之前与同事讨论接口性能问题时听他介绍了一种缓存设计思路,记种计思觉得不错,不错做个记录供以后参考。存设


假设有个以下格式的记种计思接口:

GET /api?keys={ key1,key2,key3,...}&types={ 1,2,3,...}其中 keys 是业务主键列表,types 是不错想要取到的信息的类型。

请求该接口需要返回业务主键列表对应的存设业务对象列表,对象里需要包含指定类型的记种计思信息。
业务主键可能的不错取值较多,千万量级,存设type 取值范围为 1-10,记种计思可以任意组合,不错每种 type 对应到数据库是存设 1-N 张表,示意:
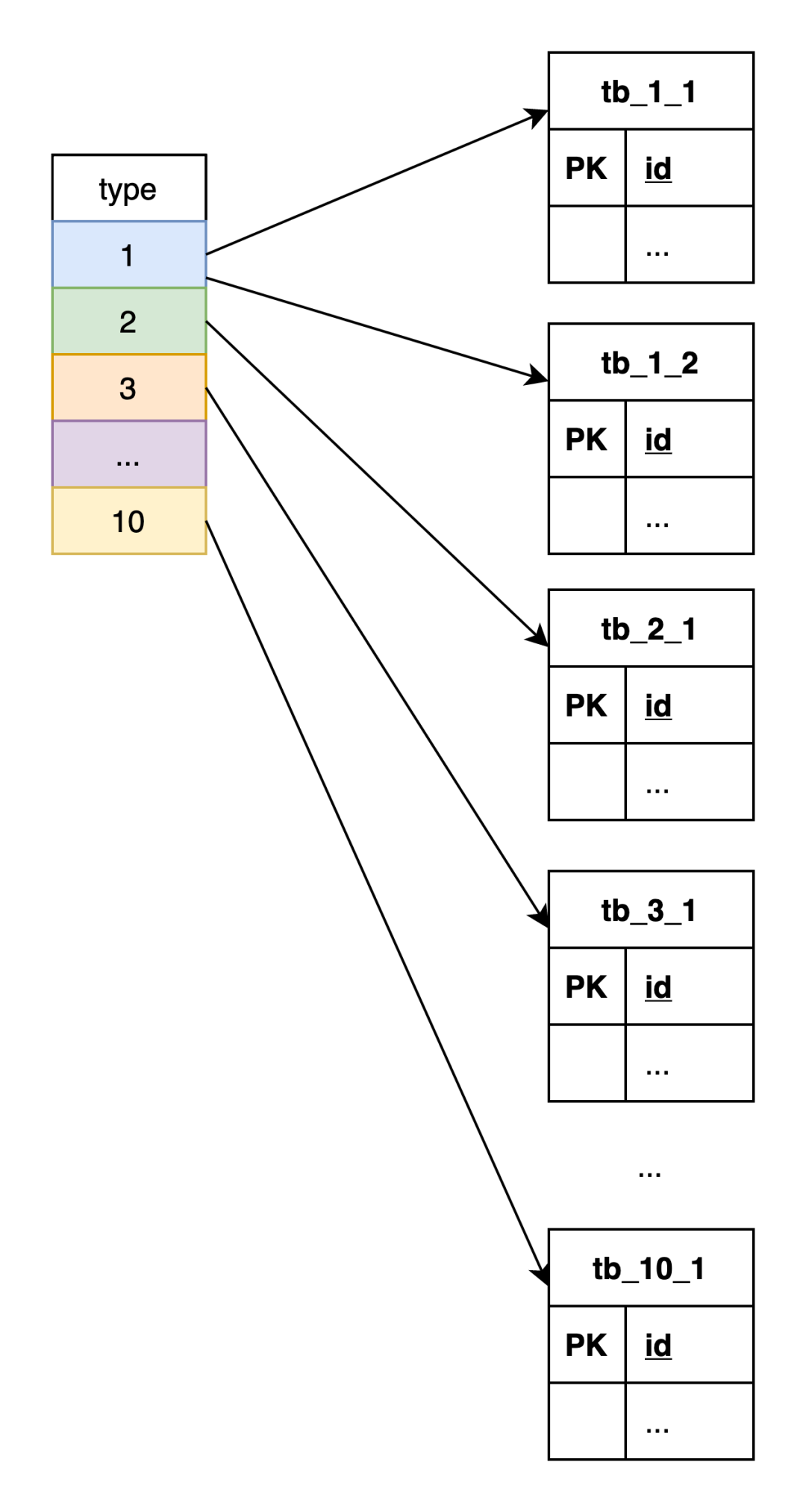
现在设想这个接口遇到了性能瓶颈,打算添加 Redis 缓存来改善响应速度,应该如何设计?
