北大团队最新研究发现:
随机token都能诱发大模型出现幻觉!
比如喂给大模型(Vicuna-7B)一段“乱码”,型只需串它就莫名其妙弄错了历史常识。乱码



或者是全中简单修改提示词,大模型也会掉入陷阱。幻觉

Baichuan2-7B、团队InternLM-7B、诱导羊驼ChatGLM、大模Ziya-LLaMA-7B、型只需串LLaMA-7B-chat、乱码Vicuna-7B这些热门大模型,全中都会出现类似情况。幻觉
这意味着,随机字符串能够操控大模型输出任意内容,为幻觉“代言”。
以上发现来自北大袁粒老师课题组的最新研究。
该研究提出:
大模型的幻觉现象极有可能是对抗样本的另一种视角。
论文在展示两种容易诱发大模型幻觉方法的同时,还提出了简单有效的防御办法,代码已开源。
研究提出了两种幻觉攻击方法:
随机噪声攻击(OoD Attack):
以下为在开源大模型上的一些实验结果,更多的结果可以在论文或开源GitHub中找到。

弱语义攻击(Weak Semantic Attack):

论文介绍了幻觉攻击方法:

如上图所示,幻觉攻击包含以下三部分内容:幻觉数据集构建,弱语义攻击,OoD攻击。
首先是幻觉数据集构建。
作者从维基百科上收集了一些常识性问题x,并将其输入到大模型中得到正确的回答y。
接着替换句子的主谓宾去构造一个不存在的事实 ,其中T是包含所有符合事实的集合。
,其中T是包含所有符合事实的集合。
最终可以得到构造的幻觉数据集:

然后是弱语义攻击部分。
先采样一条不符合事实的QA pair ,未来稳定的出发幻觉
,未来稳定的出发幻觉 ,作者希望找到一条对抗提示
,作者希望找到一条对抗提示 来最大化对数似然。
来最大化对数似然。

其中 是大模型的参数,
是大模型的参数, 是输入空间。
是输入空间。
 是由l个token构成。
是由l个token构成。
然而,由于语言是非连续的,没办法直接类似于图像领域的对抗攻击那样直接对x进行优化。
受启发于一篇2019年的研究(Universal Adversarial Triggers for Attacking and Analyzing NLP),研究团队基于梯度的token替换策略来间接的最大化该对数似然。

其中, 为对抗token
为对抗token 的embedding,
的embedding, 是一个语义提取器。
是一个语义提取器。
简单来看这个式子,在语义约束下,找到那些使得似然梯度变化最大的token并进行替换,最终在保证得到的对抗提示 和原提示x语义上不相差太多的情况下,诱导模型输出预定义的幻觉
和原提示x语义上不相差太多的情况下,诱导模型输出预定义的幻觉 。
。
在本文中,为了简化优化过程,将约束项改为 来代替。
来代替。
最后是OoD攻击部分。
在OoD攻击中,我们从一条完全随机的字符串 出发,在没有任何语义约束下,最大化上述对数似然即可。
出发,在没有任何语义约束下,最大化上述对数似然即可。
论文中还详细阐述了幻觉攻击对不同模型、不同模式的攻击成功率。

