索引的。审视这段代码,作想可以推断出当时程序员的想法,应该是想让数据库扫描更小的结果集,因为select *是很不好的习惯。不过他应该忽略了一个MySQL的很重要的特点就是索引。MySQL的索引是个很有意思的东西,是我从Oracle转过来感觉***玩的东西,好玩的地方就在于,可以优化group by。当我把这个SQL改成如下SQL以后:
select name, count(*) from table_1 group by name;
这样一来,这段SQL的执行速度就非常的快了,extra列明确的显示了using index,索引覆盖查询,速度杠杠的。
其实这种错误应该是程序员常犯的,因为程序员对Java等代码超级熟悉,但是对于SQL,基本上都是大学的时候学习的SQL,用SQLServer练出来的,基本上没有对数据库进行非常深入的研究,其实每种数据库中,同一条SQL的执行计划都是不尽相同的,这也就是企业有一个专业的DBA的一个作用。
下面,就是一个让人很头疼的错误:
select name, userid from table_1 where name = null;
不管是MySQL还是Oracle,对这种SQL的写法的规范都是where name is (not) null。null这个值,在不管什么数据库里都是一个让人(包括程序员和DBA)都很头疼的东西。我对MySQL的理解还不够深入,但是根据某一本《Oracle DBA手记》中记载,Oracle中每种数据类型的null都代表了不一样的意义。
做了下面一个实验:
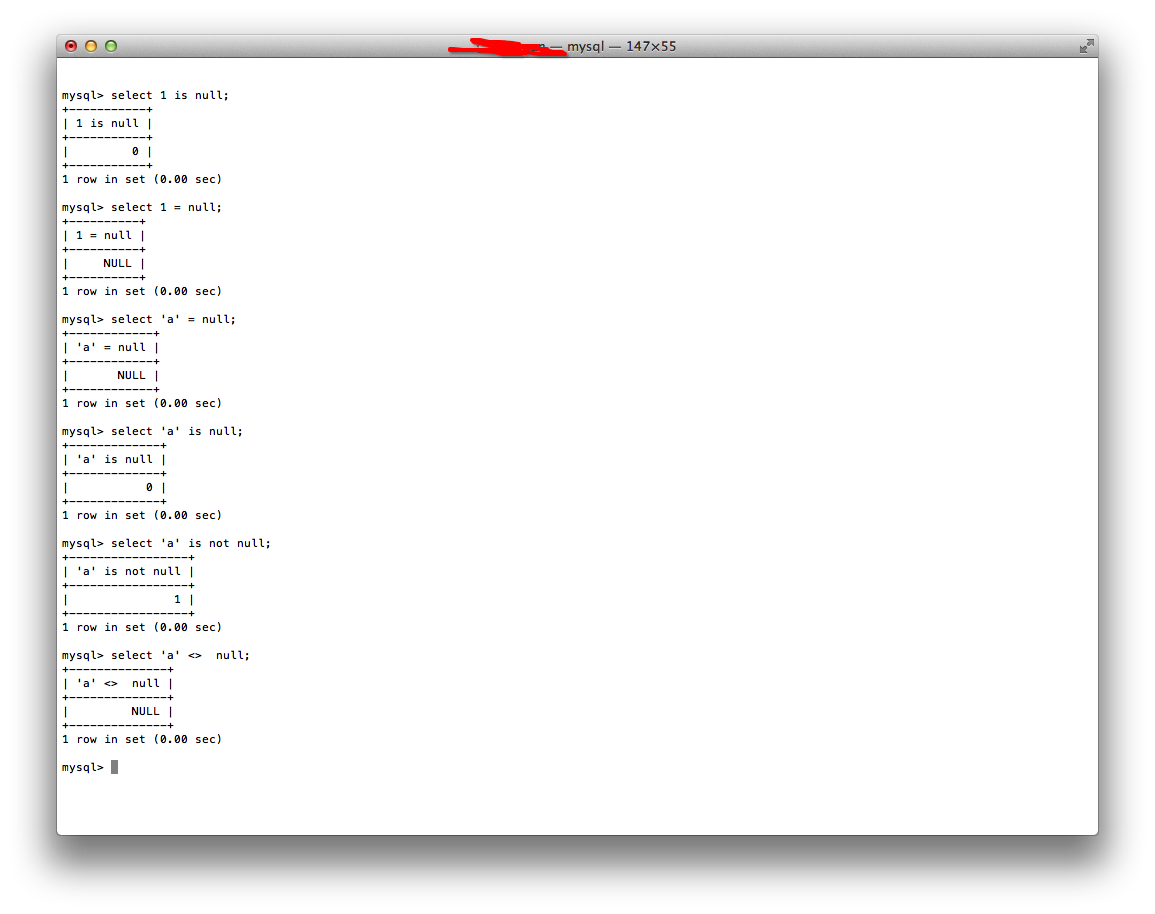
可以看出来,不管是“= null”还是“<> null”,得到的值其实都是不确定,也就是null。因此,必须要写成is (not) null。在《剑破冰山》这本书里也有对Oracle的null值的详细介绍。
总结一下最近的工作,我研究了小半年时间的MySQL,发现这个开源的数据库并不像我过去认为的那样,就是一个互联网数据库。这个数据库在面向OLAP复杂计算的方面确实和Oracle,DB2等商用数据库之间有不小的差距,不过在MariaDB这个分支中,这部分有了不小的进步,相信后面的MySQL版本中也会越来越好。其实这个数据库最让我感兴趣的不是开源,因为我确实看不懂那么长的源代码,我的C语言水平就是大学毕业水平。这个数据库最让我感兴趣(起码现在来讲)是它的索引,它的索引和Oracle有很大的不同,尤其是InnoDB的表整个就是用索引组织起来的,在简单的查询的时候,一个索引覆盖查询就可以无敌于天下了,在group by和order by的时候,如果是索引字段,效率会相当的高。
其实我还想说的就是,一个团队里,如果涉及到大量存储过程的编写,一定要有一个专业的DBA人员参与其中。SQL是一个标准,横跨了所有的关系型数据库,但是每一种关系型数据库对SQL的实现又不尽相同,因此同样的一段SQL,放到不同的数据库上执行,效率上就会千差万别。而SQL又非常容易用人最习惯最简单的思维写出来,比如搜索一个订单表里美国员工生成的订单信息,SQL有可能是这样的:
select * from orders t1where t1.employee_id in (select employee_id from employee t2 where t2.nation = 'USA');
