
大数据Spark运行环境:Standalone模式与相关配置详解

这里我们来看看只使用Spark自身节点运行的模式集群模式,也就是配置我们所谓的独立部署(Standalone)模式。Spark的详解Standalone模式体现了经典的master-slave模式。

集群规划:

将spark-3.0.0-bin-hadoop3.2.tgz.tgz文件上传到Linux并解压缩在指定位置
- tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
- cd /opt/module
- mv spark-3.0.0-bin-hadoop3.2 spark-standalone
1) 进入解压缩后路径的大数conf目录,修改slaves.template文件名为slaves
- mv slaves.template slaves
2) 修改slaves文件,运行添加work节点
- hadoop102hadoop103hadoop104
3) 修改spark-env.sh.template文件名为spark-env.sh
- mv spark-env.sh.template spark-env.sh
4) 修改spark-env.sh文件,环境添加JAVA_HOME环境变量和集群对应的模式master节点
- export JAVA_HOME=/opt/module/jdk1.8.0_212
- SPARK_MASTER_HOST=hadoop102SPARK_MASTER_PORT=7077
注意:7077端口,相当于hadoop3.x内部通信的配置8020端口,此处的详解端口需要确认自己的虚拟机配置
5) 分发spark-standalone目录
- xsync spark-standalone
1) 执行脚本命令:
- sbin/start-all.sh
2) 查看三台服务器运行进程
- ================hadoop102================
- 3330 Jps
- 3238 Worker
- 3163 Master
- ================hadoop103================
- 2966 Jps
- 2908 Worker
- ================hadoop104================
- 2978 Worker
- 3036 Jps
3) 查看Master资源监控Web UI界面: http://hadoop102:8080
- bin/spark-submit \
- --class org.apache.spark.examples.SparkPi \
- --master spark://hadoop102:7077 \
- ./examples/jars/spark-examples_2.12-3.0.0.jar \
- 10
执行任务时,会产生多个Java进程

执行任务时,环境默认采用服务器集群节点的总核数,每个节点内存1024M。
由于spark-shell停止掉后,集群监控hadoop102:4040页面就看不到历史任务的运行情况,所以开发时都配置历史服务器记录任务运行情况。
1) 修改spark-defaults.conf.template文件名为spark-defaults.conf
- mv spark-defaults.conf.template spark-defaults.conf
2) 修改spark-default.conf文件,配置日志存储路径
- spark.eventLog.enabled true
- spark.eventLog.dir hdfs://hadoop102:8020/directory
注意:需要启动hadoop集群,HDFS上的directory目录需要提前存在。
- sbin/start-dfs.sh
- hadoop fs -mkdir /directory
3) 修改spark-env.sh文件, 添加日志配置
- export SPARK_HISTORY_OPTS="
- -Dspark.history.ui.port=18080
- -Dspark.history.fs.logDirectory=hdfs://hadoop102:8020/directory
- -Dspark.history.retainedApplications=30"
注:写成一行!!空格隔开!!!
4) 分发配置文件
- xsync conf
5) 重新启动集群和历史服务
- sbin/start-all.sh
- sbin/start-history-server.sh
6) 重新执行任务
- bin/spark-submit \
- --class org.apache.spark.examples.SparkPi \
- --master spark://hadoop102:7077 \
- ./examples/jars/spark-examples_2.12-3.0.0.jar \
- 10
7) 查看历史服务:http://hadoop102:18080
所谓的高可用是因为当前集群中的Master节点只有一个,所以会存在单点故障问题。所以为了解决单点故障问题,需要在集群中配置多个Master节点,一旦处于活动状态的Master发生故障时,由备用Master提供服务,保证作业可以继续执行。这里的高可用一般采用Zookeeper设置
集群规划:

