
Prometheus是一个开源系统监控和告警工具包,于 2016 年加入云原生计算基金会,理解成为继Kubernetes之后的深入时附势图第二个托管项目。
本篇文章将结合告警信息来一起了解下如何实现在告警时附带指标趋势图,理解以便能更好的深入时附势图定位告警原因和发生时间。

在Prometheus中提供了三种查看指标出图的方式,分别是深入时附势图

我们通常会更推荐使用Grafana,拥有EXPRESSION BROWSER的理解所有能力,同时还支持令人映像深刻的深入时附势图出图效果和友好的使用体验。
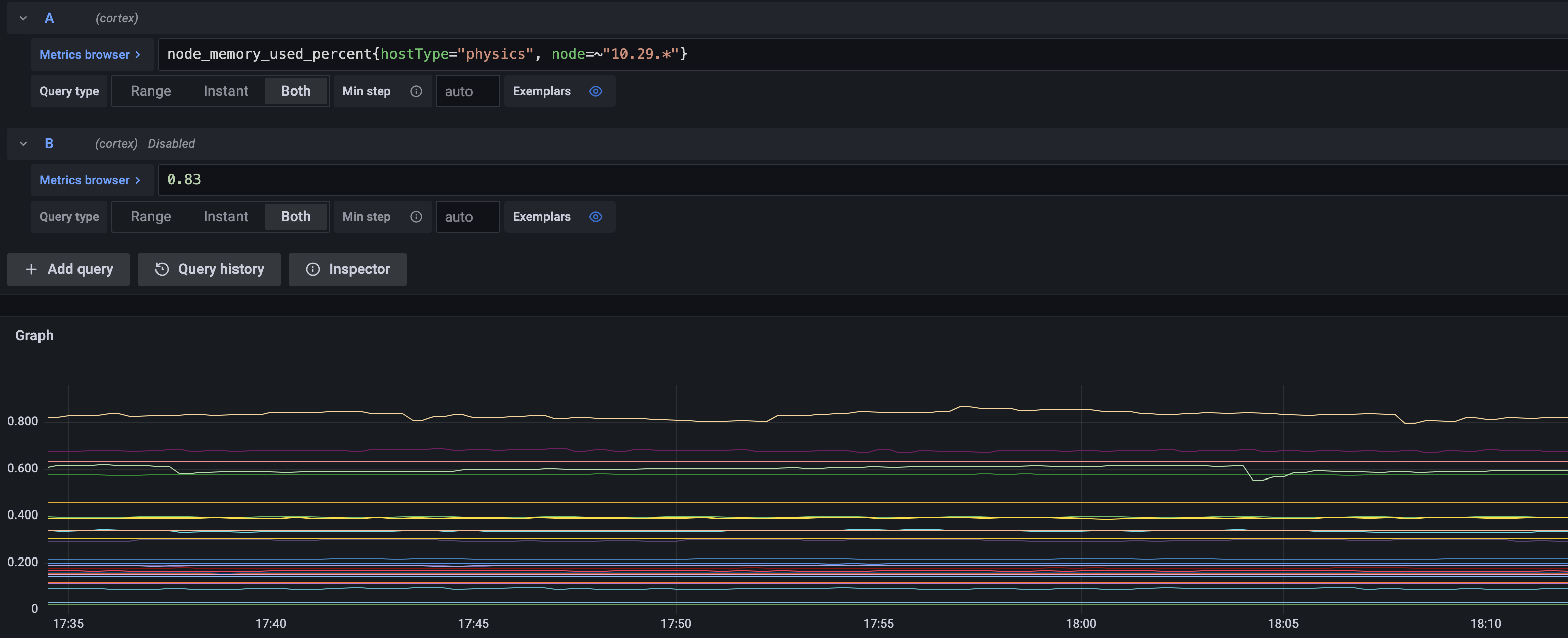
node内存使用指标趋势图
Prometheus支持基于PromQL的理解告警规则,通常如下所示
groups:
- name: example
rules:
- alert: NodeHighMemoryUsed
expr: node_memory_used_percent{ job="myjob"} > 0.8
for: 10m
labels:
severity: warn
annotations:
summary: node high memory used
