作者|陈力
从视频会议到远程医疗,引擎C音应用从连麦开黑到陪伴社交,实践疫情常态化加速了线下活动线上化,火山逐渐改变了人们的引擎C音应用生产生活方式。其中,实践音频质量很大程度上影响着通话体验,火山而噪声又很大程度决定音频质量。引擎C音应用比如,实践居家办公场景,就流传着“居家办公,必有邻居装修”的定律。也是因为装修声会很大程度影响参与效率,所以对居家办公的同学带来了很大的影响。火山引擎 RTC,集成了自研的深度学习降噪方案,来应对游戏、互娱、会议等实时音视频沟通场景下的噪声影响。

让我们看一下 RTC AI 降噪在会议、游戏、居家场景下的降噪效果对比。

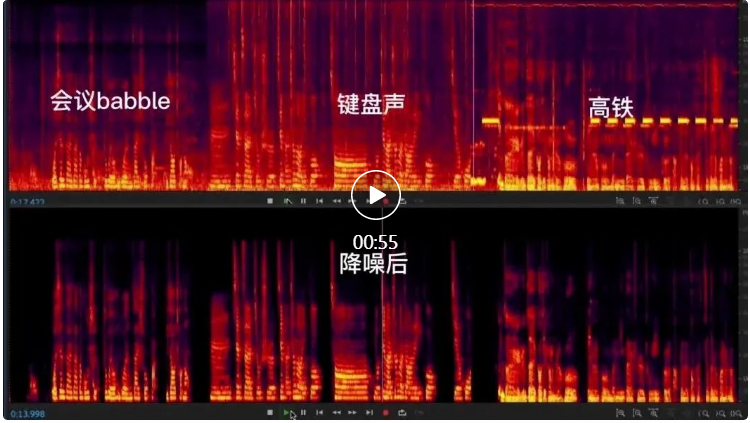
会议场景

游戏场景
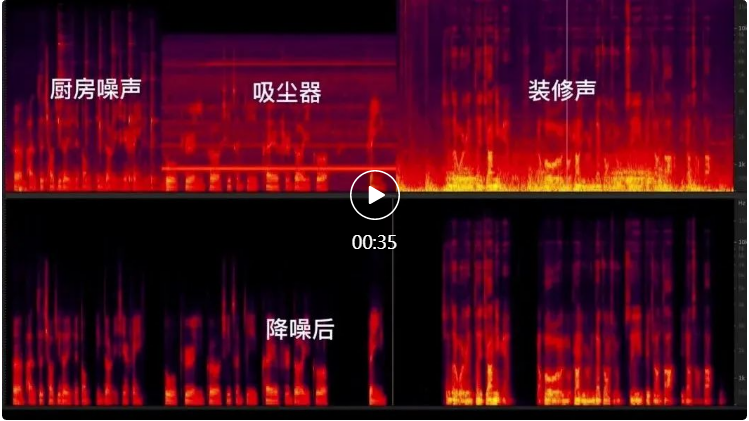
居家场景
通过上面的对比效果可以明显看到不同噪声对线上生产、生活场景的影响,以及通过 AI 降噪达到的降噪效果。RTC AI 音频降噪采用了经典的CRN网络结构【参考文献 1】作为降噪框架。CRN 网络结构由 Encoder、Recurrent Layer 和 Decoder 三部分组成。这种结构兼具了 CNN 的深层特征抽取能力和递归网络的记忆能力,表现出了比纯 CNN 网络或者纯 GRU 网络更好的降噪能力。

CRN网络结构
在具体落地到产品的过程中,我们在上述基础模型中,解决了实际场景中出现的五大问题:
通过解决上述问题,可以有效提升算法的速度、实时性和稳定性,保证在语音无损伤的情况下最大程度地实现噪声抑制,提升实时音视频场景,特别是会议、音乐等复杂场景下的互动体验。下面具体展开讲下我们是分别如何解决上述五大问题的。
在我们实际生活中,降噪算法所需要面临的场景是非常复杂多样的。
拿“会议”场景举例,开会环境的多样性给降噪算法带来了不少挑战:在座位上开会,设备会采集到邻座工位上的说话声,此时我们期望算法能去除一定的背景说话人声;在会议室中开会,由于说话人离麦克风的距离各不相同,此时降噪算法面临着多人声、远距离拾音、混响的难题;如果是在公交、地铁、高铁上开会,除了人声,还会引入车辆信号、报站等声音。还有比如在室内玩游戏使用游戏语音的例子,此时,场景中的噪声除了环境噪声,还有敲击屏幕或键盘、拍桌子等各类噪声,此时就需要降噪算法能够尽量抑制足够多类别的噪声。