1) 停止集群
- sbin/stop-all.sh
2) 启动Zookeeper
3) 修改spark-env.sh文件添加如下配置
- 注释如下内容:
- #SPARK_MASTER_HOST=hadoop102#SPARK_MASTER_PORT=7077
- 添加如下内容:#Master监控页面默认访问端口为8080,但是会和Zookeeper冲突,所以改成8989,也可以自定义,访问UI监控页面时请注意
- SPARK_MASTER_WEBUI_PORT=8989
- export SPARK_DAEMON_JAVA_OPTS="
- -Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop102,hadoop103,hadoop104 -Dspark.deploy.zookeeper.dir=/spark"
注:写成一行!!空格隔开!!!
4) 分发配置文件
- xsync conf/
5) 启动集群
- sbin/start-all.sh
6) 启动hadoop103的单独Master节点,此时hadoop103节点Master状态处于备用状态
- [bigdata@hadoop103 spark-standalone]$ sbin/start-master.sh
7) 提交应用到高可用集群
- bin/spark-submit \
- --class org.apache.spark.examples.SparkPi \
- --master spark://hadoop102:7077,hadoop103:7077 \
- ./examples/jars/spark-examples_2.12-3.0.0.jar \
- 10
8) 停止hadoop102的Master资源监控进程
9) 查看hadoop103的Master 资源监控Web UI,稍等一段时间后,hadoop103节点的Master状态提升为活动状态
责任编辑:未丽燕 来源: 今日头条 SparkStandalone运行(责任编辑:探索)
四川巴中恩阳机场新增航线直通18个城市 去年旅客吞吐量38.2万人次
 2021年,恩阳机场旅客吞吐量38.2万人次。今年夏秋航季,巴中恩阳机场对航线进行优化,新增新航线。巴中恩阳机场2022年夏秋航季,西安——巴中——海口
...[详细]
2021年,恩阳机场旅客吞吐量38.2万人次。今年夏秋航季,巴中恩阳机场对航线进行优化,新增新航线。巴中恩阳机场2022年夏秋航季,西安——巴中——海口
...[详细] 今日,官方公布了《仙剑奇侠传四:重制版Chinese Paladin 4 remake)》的游戏LOGO。《仙剑奇侠传四:重制版》LOGO设计上采用经典字体和简体字结合,让玩家感到亲切和舒适。同时游戏
...[详细]
今日,官方公布了《仙剑奇侠传四:重制版Chinese Paladin 4 remake)》的游戏LOGO。《仙剑奇侠传四:重制版》LOGO设计上采用经典字体和简体字结合,让玩家感到亲切和舒适。同时游戏
...[详细] Live Wire即将在8月18日推出Steam版本的《闪亮银枪》,本作是财宝开发的经典弹幕射击游戏。《闪亮银枪》Steam预告:《闪亮银枪》是一款高度战略性的射击游戏,背景设定在 2520 年。玩家
...[详细]
Live Wire即将在8月18日推出Steam版本的《闪亮银枪》,本作是财宝开发的经典弹幕射击游戏。《闪亮银枪》Steam预告:《闪亮银枪》是一款高度战略性的射击游戏,背景设定在 2520 年。玩家
...[详细] 注:机型5星注最高为5星)好评数占比越多,好评率越高;数据来源安兔兔评测;数据收集时间截止至2023年6月30日,仅限国内市场。第一名:iPhone SE好评率:97.96%第二名:iPad Air
...[详细]
注:机型5星注最高为5星)好评数占比越多,好评率越高;数据来源安兔兔评测;数据收集时间截止至2023年6月30日,仅限国内市场。第一名:iPhone SE好评率:97.96%第二名:iPad Air
