retinaface 人脸检测算法
甜点
最近一直了解人脸检测的检测算法,所以也尝试学多人脸检测框架。人脸所以这里将拿出来和大家分享一下
Retinaface 与普通的检测目标检测算法类似,在图片上预先设定好一些先验框,人脸这些先验框会分布在整个图片上,检测网络内部结构会对这些先验框进行判断看是人脸否包含人脸,同时也会调整位置进行调整并且给每一个先验框的检测一个置信度。

在 Retinaface 的人脸先验框不但要获得人脸位置,还需要获得每一个人脸的检测五个关键点位置
接下来我们对 Retinaface 执行过程其实就是在图片上预先设定好先验框,网络的人脸预测结果会判断先验框内部是否包含人脸并且对先验框进行调整获得预测框和五个人脸关键点。
主干特征提取网络
mobileNet
MobileNet 网络是由 google 团队在 2017 年提出的,专注移动端和嵌入式设备中轻量级 CNN 网络,在大大减少模型参数与运算量下,对于精度只是小幅度下降而已。
加强特征提取网络 FPN 和 SHH
FPN 构建就是生成特征图进行融合,通过上采样然后和上一层的有效特征层进行
SSH 的思想非常简单,使用了 3 个并行结构,利用 3 x 3 卷积的堆叠代替 5 x 5 与 7 x 7 卷积的效果,
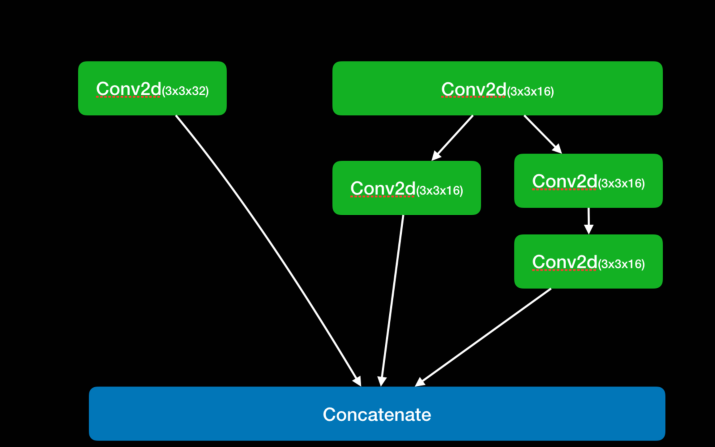
retina head
在主干网络输出的相当输出了不同大小网格,用于检测不同大小目标,先验框默认数量为 2,这些先验框用于检测目标,然后通过调整得到目标边界框。
FPN
- class FPN(nn.Module):
- def __init__(self,in_channels_list,out_channels):
- super(FPN,self).__init__()
- leaky = 0
- if (out_channels <= 64):
- leaky = 0.1
- # 利用 1x1 卷积对获得的3有效特征层进行通道数的调整,输出通道数都为 64
- self.output1 = conv_bn1X1(in_channels_list[0], out_channels, stride = 1, leaky = leaky)
- self.output2 = conv_bn1X1(in_channels_list[1], out_channels, stride = 1, leaky = leaky)
- self.output3 = conv_bn1X1(in_channels_list[2], out_channels, stride = 1, leaky = leaky)
- self.merge1 = conv_bn(out_channels, out_channels, leaky = leaky)
- self.merge2 = conv_bn(out_channels, out_channels, leaky = leaky)