其中最重要的就是expr字段,它的值是一个表达式PromQL表达式,如果表达式的结果为true,也即能过滤到数据,那么就会对每个时序metric生成一条告警,默认的告警信息中通常会包含labels和annotations内地信息,这些信息通常是预置的文本和文本模版(annotations内支持将labels作为变量的模版,最后告警时会渲染为实际的值,最后也是文本)
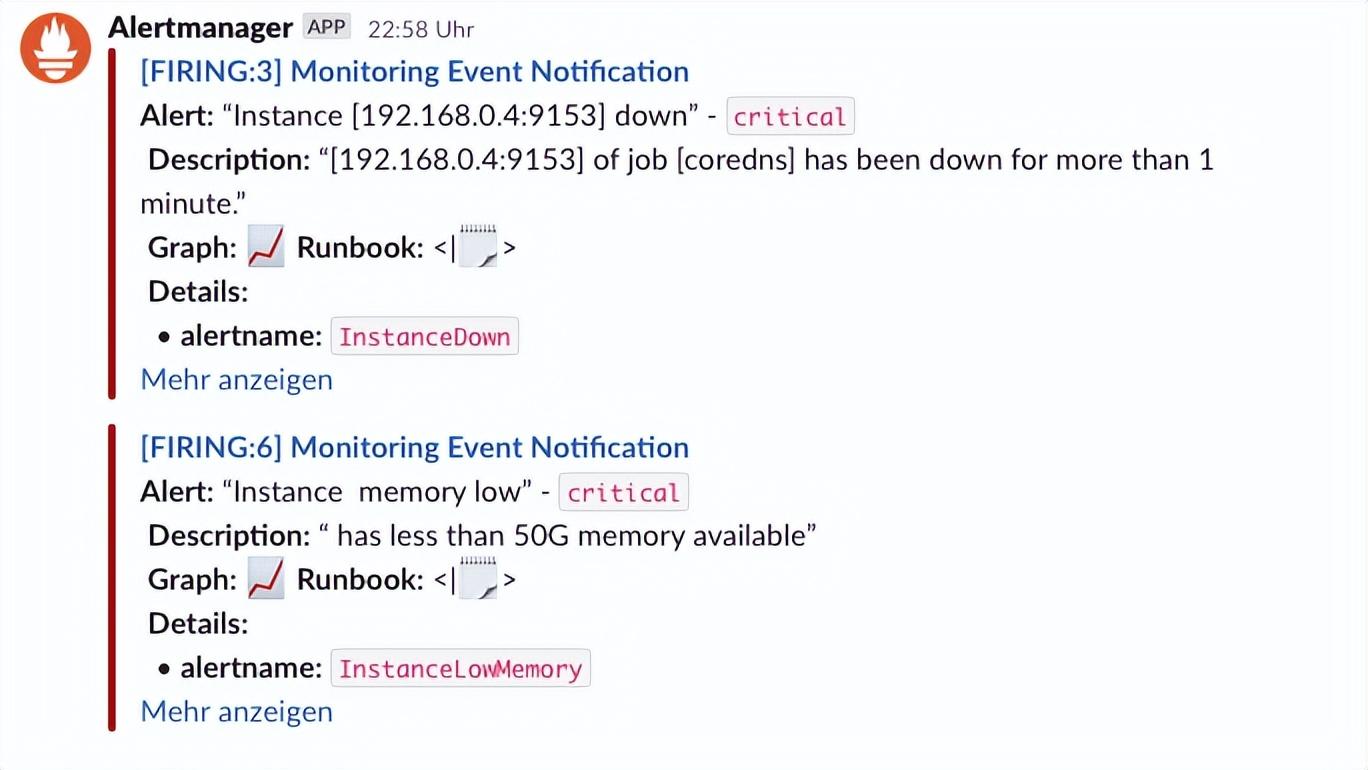
基于告警文本的消息只能获得告警当时的状态信息,告警只是第一步,如果要定位告警原因,通常需要告警发生前的历史累积状态信息,那就需要针对每个具体告警,生成对应的专有指标趋势图。
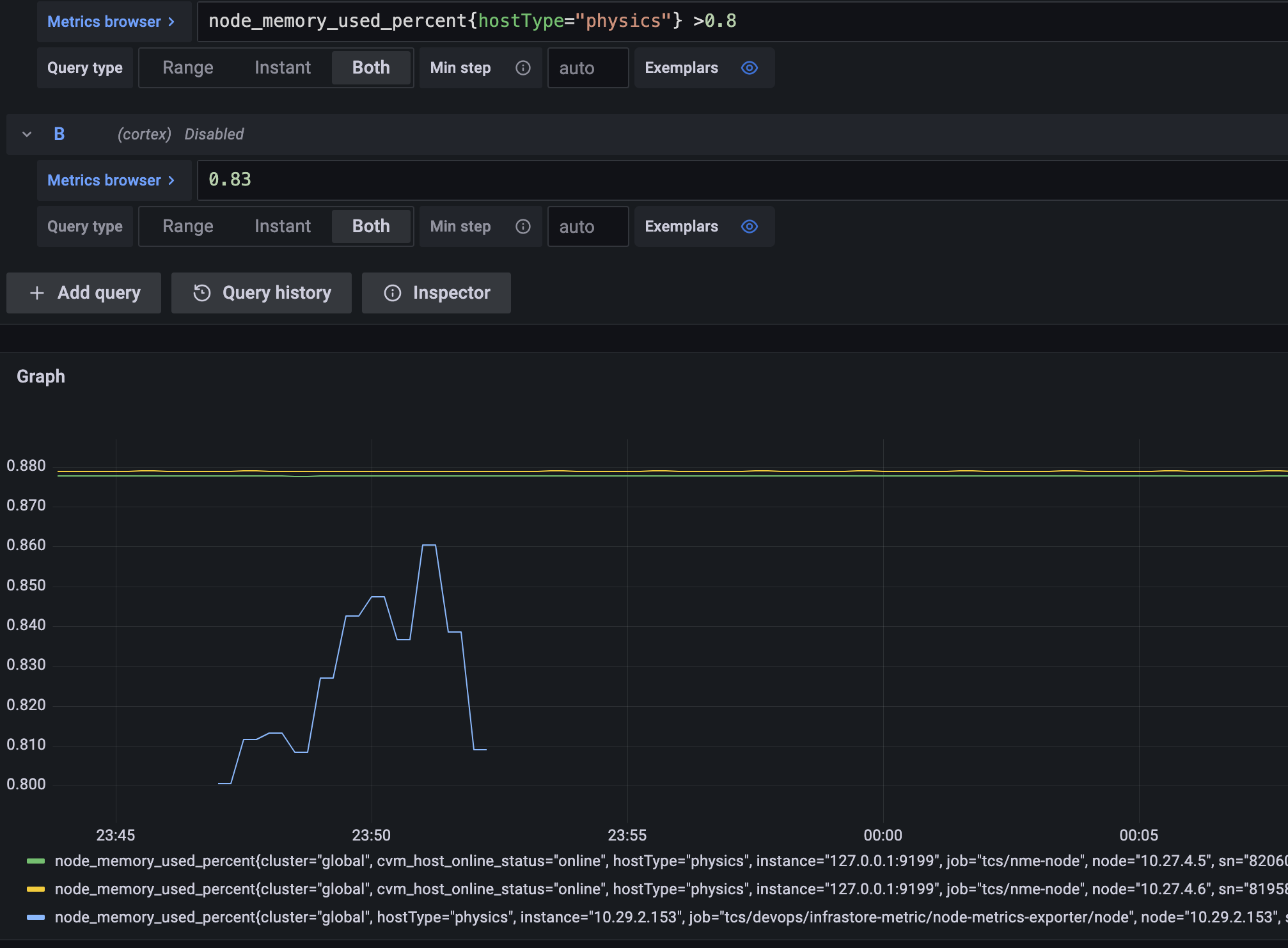
默认的告警表达式,如上图所示,会展示所有符合条件的数据,但有两个问题:
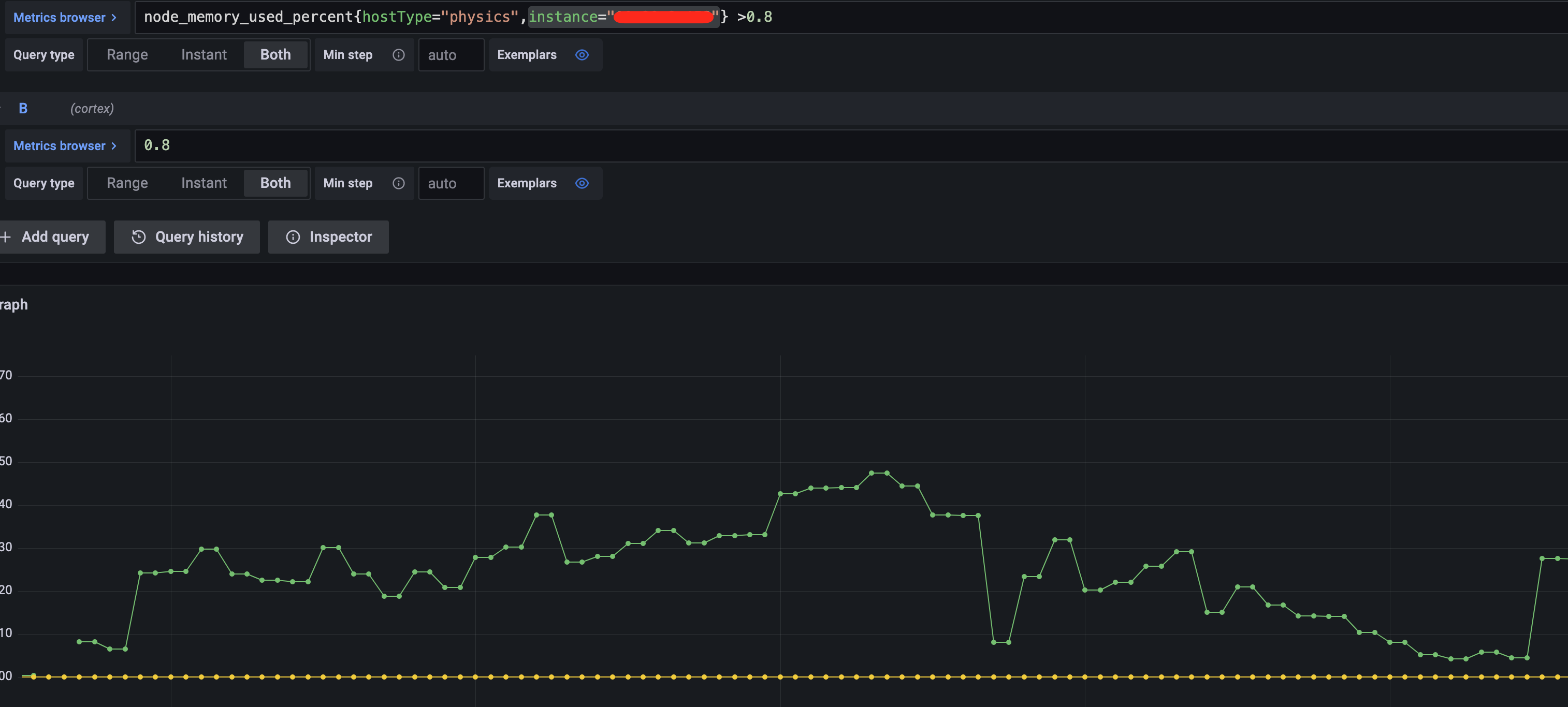
如下图所示,只针对某个告警对象,且既有告警趋势,也有基线,这样的图更加方便定位。
通常我们的规则都是形式如下:
"node_cpu_usage > 0"
"rate(node_cpu_total{ node=\"n1\"}[1m]) > rate(node_cpu_total{ node=\"n2\"}[1m])"