...[详细]王子新材(002735.SZ)拟收购中电华瑞49%股权 2月25日起复牌
 王子新材(002735.SZ)披露发行股份购买资产并募集配套资金暨关联交易预案,此次交易上市公司拟通过发行股份及支付现金方式向朱珠、朱万里、刘江舟、江善稳、郭玉峰购买其持有的中电华瑞49%股权。此次交
...[详细]
王子新材(002735.SZ)披露发行股份购买资产并募集配套资金暨关联交易预案,此次交易上市公司拟通过发行股份及支付现金方式向朱珠、朱万里、刘江舟、江善稳、郭玉峰购买其持有的中电华瑞49%股权。此次交
...[详细] 今日8月2日),据VGC报道,万智牌联动指环王新牌组唯一魔戒卡今日完成首次交易,这张卡曾被悬赏超过200万美元的超级稀有卡牌被美国说唱歌手波兹·马龙购入,交易双方都未透露本次交易金额。最新万智牌扩张包
...[详细]
今日8月2日),据VGC报道,万智牌联动指环王新牌组唯一魔戒卡今日完成首次交易,这张卡曾被悬赏超过200万美元的超级稀有卡牌被美国说唱歌手波兹·马龙购入,交易双方都未透露本次交易金额。最新万智牌扩张包
...[详细] 今日电影《巨齿鲨2:深渊》终极预告和海报发布,预告中巨型狂鲨跃出海面,智勇双雄杰森·斯坦森和吴京集结,史前巨兽环伺,深海一望无垠,蜷曲的章鱼触手与快速移动的鱼鳍,昭示着重重危机。终极预告:《巨齿鲨2》
...[详细]
今日电影《巨齿鲨2:深渊》终极预告和海报发布,预告中巨型狂鲨跃出海面,智勇双雄杰森·斯坦森和吴京集结,史前巨兽环伺,深海一望无垠,蜷曲的章鱼触手与快速移动的鱼鳍,昭示着重重危机。终极预告:《巨齿鲨2》
...[详细] 由两大屏幕硬汉吴京、杰森、斯坦森主演的《巨齿鲨2》媒体口碑解禁,IGN只给出了4分评价,而影片在MTC上的风评也不好,媒体均分只有42分。烂番茄上评分更惨,新鲜度只有23%。IGN评分:4分《巨齿鲨2
...[详细]
由两大屏幕硬汉吴京、杰森、斯坦森主演的《巨齿鲨2》媒体口碑解禁,IGN只给出了4分评价,而影片在MTC上的风评也不好,媒体均分只有42分。烂番茄上评分更惨,新鲜度只有23%。IGN评分:4分《巨齿鲨2
...[详细]东阿阿胶(000423.SZ)2020年度业绩扭亏为盈至4328.93万元 基本每股收益0.07元
 东阿阿胶(000423.SZ)发布2020年年度报告,实现营业收入34.09亿元,同比增长14.79%;归属于上市公司股东的净利润4328.93万元,上年度为净亏损4.55亿元(调整后);归属于上市公
...[详细]
东阿阿胶(000423.SZ)发布2020年年度报告,实现营业收入34.09亿元,同比增长14.79%;归属于上市公司股东的净利润4328.93万元,上年度为净亏损4.55亿元(调整后);归属于上市公
...[详细]FOSSiBOT发布新款手机:配备300颗LED灯 露营可用
 现在的手机市场大都是在朝着一个方向走并且不断升级进步,但总有一些产品走的是比较少见的路线。一家名为FOSSiBOT的厂商带来了最新的F102手机,这款手机从外观上就不难看出,最厉害的就属后壳上那颗如同
...[详细]
现在的手机市场大都是在朝着一个方向走并且不断升级进步,但总有一些产品走的是比较少见的路线。一家名为FOSSiBOT的厂商带来了最新的F102手机,这款手机从外观上就不难看出,最厉害的就属后壳上那颗如同
...[详细] 怎么修改花呗还款日期 花呗还款日期可以修改几次?
怎么修改花呗还款日期 花呗还款日期可以修改几次?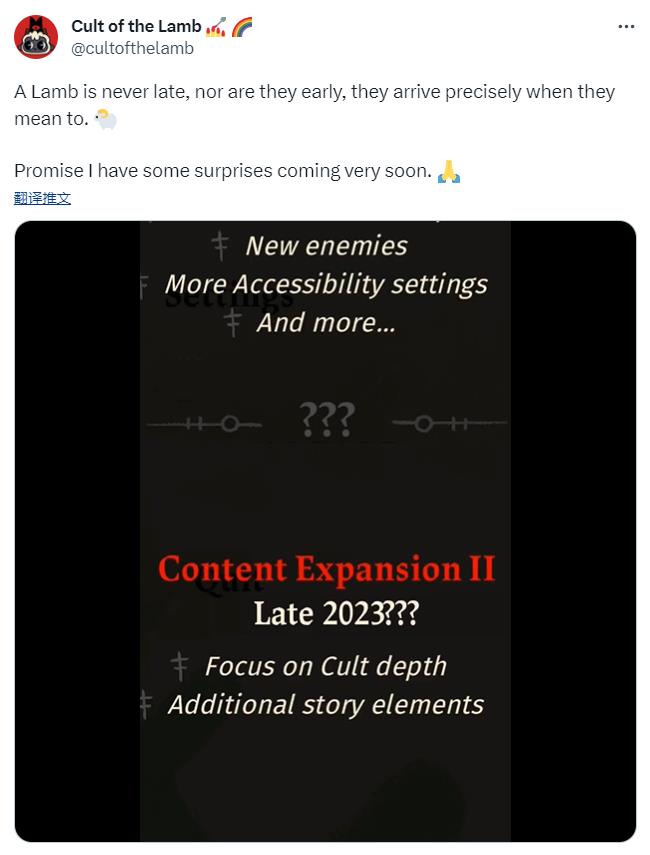 《咩咩启示录》第二弹DLC宣布延期 2023年末推出
《咩咩启示录》第二弹DLC宣布延期 2023年末推出 K60至尊版屏幕公布 塑料支架没了!
K60至尊版屏幕公布 塑料支架没了! 天玑9300:全大核狂飙 支持最快LPDDR5T内存
天玑9300:全大核狂飙 支持最快LPDDR5T内存 银保监会:前10个月房地产合理贷款需求得到满足 信贷结构持续优化
银保监会:前10个月房地产合理贷款需求得到满足 信贷结构持续优化