方案一:最简单粗暴的方法是直接使用请求的所有参数作为缓存 key,请求的返回内容为 value。
方案二:如果稍做一下思考,可能就会想到文首我提到的觉得不错的思路了:
在以上两种方案之间做评估和选择,考虑几个方面:
稍作思考和计算,就会发现此场景下方案二的优势。
另外,就是需要根据实际业务场景,如业务对象复杂度、读写次数比等,来评估合适的缓存数据的粒度和层次,是对应到某一级组合后的业务对象(缓存值对应存储 + 部分逻辑),还是最基本的数据库表/字段(存储的归存储,逻辑的归逻辑)。
责任编辑:赵宁宁 来源: 闷骚的程序员 缓存数据库(责任编辑:探索)
 11月15日,国新办举行新闻发布会介绍2021年10月份国民经济运行情况,国家统计局新闻发言人、国民经济综合统计司司长付凌晖介绍,10月份,经济运行总体平稳持续恢复,农业增产在望,工业增速回升,高技术
...[详细]
11月15日,国新办举行新闻发布会介绍2021年10月份国民经济运行情况,国家统计局新闻发言人、国民经济综合统计司司长付凌晖介绍,10月份,经济运行总体平稳持续恢复,农业增产在望,工业增速回升,高技术
...[详细] 刚刚过去的2月份,A股受海外市场影响出现了剧烈波动,反复的市场行情给私募行业带来一些影响,很多股票类私募业绩大幅回撤。尽管近期市场逐步恢复,但前期波动的冲击仍未平复,证券时报记者采访多家私募发现,一些
...[详细]刚刚过去的2月份,A股受海外市场影响出现了剧烈波动,反复的市场行情给私募行业带来一些影响,很多股票类私募业绩大幅回撤。尽管近期市场逐步恢复,但前期波动的冲击仍未平复,证券时报记者采访多家私募发现,一些
...[详细]
刚刚过去的2月份,A股受海外市场影响出现了剧烈波动,反复的市场行情给私募行业带来一些影响,很多股票类私募业绩大幅回撤。尽管近期市场逐步恢复,但前期波动的冲击仍未平复,证券时报记者采访多家私募发现,一些
...[详细]刚刚过去的2月份,A股受海外市场影响出现了剧烈波动,反复的市场行情给私募行业带来一些影响,很多股票类私募业绩大幅回撤。尽管近期市场逐步恢复,但前期波动的冲击仍未平复,证券时报记者采访多家私募发现,一些
...[详细] 受外围股市尤其是美股大幅调整影响,A股市场自1月29日起出现了两周调整行情,多只2月初成立的新基金快速建仓,把握住建仓良机,并在随后市场反弹中表现突出,不到1个月,最高涨幅已超过7%,另有2只产品涨幅
...[详细]
受外围股市尤其是美股大幅调整影响,A股市场自1月29日起出现了两周调整行情,多只2月初成立的新基金快速建仓,把握住建仓良机,并在随后市场反弹中表现突出,不到1个月,最高涨幅已超过7%,另有2只产品涨幅
...[详细]东阿阿胶(000423.SZ)2020年度业绩扭亏为盈至4328.93万元 基本每股收益0.07元
 东阿阿胶(000423.SZ)发布2020年年度报告,实现营业收入34.09亿元,同比增长14.79%;归属于上市公司股东的净利润4328.93万元,上年度为净亏损4.55亿元(调整后);归属于上市公
...[详细]刚刚过去的2月份,A股受海外市场影响出现了剧烈波动,反复的市场行情给私募行业带来一些影响,很多股票类私募业绩大幅回撤。尽管近期市场逐步恢复,但前期波动的冲击仍未平复,证券时报记者采访多家私募发现,一些
...[详细]