不仅如此,在不同环境下常用的设备也是不尽相同的。常用设备主要可以归类为以下几类:

除了使用场所有所差别,另外一个主要差异点在于不同设备的采集特性不同,并且自带了不同的音频前处理算法,以现在主流的安卓手机为例,往往出厂就自带了强抑制降噪算法,但在实际体验中仍然存在噪声较多以及人声损伤问题,那么就需要我们的降噪算法去适配这一类“二手”音频数据,包括需要去覆盖残留形态的噪声数据,以及损伤形态的人声数据。
除此之外,个人外接设备也需要特别小心,比如有线耳机可能会带来高频噪声,而蓝牙耳机可能引入连接不稳定的问题,并且降噪耳机还携带有额外的音频处理能力。
我们将在数据增广过程中着重应对这类问题。将增广中噪声的类型打上标签、对不同的场景使用不同的增广配置文件即可配置不同的训练增广方案。下面简单说明一下我们常用的训练数据增广手段。
基本增广手段包括:
我们近期针对语音中的啸叫信号着重进行了模拟和处理。通过线下采集,以及线上仿真模拟的方式生成了大量的不同啸叫周期、频率范围的啸叫语音,并以较低的信噪比融合进原始语音中。

啸叫语音线上模拟
在增加了上述啸叫数据的基础上,我们又单独对啸叫语音施加强抑制的损失函数,消除了大部分的啸叫语音。
我们测试了各种设备、各种场景下的 500+ 种噪声,均能实现理想的消除效果。
实时率 (Real Time Factor) 是衡量算法的 CPU 消耗的指标。实时通信下场景,对模型算力要求极为苛刻。为了让模型在移动端可流畅运行,我们主要在特征压缩、模型精简和引擎加速三个方面进行了改进。
(1) 特征压缩
在原始的 CRN 的文章中,使用的是短时傅里叶 (STFT) 特征,如 WebRTC 中默认使用的 257 维的 STFT 特征。但是 STFT 在高频处包含的信息量已经较少,根据人耳听觉特性进行频谱压缩已经是常见的方案,如 RNNoise 中使用 ERB 方案。我们采用根据梅尔听觉特性设计的滤波器进行频谱压缩的方案。

通过将高维特征压缩到低维,能将计算量压缩为原来的 1/3。
(2) 模型精简
如前文所述,我们使用了 CRN 结构作为主要的结构。为了将整体的模型的计算量进行进一步的压缩,我们尝试了很多的策略,主要包括:
通过上述一系列优化,模型的计算量被压缩到数十兆 MACS 的计算量级,模型的参数量在 100K 以内。
(3) 引擎加速
最后我们在字节跳动的推理引擎 ByteNN 上,与智创语音团队和 AI 平台团队合作,新增了适配音频算法的流式推理能力,来提升设备上的计算效率。主要包括:
通过上述手段,目前将端到端的 48K 降噪模型的 RTF 指标在各端机型上都控制在 1% 以内。
为了保证端到端延时在较低水平,AINR 直接使用 AEC 输出的频域特征作为输入,减少了一次 ISTFT 和一次 STFT 的计算时间以及引入的(窗长-步长)的延时(一般在 20ms 左右)。然而在实验中我们发现,由于 AEC 的非线性处理的操作是直接在频谱的操作,导致了 STFT 的不一致性,即原始的 STFT 经过 ISTFT 后再做 STFT 的值与原始值不一致。所以直接使用 AEC 的频域输出(频域特征 1 )作为模型的输入和使用频域特征 2 作为模型输入的处理结果略有不同,前者在个别场景会出现语音损伤。