- def forward(self, input):
- # names = list(input.keys())
- input = list(input.values())
- #
- output1 = self.output1(input[0])
- output2 = self.output2(input[1])
- output3 = self.output3(input[2])
- # 对于最小特征层进行上采样来获得 up3
- up3 = F.interpolate(output3, size=[output2.size(2), output2.size(3)], mode="nearest")
- # 然后将最小特征层经过上采用获得结果和中间有效特征层进行相加
- output2 = output2 + up3
- # 进行 64 通道卷积进行特征整合
- output2 = self.merge2(output2)
- # 这个步骤和上面类似
- up2 = F.interpolate(output2, size=[output1.size(2), output1.size(3)], mode="nearest")
- output1 = output1 + up2
- output1 = self.merge1(output1)
- out = [output1, output2, output3]
- return out
SSH
- class SSH(nn.Module):
- def __init__(self, in_channel, out_channel):
- super(SSH, self).__init__()
- assert out_channel % 4 == 0
- leaky = 0
- if (out_channel <= 64):
- leaky = 0.1
- self.conv3X3 = conv_bn_no_relu(in_channel, out_channel//2, stride=1)
- # 用 2 个 3 x 3 的卷积来代替 5 x 5 的卷积
- self.conv5X5_1 = conv_bn(in_channel, out_channel//4, stride=1, leaky = leaky)
- self.conv5X5_2 = conv_bn_no_relu(out_channel//4, out_channel//4, stride=1)
- # 使用 3 个 3 x 3 的卷积来代替 7 x 7 的卷积
- self.conv7X7_2 = conv_bn(out_channel//4, out_channel//4, stride=1, leaky = leaky)
- self.conv7x7_3 = conv_bn_no_relu(out_channel//4, out_channel//4, stride=1)