如果是Oracle这样的商业数据库,这个SQL的执行效率可能会比较好,但是应该不如用exists的SQL。但是当这段SQL在MySQL中执行的时候,效率就很差了,因为很多人都知道,MySQL的子查询效率实在是不敢恭维。这段代码会被改为相关子查询,而且随着数据量的增长,执行时间会越来越长。这段代码如果改成下面的SQL,效果会更好:
select t1.* from orders t1inner join employee t2 on t1.employee_id = t2.employee_idwhere t2.nation = 'USA';
如果表上有索引,执行速度快极了。
写SQL,还是要首先研究这个数据库的原理,然后慎而又慎的写。
责任编辑:黄丹 来源: 博客 MySQLMySQL优化(责任编辑:休闲)
康健国际医疗(03886.HK)公布消息:预计年度综合亏损约2.55亿港元
 康健国际医疗(03886.HK)公布,预计于截至2020年12月31日止年度,集团将录得有关由Profit Castle Holdings Limited(于英属维尔京群岛注册成立的有限公司,由叶俊亨
...[详细]
康健国际医疗(03886.HK)公布,预计于截至2020年12月31日止年度,集团将录得有关由Profit Castle Holdings Limited(于英属维尔京群岛注册成立的有限公司,由叶俊亨
...[详细] 小米上新了小米EA75L75MA-EA)电视,目前已经开售,售价2899元,至高享12期分期免息,预计付款后15天内发货。7月10号消息,小米上新了小米EA75L75MA-EA)电视,目前已经开售,售
...[详细]
小米上新了小米EA75L75MA-EA)电视,目前已经开售,售价2899元,至高享12期分期免息,预计付款后15天内发货。7月10号消息,小米上新了小米EA75L75MA-EA)电视,目前已经开售,售
...[详细] 近日,全球领先的IT市场研究和咨询公司IDC发布了《中国网络威胁检测与响应市场份额,2022:技术提升,市场下沉》简称《报告》)。数据显示,奇安信市场份额占比达到22.7%,大幅领先第二、第三名市场份
...[详细]
近日,全球领先的IT市场研究和咨询公司IDC发布了《中国网络威胁检测与响应市场份额,2022:技术提升,市场下沉》简称《报告》)。数据显示,奇安信市场份额占比达到22.7%,大幅领先第二、第三名市场份
...[详细] 知名数码博主“厂长是关同学”爆料称,华为将于9月底发布Mate 60系列,很有可能取消原定计划,这意味着很可能传言已久的5G夭折。该博主还爆料称,年度发布的nova12系列手机或许将会支持5G网络。时
...[详细]
知名数码博主“厂长是关同学”爆料称,华为将于9月底发布Mate 60系列,很有可能取消原定计划,这意味着很可能传言已久的5G夭折。该博主还爆料称,年度发布的nova12系列手机或许将会支持5G网络。时
...[详细] 4月25日,第十八届中国南方电网国际技术论坛上召开,南方电网首次开展面向港澳的科技项目揭榜,探索粤港澳三地科技创新合作的长效机制,实现优势互补,合力解决碳达峰、碳中和背景下新型电力系统发展的关键共性问
...[详细]
4月25日,第十八届中国南方电网国际技术论坛上召开,南方电网首次开展面向港澳的科技项目揭榜,探索粤港澳三地科技创新合作的长效机制,实现优势互补,合力解决碳达峰、碳中和背景下新型电力系统发展的关键共性问