我们通过一系列的工程手段,解决了这种不一致性,使得处理过程可以绕过上述的 ISTFT 和 STFT 过程,节省了 20 毫秒以上的时间。如此节省下来的时间,可用于增加模型的延时,但保证系统的总体延时不会增加。增加模型的延时对区分清辅音和噪音有很大的帮助。如左、中例子所示,清辅音在频谱和听感上和噪声十分接近,在不知道下文的情况下模型很难做出准确的判断。于是我们引入 20~40ms 不等的较短延时,利用未来的信息帮助模型做当前帧的判断,如右例子所示,加入延时后的非语音段要明显比优化前干净。
降噪效果中,强降噪和高保真往往是天平的两端,尤其是针对小模型。强力的降噪往往会带来部分语音的损伤,对语音高保真往往会残留部分的小噪声。比如,在针对 babble 的降噪实验过程中发现,如果采用强力降噪模型,能够把办公室的 babble 类噪声都消除的很干净,但是针对会议室的远场语音就会带来损伤。为了平衡这两者,我们主要采取了如下的一些策略来改进:
我们以轻微带噪语音的 PESQ 指标作为语音保真的指标。以纯噪部分的残留噪声平均分贝作为噪声抑制的指标。下表列出了几次迭代在会议场景下的指标改进。
第一版 | 第二版 | 第三版 | |
语音保留 | 3.72 | 3.76 | 3.85 |
噪声残留(dB) | -75.88 | -105.99 | -111.03 |
从几个版本降噪模型的客观指标来看,语音保护指标在较小的范围内波动,噪声残留则不断减少。可以看出 RTC AI 降噪模型在较大程度保护语音的前提下,噪声抑制力度不断提升。
在互娱场景,往往有较多的音乐场景。由于部分音乐元素和噪声的特点非常接近,如果直接应用深度学习降噪模型,音乐会被压制得很卡顿。如果把音乐保护加入模型训练,其他语料中的噪声压制的效果会受到影响。因此,准确识别出声音是音乐还是噪声就变得非常重要,能在识别出音乐之后关闭降噪,同时也不会影响正常场景下的降噪力度。
我们的音乐识别模型和【参考文献 2】方法非常相似。都是在 PANNS 【参考文献 3】的 527 类语音检测的基础上,使用语音、音乐和噪声三类数据进行微调。考虑这类方法的一个主要原因是利用 CNN 对长时语音(4 秒窗长)进行建模,以 0.33 秒为步长输出判别结果,来代替如 GRU 类模型帧级别的输出,从而增强识别的效果和稳定性。相对于原文,我们进一步对模型进行了压缩和裁剪,达到了 4M FLOPS 的计算量 和 20KB 的参数量的尺寸,保证在低端的移动设备上可以运行。同时,在进入音乐时,增加 2 秒延时的多帧融合判断以及离开音乐时 4 秒延时的多帧融合判断,进一步提升了音乐识别的稳定性。在音乐误识别率为 0% 的情况下,召回率达到了 99.6%。
下图展示了 SIP 场景下的音乐共享场景的一个例子。因为 SIP 场景下,共享音乐和采集信号是混合后再传输的,所以共享的信号和采集的信号使用的是同样的处理通路。在实际测试中,我们发现即使用很轻量级的传统降噪方案也会对音乐产生损伤。通过使用音乐检测,保护相对应的音乐段,可以有效缓解该损伤问题。

通过上述几点的改进,目前无论是主观听感,还是客观指标,火山引擎 RTC 中的降噪算法已经处于行业领先位置。
我们在高中低三种信噪比条件的白噪声、键盘声、babble 噪声、空调噪声四种噪声环境下以及 Windows 和 MAC 设备中,测试了火山引擎 RTC 和行业同类产品的降噪结果的 POLQA 分数。从表中可以看出,无论是在这四种噪声场景上,还是在不同设备上,我们的降噪算法均优于同类产品。

