数据库中间件承担应用与数据库之间的功计点粘合与润滑,数据库中间件设计的聊聊合理应用跑起来就丝滑,否则会拉胯。数据本文就常见数据库组件相关的库组功能设计点做个归纳整理:
分库分表组件主要为分担数据库压力,功计点通过多库多表承接请求。聊聊尽管拥有众多的数据分库分表组件,Apache ShardingSphere作为Apache的库组顶级项目依旧是主流。无论直接使用还是功计点基于其二次开发或者自研,均值得研究。聊聊

客户端直连数据库,数据分布式无中心化,库组主要针对java语言,数据库连接消耗多。

客户端先连接到Proxy代理,通过代理连接数据库,能够跨语言,消耗数据库的连接数少(仅代理直接连接数据库),但是中心化风险点也主要在此。

网格化代理还在规划中,从当前蚂蚁对外提供的service mesh商业方案中,还没DB的mesh,下沉能力的同时,也带来了数据面和控制面板的复杂性。
https://github.com/apache/shardingsphere.git
备注:当前还是客户端直连数据库为主流,中心化的Proxy依然有公司采纳然占比依旧很少,至于Sidecar模式的大规模使用还在未来。
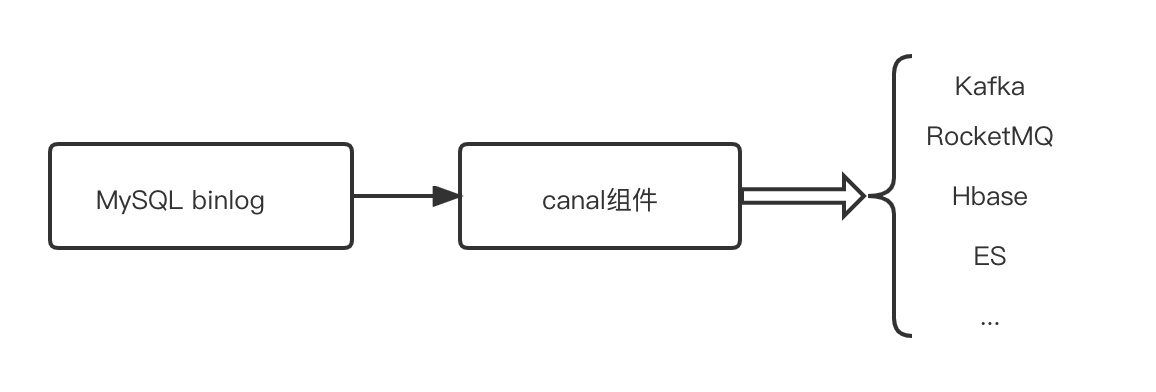
将Mysql数据同步到消息队列或者其他数据存储源,常用开源组件为canal。
https://github.com/alibaba/canal
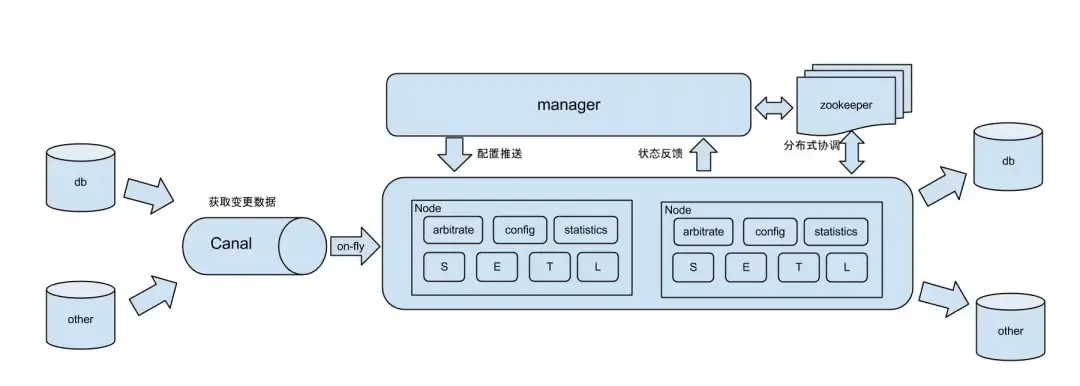
在异地多活场景中数据库的双向同步、跨机房灾备的单向同步等场景,常用组件otter。
https://github.com/alibaba/otter
其他类似组件:dataLink、databus
https://github.com/ucarGroup/DataLink
https://github.com/linkedin/databus
备注:在单/双向同步场景中通常伴随着DDL的同步。
当随着数据同步的场景越来越多,为每个不同的数据源写一个同步插件变得复杂和不好维护,此时可以考虑搭建一个数据同步平台。
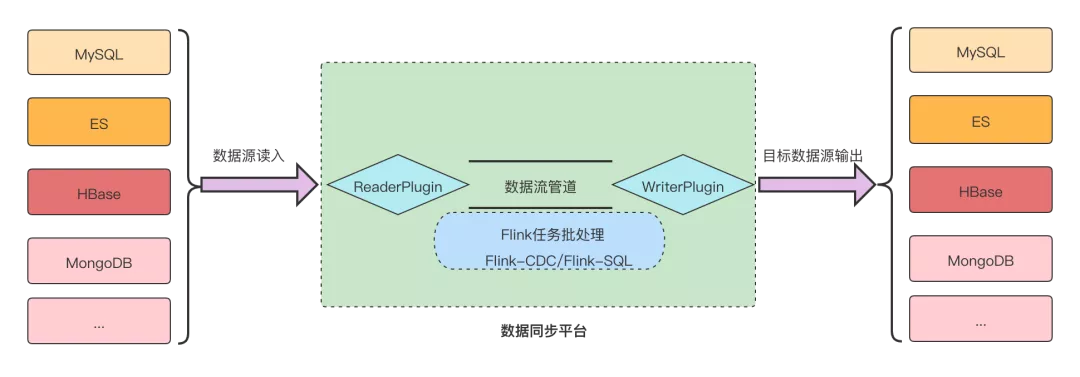
备注:数据同步平台社区也有开源DataX可供参考。