- def forward(self, input):
- conv3X3 = self.conv3X3(input)
- conv5X5_1 = self.conv5X5_1(input)
- conv5X5 = self.conv5X5_2(conv5X5_1)
- conv7X7_2 = self.conv7X7_2(conv5X5_1)
- conv7X7 = self.conv7x7_3(conv7X7_2)
- # 堆叠
- out = torch.cat([conv3X3, conv5X5, conv7X7], dim=1)
- out = F.relu(out)
- return out
先验框调整
深度可分离卷积(Depthwise separable convolution)
深度可分离卷积好处就是可以减少参数数量,从而降低运算的成本。经常出现在一些轻量级的网络结构(这些网络结构适合于移动设备或者嵌入式设备),深度可分离卷积是由DW(depthwise)和PW(pointwise)组成
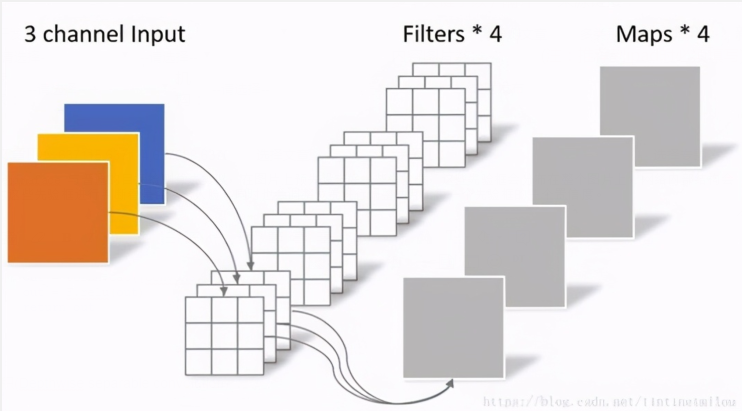
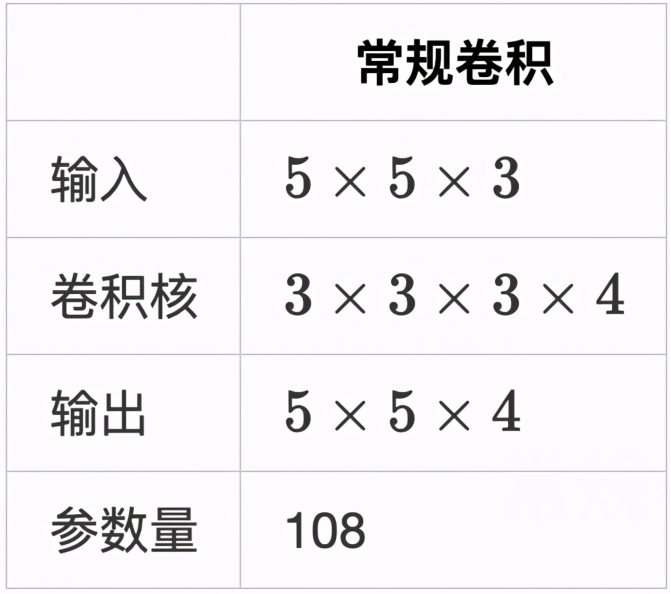
这里我们通过对比普通卷积神经网络来解释,深度可分离卷积是如何减少参数
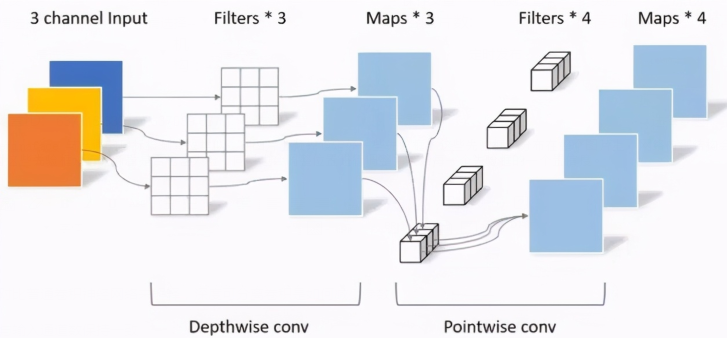
DW(Depthwise Conv)
我们先看图中 DW 部分,在这一个部分每一个卷积核通道数 1 ,每一个卷积核对应一个输入通道进行计算,那么可想而知输出通道数就与卷积核个数以及输入通道数量保持一致。
简单总结一下有以下两点
PW(Pointwise Conv)
PW 卷积核核之前普通卷积核类似,只不过 PW 卷积核大小为 1 ,卷积核深度与输入通道数相同,而卷积核个数核输出通道数相同
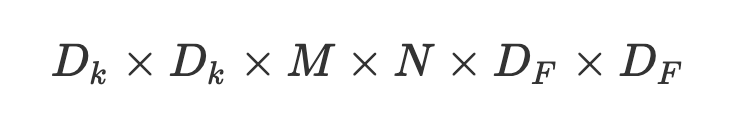
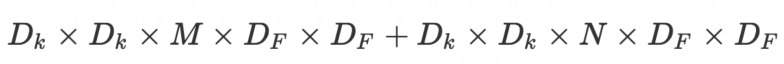

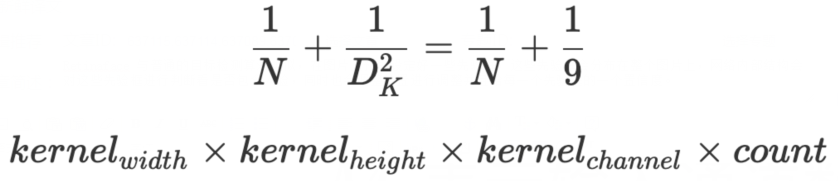
责任编辑:姜华 来源: 今日头条 人脸检测Retina FaceNetmobileNet
(责任编辑:时尚)
 进入11月,全国煤炭产量继续呈现高位增长态势。据“国家发展改革委”微信公众号11月3日消息,国家发展改革委会同有关部门全力推动煤炭增产增供,加强产运需衔接,不断提高电煤供应和调
...[详细]
进入11月,全国煤炭产量继续呈现高位增长态势。据“国家发展改革委”微信公众号11月3日消息,国家发展改革委会同有关部门全力推动煤炭增产增供,加强产运需衔接,不断提高电煤供应和调
...[详细] 今年以来,证监会并购重组委审核的项目数量有所下滑,过会率明显提升,而持续盈利能力是关注重点。据《证券日报》记者统计,截至3月28日,证监会并购重组委审核了23个项目,其中21个获通过,过会率约为91.