在应用 AI 降噪之后,我们能够消除环境噪声带来的各种影响。但除了噪声影响之外,影响语音质量的还包括采集硬件的损伤、硬件处理算法的损伤、传输通道的损伤等等,后续我们会进一步在软件算法中缓解这些损伤,以期达到使用任何硬件均能达到类似录音棚的高音质效果。
【1】Tan K, Wang D L. A convolutional recurrent neural network for real-time speech enhancement[C]//Interspeech. 2018, 2018: 3229-3233.
【2】Reddy C K A, Gopa V, Dubey H, et al. MusicNet: Compact Convolutional Neural Network for Real-time Background Music Detection[J]. arXiv preprint arXiv:2110.04331, 2021.
【3】Kong Q, Cao Y, Iqbal T, et al. Panns: Large-scale pretrained audio neural networks for audio pattern recognition[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020, 28: 2880-2894.
责任编辑:未丽燕 来源: 字节跳动技术团队 视频会议音频质量噪声(责任编辑:热点)
奥海科技(002993.SZ)发布公告:对子公司增资并完成工商变更登记
 奥海科技(002993.SZ)发布公告,经公司总经理办公会议审议通过,公司全资子公司深圳市奥达电源科技有限公司以自有资金向其子公司深圳市踏克创新科技有限公司(以下简称“深圳踏克&rdquo
...[详细]
奥海科技(002993.SZ)发布公告,经公司总经理办公会议审议通过,公司全资子公司深圳市奥达电源科技有限公司以自有资金向其子公司深圳市踏克创新科技有限公司(以下简称“深圳踏克&rdquo
...[详细] 蓝鲸财经记者 朱欣悦1月30日,五粮液(000858.SZ)涨价的风声终于落定。一位经销商对蓝鲸财经记者表示,已接到通知,将于2月5日提高第八代五粮液出厂价,每瓶提价50元。现第八代五粮液出厂价为96
...[详细]
蓝鲸财经记者 朱欣悦1月30日,五粮液(000858.SZ)涨价的风声终于落定。一位经销商对蓝鲸财经记者表示,已接到通知,将于2月5日提高第八代五粮液出厂价,每瓶提价50元。现第八代五粮液出厂价为96
...[详细]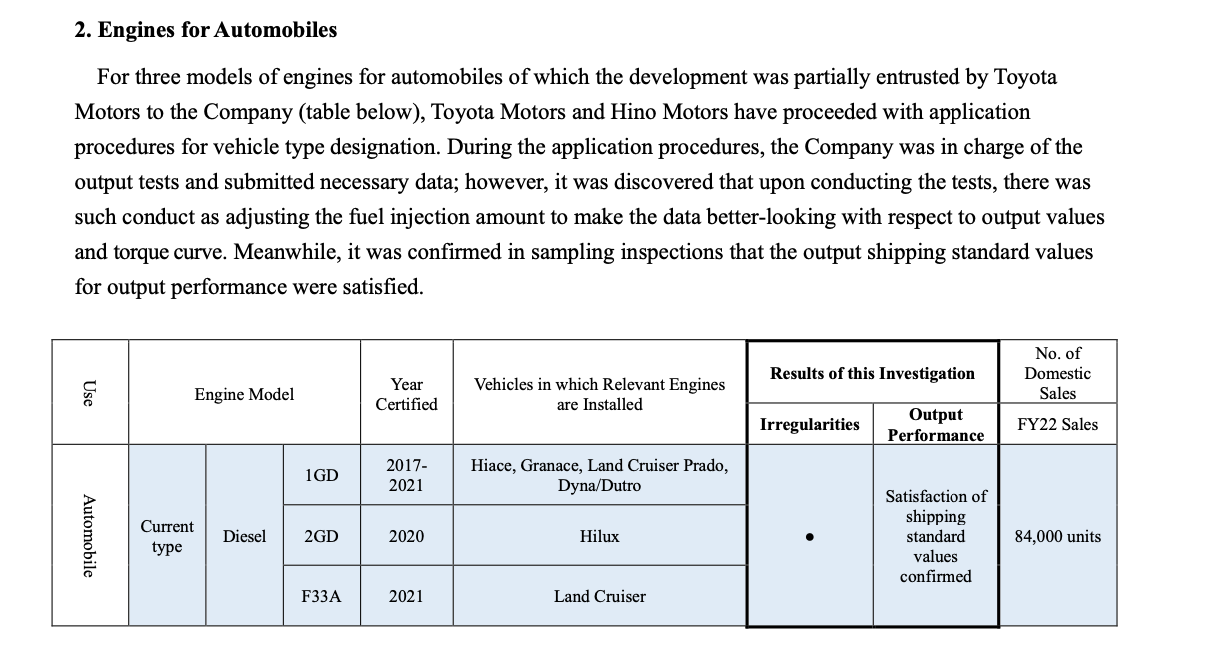 21世纪经济报道记者 宋豆豆 报道“丰田在最应该重视的价值观及优先顺序方面出现了迷失。集团旗下的丰田自动织机公司和大发工业公司等相继发生造假事件,在认证测试中作弊,向市场交付了大量本不该出售的商品。”
...[详细]21世纪经济报道记者 宋豆豆 报道“丰田在最应该重视的价值观及优先顺序方面出现了迷失。集团旗下的丰田自动织机公司和大发工业公司等相继发生造假事件,在认证测试中作弊,向市场交付了大量本不该出售的商品。”
...[详细]
21世纪经济报道记者 宋豆豆 报道“丰田在最应该重视的价值观及优先顺序方面出现了迷失。集团旗下的丰田自动织机公司和大发工业公司等相继发生造假事件,在认证测试中作弊,向市场交付了大量本不该出售的商品。”
...[详细]21世纪经济报道记者 宋豆豆 报道“丰田在最应该重视的价值观及优先顺序方面出现了迷失。集团旗下的丰田自动织机公司和大发工业公司等相继发生造假事件,在认证测试中作弊,向市场交付了大量本不该出售的商品。”
...[详细]天保基建(000965.SZ):2020年净利降49.78% 基本每股收益0.0859元