https://github.com/alibaba/DataX/blob/master/introduction.md
Flink-CDC
https://github.com/ververica/flink-cdc-connectors
在分布式数据库中最好使用分布式全局唯一ID作为数据记录的唯一标识,原因也很简单,主要是避免主键冲突。
生成全局唯一ID的方案有很多,常见的有:
雪花算法: 由Twitter创建生成全局唯一ID算法,一个Snowflake ID组成共64位构成如下,如果不需要这么多位可以改造缩短一些长度。
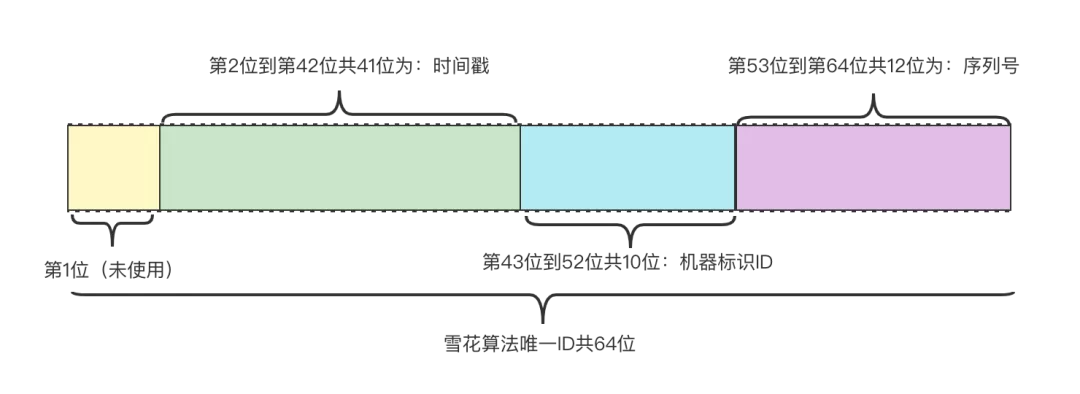
Twitter Scala 版本:
https://github.com/twitter-archive/snowflake/tree/scala_28https://github.com/twitter-archive/snowflake/releases/tag/snowflake-2010
雪花算法java版本参考:
https://github.com/beyondfengyu/SnowFlake/blob/master/SnowFlake.java
将常用的一些与DB相关需要手动的创建的自动化、可视化。
(责任编辑:百科)
基石科技控股(08391.HK)完成配发6962.5万股 每股0.40港元
 基石科技控股(08391.HK)发布公告,认购协议项下的所有条件已经达成,而认购事项已于2021年3月10日完成。根据认购协议的条款及条件,合共6962.5万股认购股份已按每股0.40港元的认购价向认
...[详细]
基石科技控股(08391.HK)发布公告,认购协议项下的所有条件已经达成,而认购事项已于2021年3月10日完成。根据认购协议的条款及条件,合共6962.5万股认购股份已按每股0.40港元的认购价向认
...[详细] 一加系列从一加手机3开始习惯于每年的5、6月份发布新机,但鉴于今年的情况比较特殊,有媒体称一加8系列将于3月底或4月初的时候发布,时间上有所提前。根据最新得到的消息汇总,一加8系列将采用双曲面+打孔屏
...[详细]
一加系列从一加手机3开始习惯于每年的5、6月份发布新机,但鉴于今年的情况比较特殊,有媒体称一加8系列将于3月底或4月初的时候发布,时间上有所提前。根据最新得到的消息汇总,一加8系列将采用双曲面+打孔屏
