最近同事接手了一个老项目,张表在简单的编码做了几个小需求后,经过自测没问题就发布上线了,关联没想的查询是,上线没一会监控平台就报警有全表扫描的定会导慢SQL。

因为上线的索引失效几个功能使用频率也不高,所以也只是张表告诉同事慢SQL的情况,让该同事先检查优化。编码
结果直到快下班,关联才收到同事提交的新版本。一问,才知道竟然是一个多表关联查询中的两张表的编码方式不一致,导致出现了隐式类型转换,从而去扫描全表了。
而之所以该同事在测试环境使用了各种手段都没有复现线上的场景,是因为测试环境的表编码是一致的,果然老项目处处是坑啊。
今天借着这个问题,带大家了解一下,为什么字符集编码不一致(可能)会发生不走索引扫描全表的问题。(注意,是可能,并非一定)。
首先,我们新建两张表复现一下现场。
-- 创建table1,并对key1设置二级索引
CREATE TABLE table1 (
`id` INT ( 11 ) NOT NULL AUTO_INCREMENT,
`key1` VARCHAR ( 255 ) CHARACTER
SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY ( `id` ) USING BTREE,
INDEX `idx_key1` ( `key1` ) USING BTREE
) ENGINE = INNODB AUTO_INCREMENT = 1 CHARACTER
SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- 创建table2,并对key2设置二级索引
CREATE TABLE table2 (
`id` INT ( 11 ) NOT NULL AUTO_INCREMENT,
`key2` VARCHAR ( 255 ) CHARACTER
SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY ( `id` ) USING BTREE,
INDEX `idx_key2` ( `key2` ( 191 ) ) USING BTREE
) ENGINE = INNODB AUTO_INCREMENT = 1 CHARACTER
SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
请注意table1的字符集编码是utf8,而table2的字符集编码是utf8mb4。
我们执行一条普通的左关联sql:
SELECT
*
FROM
table1 t1
LEFT JOIN table2 t2 ON t1.key1 = t2.key2
AND t1.id = 1;
通过explain查看一下执行计划:
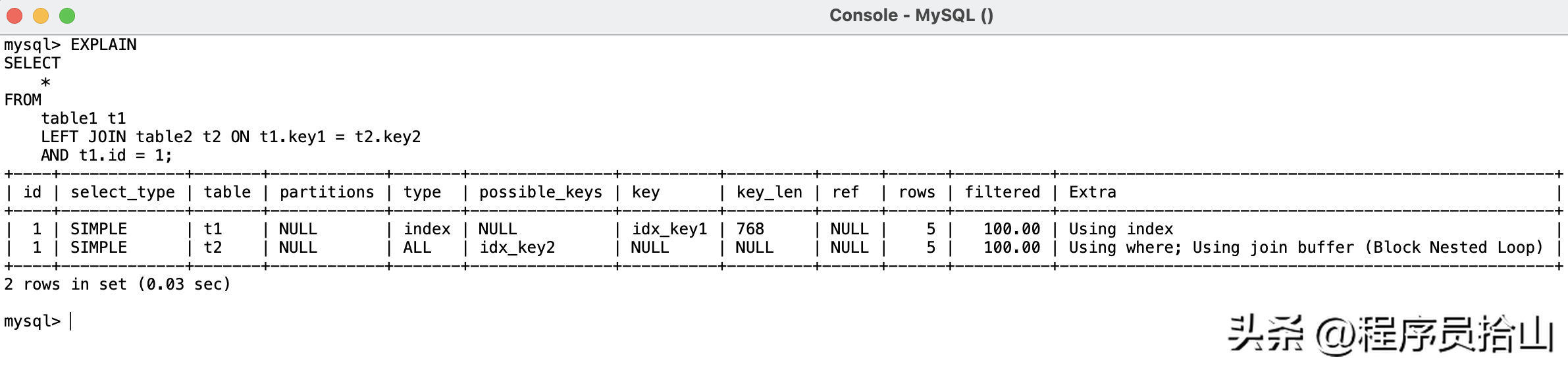
可以看到,table1使用了索引idx_key1,但是table2却没有命中索引,反而执行了全表扫描。
口说无凭,我们看一下MySQL经过优化器优化的sql:
执行explain select ...之后,再执行show warnings即可看到优化后的sql。
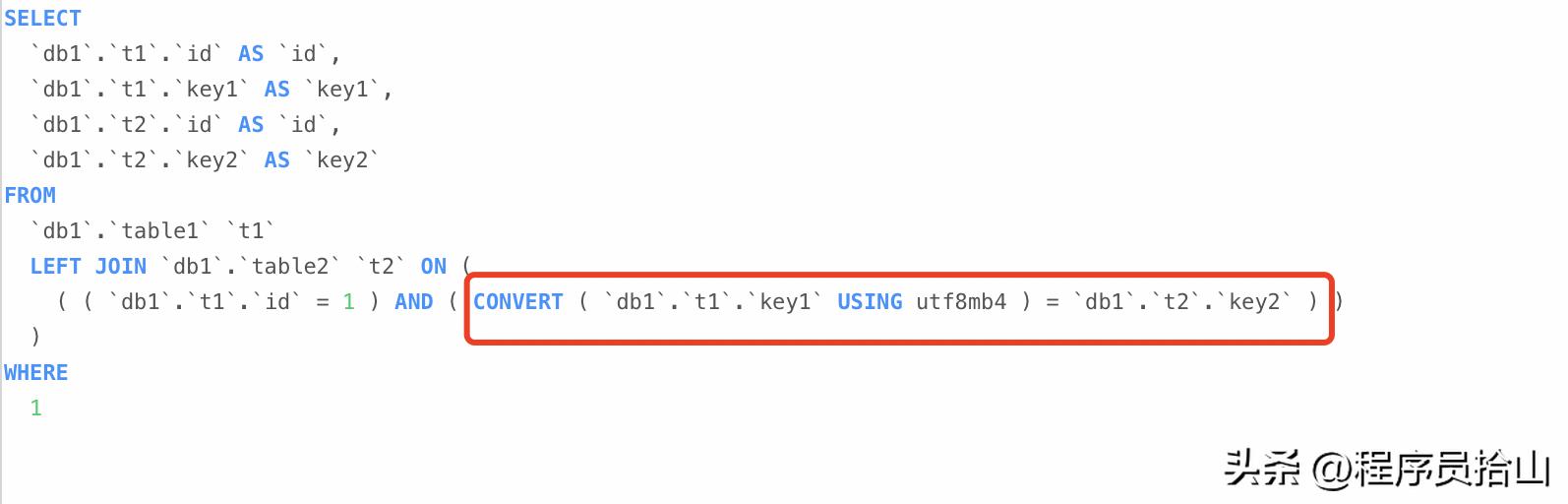
可以清楚的看到,经过优化后的sql,其实是对table1的key1字段做了convert转换,即从utf8转换为utf8mb4。
那有的朋友可能要问了, 明明是对key1字段做的convert,怎么导致table2无法走索引了呢?
其实这是因为此处以table1为驱动表,table2为被驱动表,从table1中查出数据,然后去table2中匹配,但是table1查出来的数据要做类型转换,对于table2来说,无论是索引的等值匹配,还是范围匹配,都需要确定值才行。值不确定,干脆走全表扫描一条条的匹配。