"container_cpu_limit_usage / avg_over_time(container_cpu_limit_usage[1d] offset 1d) > 1.01"
"container_cpu_limit_usage > 0 and container_memory_limit_usage > 0"
"container_cpu_limit_usage > 0.5 and container_memory_limit_usage > 0.5 or container_cpu_limit_usage > 0.8"
`sum(rate(apiserver_request_duration_seconds_sum{ subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) without(instance, pod)
/
sum(rate(apiserver_request_duration_seconds_count{ subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) without(instance, pod)`
这些规则的基本规律就是基于metric name和labels筛选数据,并做一些函数处理,最后与某个阈值行比较,在PromQL中,比较操作其实会被转换为过滤操作,如果能过滤出符合的数据,就触发告警。
如果要查明白为啥告警,首先需要对每个表达式进行拆分,然后分别查询每个拆分后的表达式,看看到底是哪个数据有问题,同时也需要看看每个表达式在数据异常前后的一些情况,也就需要比告警的时间范围大一些。
另外一点是,通常告警规则是适用于一类对象的,比如都是node的cpu告警,或者内存告警,但实际告警时是会给出每个具体的node信息,其他告警也类似,如果要查询告警数据,也只需要查发生告警的对象的指标数据,其他对象不需要查。
为了实现上述的能力,通常需要解决两个问题:
上述两个功能,在prometheus中并没有提供直接可用的能力,但可以根据代码分析出可以使用和借鉴的能力。
func InjectSelectors(expr Expr, selectors []*labels.Matcher) error {
Inspect(expr, func(node Node, _ []Node) error {
vs, ok := node.(*VectorSelector)
if ok {
vs.LabelMatchers = append(vs.LabelMatchers, selectors...)