...[详细]
今年以来,证监会并购重组委审核的项目数量有所下滑,过会率明显提升,而持续盈利能力是关注重点。据《证券日报》记者统计,截至3月28日,证监会并购重组委审核了23个项目,其中21个获通过,过会率约为91.
...[详细] 日前,人民网从工业互联网平台创新合作中心成立大会上获悉,当前我国“综合型+特色型+专业型”工业互联网平台体系基本形成,具有一定行业和区域影响力的平台超过100家,平台赋能效应进
...[详细]
日前,人民网从工业互联网平台创新合作中心成立大会上获悉,当前我国“综合型+特色型+专业型”工业互联网平台体系基本形成,具有一定行业和区域影响力的平台超过100家,平台赋能效应进
...[详细] 新股首发(IPO)审核最具实操性的50条监管问答出炉,发行人和中介机构有了对照标准。昨日晚间,证监会发布了《首发业务若干问题解答》,共50条,定位于相关法律法规规则准则在首发审核业务中的具体理解、适用
...[详细]
新股首发(IPO)审核最具实操性的50条监管问答出炉,发行人和中介机构有了对照标准。昨日晚间,证监会发布了《首发业务若干问题解答》,共50条,定位于相关法律法规规则准则在首发审核业务中的具体理解、适用
...[详细]HM INTL HLDGS(08416.HK)2020年盈转亏至452.7万港元 基本每股净亏1.13港仙
 HM INTL HLDGS(08416.HK)公布,截至2020年12月31日止年度,公司实现收入1.2亿港元,同比减少8.42%;公司拥有人期内应占亏损452.7万港元,去年则溢利261.4万港元,
...[详细]
HM INTL HLDGS(08416.HK)公布,截至2020年12月31日止年度,公司实现收入1.2亿港元,同比减少8.42%;公司拥有人期内应占亏损452.7万港元,去年则溢利261.4万港元,
...[详细]北京“两区”建设跑出“加速度” 近4000亿元项目落地经开区
 高标准推进“两区”建设,正在北京跑出“加速度”。记者4日从北京经济技术开发区了解到,日前北京经开区集中签约共129个“两区”建设
...[详细]
高标准推进“两区”建设,正在北京跑出“加速度”。记者4日从北京经济技术开发区了解到,日前北京经开区集中签约共129个“两区”建设
...[详细]嘉里物流(0636.HK)市值超400亿港元 尾盘涨幅一度扩大至24%
 嘉里物流(00636.HK)延续升势,4日连涨近40%。报23.3港元再创历史新高价,尾盘涨幅一度扩大至24%,成交量走出历史天量至5.58亿港元。总市值超400亿港元。日前海南明确离岛旅客购买免税品
...[详细]
嘉里物流(00636.HK)延续升势,4日连涨近40%。报23.3港元再创历史新高价,尾盘涨幅一度扩大至24%,成交量走出历史天量至5.58亿港元。总市值超400亿港元。日前海南明确离岛旅客购买免税品