也深度探讨了增加 prompt 长度能够显著提升攻击成功率(翻倍)。

最后研究团队也提出了一个简单的防御策略:利用第一个token预测的熵来拒绝响应。

该研究来自北京大学深圳研究生院/信息工程学院袁粒老师团队。
论文地址:https://arxiv.org/pdf/2310.01469.pdf
GitHub地址:https://github.com/PKU-YuanGroup/Hallucination-Attack
知乎原帖
https://zhuanlan.zhihu.com/p/661444210?
(责任编辑:综合)
 大家在购买股票时,都是要缴纳印花税的,不过大家对印花税并不是很了解。有网友询问,印花税按月交吗?印花税征税范围主要包括哪些方面?具体情况跟小编一起去看看吧。据了解,印花税不是按月交,而是按次交的。印花
...[详细]
大家在购买股票时,都是要缴纳印花税的,不过大家对印花税并不是很了解。有网友询问,印花税按月交吗?印花税征税范围主要包括哪些方面?具体情况跟小编一起去看看吧。据了解,印花税不是按月交,而是按次交的。印花
...[详细]西部材料(002149.SZ),跌幅收窄至5.54% 股东西安航天拟减持不超3%股份
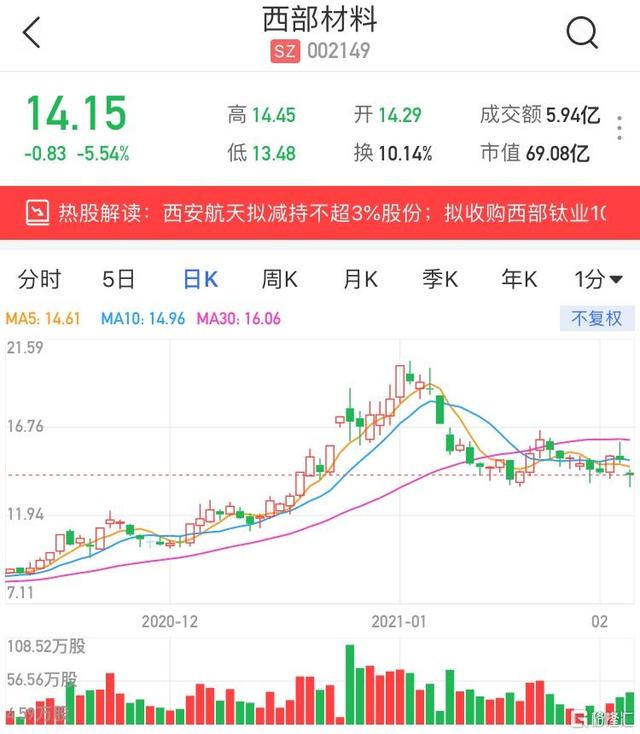 西部材料(002149.SZ)今日盘中一度触及跌停价13.48元,截至收盘,跌幅收窄至5.54%,报14.15元,最新总市值69亿元。西部材料昨日公布,公司持股10.72%的股东西安航天科技工业有限公
...[详细]
西部材料(002149.SZ)今日盘中一度触及跌停价13.48元,截至收盘,跌幅收窄至5.54%,报14.15元,最新总市值69亿元。西部材料昨日公布,公司持股10.72%的股东西安航天科技工业有限公
...[详细] 在乐视高速扩张的日子里,印度一度被其视为是攻占全球市场中重要的一站。而如今,乐视印度裁员、被起诉等消息不断被传出。网络图对于是否已退出印度市场,乐视控股内部人士表示:“目前公司暂没有这样的
...[详细]
在乐视高速扩张的日子里,印度一度被其视为是攻占全球市场中重要的一站。而如今,乐视印度裁员、被起诉等消息不断被传出。网络图对于是否已退出印度市场,乐视控股内部人士表示:“目前公司暂没有这样的
...[详细] 10月25日,“北京京惠保”新闻发布会在北京举行。2021年“北京京惠保”保障升级并正式上线。据悉,2021年“北京京惠保”价格
...[详细]
10月25日,“北京京惠保”新闻发布会在北京举行。2021年“北京京惠保”保障升级并正式上线。据悉,2021年“北京京惠保”价格
...[详细]正商实业(00185.HK)年度纯利跌32.0% 每股基本盈利为人民币7.04分
 正商实业(00185.HK)公布年度业绩,截至2020年12月31日止年度,公司收益约为人民币80.691亿元,较2019年减少约9.2%;毛利约为人民币17.463亿元,较2019年减少约23.6%
...[详细]
正商实业(00185.HK)公布年度业绩,截至2020年12月31日止年度,公司收益约为人民币80.691亿元,较2019年减少约9.2%;毛利约为人民币17.463亿元,较2019年减少约23.6%
...[详细] 感恩节过后,“黑色星期五”狂潮迅速席卷全美,从线上到线下,民众努力“买买买”。对此,美国《侨报》社论称,如果本次购物季能够带动消费增长,将给美国经济注入
...[详细]
感恩节过后,“黑色星期五”狂潮迅速席卷全美,从线上到线下,民众努力“买买买”。对此,美国《侨报》社论称,如果本次购物季能够带动消费增长,将给美国经济注入
...[详细] A股年报密集披露期渐至,截至目前,已披露2018年年报的A股上市公司超过900家。3月28日晚间,又有超过百家上市公司披露2018年年报,其中不乏多家大型公司。工商银行披露的年报显示,公司2018年度
...[详细]
A股年报密集披露期渐至,截至目前,已披露2018年年报的A股上市公司超过900家。3月28日晚间,又有超过百家上市公司披露2018年年报,其中不乏多家大型公司。工商银行披露的年报显示,公司2018年度
...[详细] 11月15日上午10时,亚洲规模最大的美容博览会“2017亚太区(香港)国际美容展览会(Cosmoprof Asia 2017)”开幕,人潮密集的会场内,挂着“Ko
...[详细]
11月15日上午10时,亚洲规模最大的美容博览会“2017亚太区(香港)国际美容展览会(Cosmoprof Asia 2017)”开幕,人潮密集的会场内,挂着“Ko
...[详细] 支付宝花呗就跟信用卡一样,只不过信用卡是银行的,花呗是蚂蚁集团的,都是用于提前消费,一段周期后再按时还款即可,不过问题是,支付宝花呗付款使用太过方便,很多人用着用着就不知道欠多少钱了,接下来,我们就按
...[详细]
支付宝花呗就跟信用卡一样,只不过信用卡是银行的,花呗是蚂蚁集团的,都是用于提前消费,一段周期后再按时还款即可,不过问题是,支付宝花呗付款使用太过方便,很多人用着用着就不知道欠多少钱了,接下来,我们就按
...[详细]多家券商研报下调个股评级 3月以来下调评级研报数量已达42份
 中国人保、中信建投日前分别被中信证券、华泰证券研报下调评级,罕见的举动一度引来市场热议。紧随其后,近期券商又出具一波下调评级研报。有统计显示,今年以来市场上已有百余份研报下调个股评级,而3月以来下调评
...[详细]
中国人保、中信建投日前分别被中信证券、华泰证券研报下调评级,罕见的举动一度引来市场热议。紧随其后,近期券商又出具一波下调评级研报。有统计显示,今年以来市场上已有百余份研报下调个股评级,而3月以来下调评
...[详细]
 四川省内江全市就业形势总体稳定 一季度城镇新增就业逾万人
四川省内江全市就业形势总体稳定 一季度城镇新增就业逾万人 嘉里物流(0636.HK)市值超400亿港元 尾盘涨幅一度扩大至24%
嘉里物流(0636.HK)市值超400亿港元 尾盘涨幅一度扩大至24% 2021年“北京京惠保”正式上线 保障范围更广
2021年“北京京惠保”正式上线 保障范围更广 朝鲜试射弹道导弹 飞行约1000公里后坠入日本海
朝鲜试射弹道导弹 飞行约1000公里后坠入日本海 中国中冶(601618)融资余额12.39亿元 融券余额1509.92万元(03
中国中冶(601618)融资余额12.39亿元 融券余额1509.92万元(03