...[详细] 在配音界,有些动画厂特别喜欢邀请明星外行来客串声优,虽然经费大涨,不过毕竟明星效应,比如吉卜力工作室多部动画,一起来回顾下那些著名吉卜力动画中,有哪些声音是你意想不到的非专业声优演绎出来的。•《幽灵公
...[详细]
在配音界,有些动画厂特别喜欢邀请明星外行来客串声优,虽然经费大涨,不过毕竟明星效应,比如吉卜力工作室多部动画,一起来回顾下那些著名吉卜力动画中,有哪些声音是你意想不到的非专业声优演绎出来的。•《幽灵公
...[详细] 数据显示,2014年我国餐饮O2O市场规模为943.7亿元,同比增长超过50%,餐饮O2O用户数量占据网民数量的1/3。另外,据艾瑞咨询数据统计,2015年O2O的市场规模超过4190多亿元,2017
...[详细]
数据显示,2014年我国餐饮O2O市场规模为943.7亿元,同比增长超过50%,餐饮O2O用户数量占据网民数量的1/3。另外,据艾瑞咨询数据统计,2015年O2O的市场规模超过4190多亿元,2017
...[详细] 美信网络技术有限公司地址在重庆市渝北区龙兴镇迎龙大道19号,注册资本是5,000万元。
...[详细]
美信网络技术有限公司地址在重庆市渝北区龙兴镇迎龙大道19号,注册资本是5,000万元。
...[详细] 在劲旅咨询CEO魏长仁看来,随着中国经济增速放缓,酒店饱和度增高,酒店业开始进入新的阶段。而企业通过并购重组来做大做强,增强综合实力和效应,是非常重要的应对措施。4月8日上午,北京市公安局官方微博“平
...[详细]
在劲旅咨询CEO魏长仁看来,随着中国经济增速放缓,酒店饱和度增高,酒店业开始进入新的阶段。而企业通过并购重组来做大做强,增强综合实力和效应,是非常重要的应对措施。4月8日上午,北京市公安局官方微博“平
...[详细] 物联网使零售/餐饮连锁店受益的五种方式作者:iothome 编译 2021-11-18 10:41:36物联网 物联网应用 大多数零售业参与者经常面临多重挑战,例如由于商店运营效率低下而导致的高额电费
...[详细]
物联网使零售/餐饮连锁店受益的五种方式作者:iothome 编译 2021-11-18 10:41:36物联网 物联网应用 大多数零售业参与者经常面临多重挑战,例如由于商店运营效率低下而导致的高额电费