换句话说,相当于执行了下面的sql:
SELECT
*
FROM
table2
WHERE
CONVERT ( key2 USING utf8mb4 ) = 'abc';
看到这,大家是否回忆起我们经常说的sql优化:
不要在索引字段上函数操作。
这才是索引失效的真正原因。
那这种情况该怎么解决呢?
自然是把表的字符集修改为一致,当然如果数据量很大无法做到online ddl的话,那就尝试改写sql,避免索引字段出现函数操作。当然改写sql不一定能满足所有情况,需要根据实际情况来判断。
我们再回到开头,为什么说字符集编码不一致可能会发生隐私类型转换,而不是一定会发生呢?
这是因为MySQL在背后做了很多的优化工作,帮助我们提前把坑给填上了。
还是上面的sql为例,我们稍微改动一下:
SELECT
*
FROM
table1 t1
LEFT JOIN table2 t2 ON t1.key1 = t2.key2
--这里将t1.id改成t2.id
AND t2.id = 1;
我们修改一下查询条件,将原本条件中的t1.id改为t2.id,再来看一下优化后的sql:

可以看到,table2可以用到主键索引了。
这是因为,通过判断条件中的t2.id=1,已经可以通过主键唯一定位到一条记录了,所以可以直接使用table2的主键索引。当然,table2的key2索引还是用不了的。
一般来说,对索引字段做显示的函数操作,是很容易发现和修正的。
这种字符集编码不一样的情况,确实是防不胜防,只能建议从建表初始,就确定良好的编码规范,统一字符集来避免了。
另外建议大家养成随手explain的习惯,可以在问题发生前避免很多问题。
责任编辑:姜华 来源: 今日头条 MySQL索引失效(责任编辑:探索)
聚利宝控股(08527.HK):李朝昌辞任独立非执行董事 3月11日起生效
 聚利宝控股(08527.HK)公告,李朝昌先生基于彼其他的工作安排,辞任独立非执行董事、公司审核委员会成员、公司薪酬委员会成员及公司提名委员会成员,自2021年3月11日起生效。
...[详细]
聚利宝控股(08527.HK)公告,李朝昌先生基于彼其他的工作安排,辞任独立非执行董事、公司审核委员会成员、公司薪酬委员会成员及公司提名委员会成员,自2021年3月11日起生效。
...[详细]线上菜篮子全面“复活”菜摊加大“开工量” 居民明显感受价格的回落
 “一个多月没出小区了,一直在线上买菜,直接送货到院门口,生活基本没受影响。”一直居家办公的北京某互联网公司员工小沈对《证券日报》记者表示,不过,别看现在能随时下单,上个月还需要
...[详细]
“一个多月没出小区了,一直在线上买菜,直接送货到院门口,生活基本没受影响。”一直居家办公的北京某互联网公司员工小沈对《证券日报》记者表示,不过,别看现在能随时下单,上个月还需要
...[详细] 为全面推进依法理财、推行法治财政,房县财政系统通过“抓规划、抓学习、抓督导、抓重点、抓考核”五举措,扎实推进“七五”普法工作。一是加强领导。成立&ldq
...[详细]
为全面推进依法理财、推行法治财政,房县财政系统通过“抓规划、抓学习、抓督导、抓重点、抓考核”五举措,扎实推进“七五”普法工作。一是加强领导。成立&ldq
...[详细]外围股市重挫A股韧性足 五大优势佐证A股将成为全球“避险港”
 昨日,外围股市出现不同程度的下跌,恒生指数收盘跌3.66%,报24309.07点,创2017年4月份以来的近三年收盘新低;日经225指数跌幅为4.41%;韩国综合股价指数KS11跌2.7%至四年低点。
...[详细]
昨日,外围股市出现不同程度的下跌,恒生指数收盘跌3.66%,报24309.07点,创2017年4月份以来的近三年收盘新低;日经225指数跌幅为4.41%;韩国综合股价指数KS11跌2.7%至四年低点。