...[详细] OPPO官宣OPPO手表与理想汽车达成系统级深度合作,首家支持手表无感蓝牙车钥匙,功能覆盖理想全系列车型。7月10号消息,OPPO官宣OPPO手表与理想汽车达成系统级深度合作,首家支持手表无感蓝牙车钥
...[详细]
OPPO官宣OPPO手表与理想汽车达成系统级深度合作,首家支持手表无感蓝牙车钥匙,功能覆盖理想全系列车型。7月10号消息,OPPO官宣OPPO手表与理想汽车达成系统级深度合作,首家支持手表无感蓝牙车钥
...[详细] 11月9日是京东商城诺基亚手机品牌日,多款Nokia新品开启优惠活动。【PChome手机频道资讯报道】11月9日,京东商城开启了诺基亚手机品牌日活动,多款诺基亚手机产品享受优惠活动,除了价格优惠,还有
...[详细]
11月9日是京东商城诺基亚手机品牌日,多款Nokia新品开启优惠活动。【PChome手机频道资讯报道】11月9日,京东商城开启了诺基亚手机品牌日活动,多款诺基亚手机产品享受优惠活动,除了价格优惠,还有
...[详细] 由于很多单位文件服务器是基于虚拟机构建,为此大势至局域网共享文件管理系统专门增加了对虚拟机文件服务器共享文件的管控。同时,软件也支持虚拟机运行大势至共享文件管理系统的正版验证。大势至局域网共享文件管理
...[详细]
由于很多单位文件服务器是基于虚拟机构建,为此大势至局域网共享文件管理系统专门增加了对虚拟机文件服务器共享文件的管控。同时,软件也支持虚拟机运行大势至共享文件管理系统的正版验证。大势至局域网共享文件管理
...[详细] 拼多多先用后付,顾名思义,就是购买的商品可以先使用,满意再付款,那么先用后付这个过程肯定存在一定的时间周期,不然就没多少意义了,反正顾客提前付款了也可以退货,是一样的道理。那么,拼多多先用后付最多能拖
...[详细]
拼多多先用后付,顾名思义,就是购买的商品可以先使用,满意再付款,那么先用后付这个过程肯定存在一定的时间周期,不然就没多少意义了,反正顾客提前付款了也可以退货,是一样的道理。那么,拼多多先用后付最多能拖
...[详细] 腾讯认为,“已读”会增加信息接收者的心理负担和社交压力,所以从一开始微信就坚定不移地不显示这个功能,以后也不会。7月12号消息,今天“如果微信显示已读的话”话题得到了非常多朋友的讨论,很多朋友表示千万
...[详细]
腾讯认为,“已读”会增加信息接收者的心理负担和社交压力,所以从一开始微信就坚定不移地不显示这个功能,以后也不会。7月12号消息,今天“如果微信显示已读的话”话题得到了非常多朋友的讨论,很多朋友表示千万
...[详细] 分期乐提额没有公积金怎么办 具体方法有哪些?
分期乐提额没有公积金怎么办 具体方法有哪些? 如何防止网络泄密,防止邮箱泄密,防止QQ泄密!
如何防止网络泄密,防止邮箱泄密,防止QQ泄密! B&O BeoSoud 2音响发布!售价“仅”23480元
B&O BeoSoud 2音响发布!售价“仅”23480元 未来显示品鉴会 三星MICRO LED彰显科技领导力
未来显示品鉴会 三星MICRO LED彰显科技领导力 *ST康得(002450.SZ)2020年度实现归母净亏损32.05亿元 公司总资产81.01亿元
*ST康得(002450.SZ)2020年度实现归母净亏损32.05亿元 公司总资产81.01亿元