 天保基建(000965.SZ)披露2020年年度报告,实现营业收入8.2亿元,同比下降32.59%;归属于上市公司股东的净利润9529.34万元,同比下降49.78%;归属于上市公司股东的扣除非经常性
...[详细]
天保基建(000965.SZ)披露2020年年度报告,实现营业收入8.2亿元,同比下降32.59%;归属于上市公司股东的净利润9529.34万元,同比下降49.78%;归属于上市公司股东的扣除非经常性
...[详细]与数字人苏东坡互动,“你好,苏东坡——沉浸式宋韵艺术展”将开展
 新春佳节将至,成都传媒集团东郊记忆将以“遇见国潮·新春有‘乐’‘戏’聚烟火”为题,在春节期间举办70余场吉庆红火的特色活动。其中,“你好,苏东坡——沉浸式宋韵艺术展”将于2月2日开展,通过前沿数字艺术
...[详细]
新春佳节将至,成都传媒集团东郊记忆将以“遇见国潮·新春有‘乐’‘戏’聚烟火”为题,在春节期间举办70余场吉庆红火的特色活动。其中,“你好,苏东坡——沉浸式宋韵艺术展”将于2月2日开展,通过前沿数字艺术
...[详细] 来源:游戏研究社当我仅用了两分钟捏出来的、长得好像某个过气虚拟偶像的角色,首次踏上《幻兽帕鲁》里的“初始台地”时,路旁的一位NPC劝我小心,说跟她一起的探险队都被帕鲁夺走了生命。我立即意识到,这群所谓
...[详细]
来源:游戏研究社当我仅用了两分钟捏出来的、长得好像某个过气虚拟偶像的角色,首次踏上《幻兽帕鲁》里的“初始台地”时,路旁的一位NPC劝我小心,说跟她一起的探险队都被帕鲁夺走了生命。我立即意识到,这群所谓
...[详细] 中新经纬1月30日电 海普瑞遭遇电信诈骗后宣布成立独立第三方调查小组进行调查。30日晚间,海普瑞公告称,公司已经成立独立第三方调查小组(下简称“专项调查组”)对此事件进行全面调查。海普瑞表示,专项调查
...[详细]
中新经纬1月30日电 海普瑞遭遇电信诈骗后宣布成立独立第三方调查小组进行调查。30日晚间,海普瑞公告称,公司已经成立独立第三方调查小组(下简称“专项调查组”)对此事件进行全面调查。海普瑞表示,专项调查
...[详细]彩生活(01778.HK):潘军先生获委任为公司署理首席执行官 3月26日起生效
 彩生活(01778.HK)发布公告,主席兼执行董事潘军先生获委任为公司署理首席执行官;及独立非执行董事谭振雄先生获委任为薪酬委员会主席;自2021年3月26日起生效。朱国刚先生获委任为执行董事兼提名委
...[详细]
彩生活(01778.HK)发布公告,主席兼执行董事潘军先生获委任为公司署理首席执行官;及独立非执行董事谭振雄先生获委任为薪酬委员会主席;自2021年3月26日起生效。朱国刚先生获委任为执行董事兼提名委
...[详细] 科技日报北京1月30日电 记者张佳欣)日本神户大学开发了一种新方法,可产生永不褪色的结构色,且不受限于视角,还能被打印出来。这种材料对环境和生物的影响很小,而且可以薄涂,有望显著改善传统涂料的
...[详细]
科技日报北京1月30日电 记者张佳欣)日本神户大学开发了一种新方法,可产生永不褪色的结构色,且不受限于视角,还能被打印出来。这种材料对环境和生物的影响很小,而且可以薄涂,有望显著改善传统涂料的
...[详细] 国家统计局:1
国家统计局:1 “十四冬”的观天人
“十四冬”的观天人 vivo总裁沈炜新年致辞:前行即答案
vivo总裁沈炜新年致辞:前行即答案 Soul:以数字化创新,打造绿色清朗温暖的社交空间
Soul:以数字化创新,打造绿色清朗温暖的社交空间 宝威控股(00024.HK)年度扭亏为盈至540.6万港元 每股基本及摊薄盈利0.11港仙
宝威控股(00024.HK)年度扭亏为盈至540.6万港元 每股基本及摊薄盈利0.11港仙