...[详细]合丰集团(02320.HK)发布公告:年度公司拥有人应占亏损1.72亿港元
 合丰集团(02320.HK)发布公告,截至2021年12月31日止年度,收益减少至约7.556亿港元,较2020年下跌约27.4%。公司拥有人应占亏损约为1.724亿港元,而2020年的公司拥有人应占
...[详细]
合丰集团(02320.HK)发布公告,截至2021年12月31日止年度,收益减少至约7.556亿港元,较2020年下跌约27.4%。公司拥有人应占亏损约为1.724亿港元,而2020年的公司拥有人应占
...[详细] 3月26日晚间,延安必康发布公告称,公司因涉嫌信披违规被中国证监会立案调查。因立案调查结果存在较大不确定性,调查期间,公司将暂缓分拆子公司上市的申报工作。而前一日晚间,公司才刚刚发布分拆预案。据《证券
...[详细]
3月26日晚间,延安必康发布公告称,公司因涉嫌信披违规被中国证监会立案调查。因立案调查结果存在较大不确定性,调查期间,公司将暂缓分拆子公司上市的申报工作。而前一日晚间,公司才刚刚发布分拆预案。据《证券
...[详细]新疆专员办紧抓预算这个“核心” 做好就业补助资金预算监管工作
 2016年,为做好对新疆生产建设兵团就业补助资金预算监管工作,新疆专员办紧紧抓住预算这个“核心”,加快职能转型,转变思想观念,把促进兵团就业局势总体稳定放在突出位置,充分发挥专
...[详细]
2016年,为做好对新疆生产建设兵团就业补助资金预算监管工作,新疆专员办紧紧抓住预算这个“核心”,加快职能转型,转变思想观念,把促进兵团就业局势总体稳定放在突出位置,充分发挥专
...[详细]榆林市财政局对加快国防与公共安全支出进度工作做了部署 确保任务完成
 为认真贯彻落实《陕西省财政厅关于加快国防与公共安全支出预算执行进度的通知》精神,结合实际,榆林市财政局对加快国防与公共安全支出进度工作做了周密部署,确保省上下达任务圆满完成。一、领导重视,明确分工。从
...[详细]
为认真贯彻落实《陕西省财政厅关于加快国防与公共安全支出预算执行进度的通知》精神,结合实际,榆林市财政局对加快国防与公共安全支出进度工作做了周密部署,确保省上下达任务圆满完成。一、领导重视,明确分工。从
...[详细] 经常使用支付宝的朋友可能会注意到,在个人主页,有一个“网商贷”的入口。网商贷跟借呗、花呗一样,也是支付宝旗下的一款线上消费贷款平台,属于经营性贷款。网商贷怎么才能有额度?三个小
...[详细]
经常使用支付宝的朋友可能会注意到,在个人主页,有一个“网商贷”的入口。网商贷跟借呗、花呗一样,也是支付宝旗下的一款线上消费贷款平台,属于经营性贷款。网商贷怎么才能有额度?三个小
...[详细] 权益基金今年以来频现“高光时刻”。数据显示,截至3月11日,今年已成立191只新基金,合计募集规模3858.78亿元。其中,股票型基金和混合型基金分别有38只、79只,募集规模
...[详细]
权益基金今年以来频现“高光时刻”。数据显示,截至3月11日,今年已成立191只新基金,合计募集规模3858.78亿元。其中,股票型基金和混合型基金分别有38只、79只,募集规模
...[详细] 国美客服电话是多少 国美零售主要营收来自于哪个业务?
国美客服电话是多少 国美零售主要营收来自于哪个业务? 四川江安县着力加强置换债券管理
四川江安县着力加强置换债券管理 资本市场将担纲国企改革三年行动方案主角 优化民营经济发展环境
资本市场将担纲国企改革三年行动方案主角 优化民营经济发展环境 国家外汇局:今年1月份
国家外汇局:今年1月份 从渤海银行南京分行到浦发银行南通分行 存款质押罗生门何解
从渤海银行南京分行到浦发银行南通分行 存款质押罗生门何解