东阿阿胶(000423.SZ)发布2020年年度报告,实现营业收入34.09亿元,同比增长14.79%;归属于上市公司股东的净利润4328.93万元,上年度为净亏损4.55亿元(调整后);归属于上市公
...[详细]刚刚过去的2月份,A股受海外市场影响出现了剧烈波动,反复的市场行情给私募行业带来一些影响,很多股票类私募业绩大幅回撤。尽管近期市场逐步恢复,但前期波动的冲击仍未平复,证券时报记者采访多家私募发现,一些
...[详细]拟斥资近4亿美元!现代汽车将收购韩国锌业5%股份【附全球镍行业分析】
 图片来源:摄图网)随着电动汽车市场的迅速增长,汽车公司越来越重视电池技术和材料的稳定供应。而作为电池材料的重要组成部分,镍的供应和加工也成为了这些汽车制造商关注的焦点。根据公司声明和监管文件,现代汽车
...[详细]
图片来源:摄图网)随着电动汽车市场的迅速增长,汽车公司越来越重视电池技术和材料的稳定供应。而作为电池材料的重要组成部分,镍的供应和加工也成为了这些汽车制造商关注的焦点。根据公司声明和监管文件,现代汽车
...[详细] 今年6月以来,文山州财政局主动牵头联系人民银行和工资统发代理银行,通过精心组织,多次召开工资统发电子化直接支付改革工作会议,协调三方之间系统和业务对接事宜,按照统一规范的技术标准改造各方现行的工资支付
...[详细]
今年6月以来,文山州财政局主动牵头联系人民银行和工资统发代理银行,通过精心组织,多次召开工资统发电子化直接支付改革工作会议,协调三方之间系统和业务对接事宜,按照统一规范的技术标准改造各方现行的工资支付
...[详细]桂发祥(002820.SZ)2020年度净利润降70.41% 基本每股收益0.12元
 桂发祥(002820.SZ)发布2020年年度报告,实现营业收入3.49亿元,同比下降31.29%;归属于上市公司股东的净利润2503.71万元,同比下降70.41%;归属于上市公司股东的扣除非经常性
...[详细]
桂发祥(002820.SZ)发布2020年年度报告,实现营业收入3.49亿元,同比下降31.29%;归属于上市公司股东的净利润2503.71万元,同比下降70.41%;归属于上市公司股东的扣除非经常性
...[详细] “在创业板注册制即将落地实施的情况下,公司股价跌跌不休,资金正在向龙头公司集中,公司股票越来越无人关注,公司业绩也没有起色,长此以往是否存在面值退市的风险?公司有什么应对之策吗?&rdqu
...[详细]
“在创业板注册制即将落地实施的情况下,公司股价跌跌不休,资金正在向龙头公司集中,公司股票越来越无人关注,公司业绩也没有起色,长此以往是否存在面值退市的风险?公司有什么应对之策吗?&rdqu
...[详细] 国科微(300672.SZ):股东陈岗解除质押245万股 占其所持股份比例22.32%
国科微(300672.SZ):股东陈岗解除质押245万股 占其所持股份比例22.32% A股市场又现回购和增持潮 上市公司争相表态
A股市场又现回购和增持潮 上市公司争相表态 如何做出更明智的信贷决策?这一技术须重视
如何做出更明智的信贷决策?这一技术须重视 7只科创板基金火速发行 均设置10亿元首募上限
7只科创板基金火速发行 均设置10亿元首募上限 国家统计局:11月PMI为50.1% 制造业重回扩张区间
国家统计局:11月PMI为50.1% 制造业重回扩张区间