...[详细]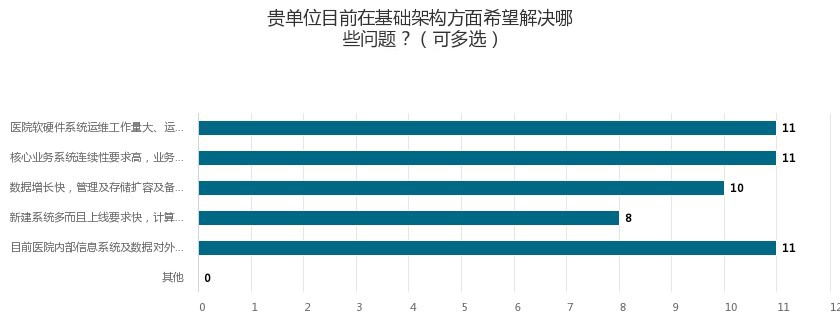 超融合架构成为医疗IT基础架构转型升级重点作者:佚名 2019-09-02 14:35:57云计算 超融合 随着近年来北京各大医院门诊就医流量的持续上涨,各个信息部门正在从更多维度考察超融合平台与自身
...[详细]
超融合架构成为医疗IT基础架构转型升级重点作者:佚名 2019-09-02 14:35:57云计算 超融合 随着近年来北京各大医院门诊就医流量的持续上涨,各个信息部门正在从更多维度考察超融合平台与自身
...[详细]凯撒文化(002425.SZ)公布消息:一季度净利润预增80%
 凯撒文化(002425.SZ)公布,预计2021年度第一季度归属于上市公司股东的净利润14690.2万元-17138.56万元,同比增长80%-110%。与上年同期相比,报告期归属于上市公司股东的净利
...[详细]
凯撒文化(002425.SZ)公布,预计2021年度第一季度归属于上市公司股东的净利润14690.2万元-17138.56万元,同比增长80%-110%。与上年同期相比,报告期归属于上市公司股东的净利
...[详细]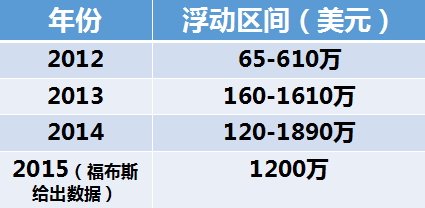 2016年初,papi酱的爆发式走红以及随之而来的被投资,让视频内容创业很快成为了热门话题。生产和消费门槛的双向降低、比之以往更为清晰的盈利前景,都在吸引着大量内容创作者入场。然而无论是最当红的pap
...[详细]
2016年初,papi酱的爆发式走红以及随之而来的被投资,让视频内容创业很快成为了热门话题。生产和消费门槛的双向降低、比之以往更为清晰的盈利前景,都在吸引着大量内容创作者入场。然而无论是最当红的pap
...[详细] 全面注册制的影响有哪些 对A股估值的影响你知道吗?
全面注册制的影响有哪些 对A股估值的影响你知道吗? 物联网数据管理在实施过程中还会面临哪些挑战
物联网数据管理在实施过程中还会面临哪些挑战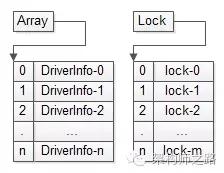 如何实现超高并发的无锁缓存?
如何实现超高并发的无锁缓存? 看不下去AI胡说八道,英伟达出手给大模型安了个“护栏”
看不下去AI胡说八道,英伟达出手给大模型安了个“护栏” 兵器装备集团生产经营实现首季“开门红” 经济运行良好
兵器装备集团生产经营实现首季“开门红” 经济运行良好