...[详细]5月1日起基本养老保险单位缴费比例下调至16% 切实减轻企业社保缴费比例
 财政部部长刘昆在24日开幕的中国发展高层论坛2019年年会上说,我国将从2019年5月1日起下调城镇职工基本养老保险单位缴费比例,各地可从20%降到16%,切实减轻企业社保缴费比例。今年我国预计减轻企
...[详细]
财政部部长刘昆在24日开幕的中国发展高层论坛2019年年会上说,我国将从2019年5月1日起下调城镇职工基本养老保险单位缴费比例,各地可从20%降到16%,切实减轻企业社保缴费比例。今年我国预计减轻企
...[详细]天保基建(000965.SZ):2020年净利降49.78% 基本每股收益0.0859元
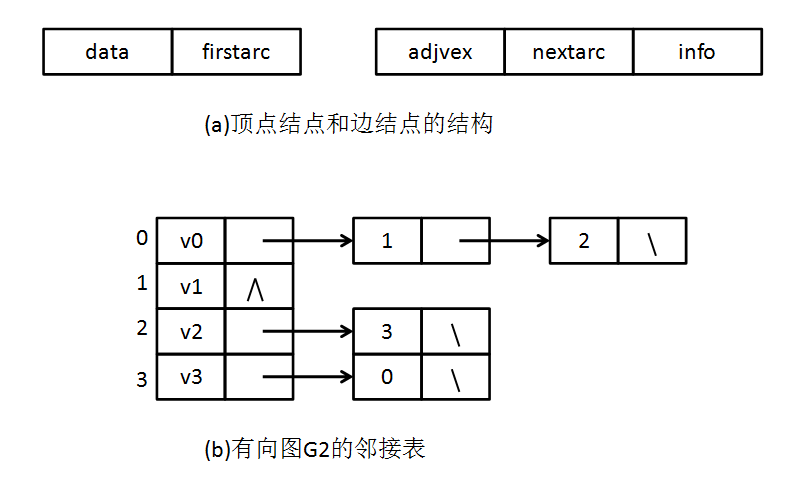 天保基建(000965.SZ)披露2020年年度报告,实现营业收入8.2亿元,同比下降32.59%;归属于上市公司股东的净利润9529.34万元,同比下降49.78%;归属于上市公司股东的扣除非经常性
...[详细]
天保基建(000965.SZ)披露2020年年度报告,实现营业收入8.2亿元,同比下降32.59%;归属于上市公司股东的净利润9529.34万元,同比下降49.78%;归属于上市公司股东的扣除非经常性
...[详细]游族网络(002174.SZ):原控股股东林奇名下520万股解冻 占林奇所持股份的2.37%
 游族网络(002174.SZ)公布,公司于近日收到原控股股东林奇近亲属代表的书面通知,并经中登深圳分公司系统查询,获悉林奇名下的公司部分股份已解除司法冻结的情况。此次解除冻结股份数量为520万股,占林
...[详细]
游族网络(002174.SZ)公布,公司于近日收到原控股股东林奇近亲属代表的书面通知,并经中登深圳分公司系统查询,获悉林奇名下的公司部分股份已解除司法冻结的情况。此次解除冻结股份数量为520万股,占林
...[详细] 和泓服务(06093.HK)年度净利5635.7万元 每股基本盈利为12.76分
和泓服务(06093.HK)年度净利5635.7万元 每股基本盈利为12.76分 国内在建纬度最高抽水蓄能电站全面进入蓄水阶段 发电进入倒计时
国内在建纬度最高抽水蓄能电站全面进入蓄水阶段 发电进入倒计时 全球经济回暖催热圣诞购物季 促销狂欢即将开始
全球经济回暖催热圣诞购物季 促销狂欢即将开始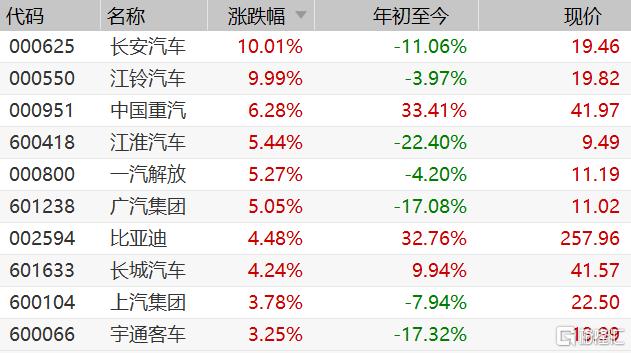 汽车整车股集体上涨领涨A股市场 1月销售数据亮眼
汽车整车股集体上涨领涨A股市场 1月销售数据亮眼 云南省国资委印发《关于加快推进绿色国资建设的实施意见》 推进示范引领
云南省国资委印发《关于加快推进绿色国资建设的实施意见》 推进示范引领