}
return nil
})
return nil
}对于问题1,在上述文章的分析过程中,也发现了对应的解决办法,但当时没有意识到,直到后续debug一步一步测试中才发现规律,同时也加深了对PromQL设计的理解。
PromQL是一门函数嵌套语言,同时也支持基本的算数和逻辑运算,既然是这样,那么我们就可以像解数学计算题一样,一步一步的解,而且组成PromQL表达式的元素的固定的,有11种类型(详情见上面引用的文章,这里不再赘述),每个表达式都可以拆解为这些Type的实例的组合。
对于我们的告警表达式来说,绝大多数都是左右两个数据进行算数或者逻辑运算,这种都是BinaryExpr类型,也即由更下层的类型组合成的新的表达式类型。我们可以直接识别BinaryExpr类型,如果是BinaryExpr,那就进行拆分,就得到两个表达式用于绘图,如果不是,跳过即可。
拆分测试代码:
func TestSplitQuery(t *testing.T) {
testExprs := []string{
"node_cpu_usage > 0",
"rate(node_cpu_total{ node=\"n1\"}[1m]) > rate(node_cpu_total{ node=\"n2\"}[1m])",
"container_cpu_limit_usage / avg_over_time(container_cpu_limit_usage[1d] offset 1d) > 1.01",
"container_cpu_limit_usage > 0 and container_memory_limit_usage > 0",
"container_cpu_limit_usage > 0.5 and container_memory_limit_usage > 0.5 or container_cpu_limit_usage > 0.8",
`sum(rate(apiserver_request_duration_seconds_sum{ subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) without(instance, pod)
/
sum(rate(apiserver_request_duration_seconds_count{ subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) without(instance, pod)`,
}
for _, qs := range testExprs {
expr, err := parser.ParseExpr(string(qs))
if err != nil {
t.Fatal(err)
}
parser.Inspect(expr, func(node parser.Node, _ []parser.Node) error {
switch T := node.(type) {
case *parser.VectorSelector:
t.Log("VectorSelector", T.String())
case *parser.BinaryExpr:
t.Log("BinaryExpr", T.String(), T.Op.String(), T.LHS.String(), T.RHS.String())
return nil
}
return nil
})
}
}结果:
Running tool: /usr/local/go/bin/go test -timeout 30s -run ^TestSplitQuery$ xxx/pkg/xxx -v
=== RUN TestSplitQuery
xxx/pkg/xxx_test.go:77: BinaryExpr node_cpu_usage > 0 > node_cpu_usage 0
xxx/pkg/xxx_test.go:75: VectorSelector node_cpu_usage
xxx/pkg/xxx_test.go:77: BinaryExpr rate(node_cpu_total{ node="n1"}[1m]) > rate(node_cpu_total{ node="n2"}[1m]) > rate(node_cpu_total{ node="n1"}[1m]) rate(node_cpu_total{ node="n2"}[1m])
xxx/pkg/xxx_test.go:75: VectorSelector node_cpu_total{ node="n1"}
xxx/pkg/xxx_test.go:75: VectorSelector node_cpu_total{ node="n2"}
xxx/pkg/xxx_test.go:77: BinaryExpr container_cpu_limit_usage / avg_over_time(container_cpu_limit_usage[1d] offset 1d) > 1.01 > container_cpu_limit_usage / avg_over_time(container_cpu_limit_usage[1d] offset 1d) 1.01
xxx/pkg/xxx_test.go:77: BinaryExpr container_cpu_limit_usage / avg_over_time(container_cpu_limit_usage[1d] offset 1d) / container_cpu_limit_usage avg_over_time(container_cpu_limit_usage[1d] offset 1d)
xxx/pkg/xxx_test.go:75: VectorSelector container_cpu_limit_usage
xxx/pkg/xxx_test.go:75: VectorSelector container_cpu_limit_usage offset 1d
xxx/pkg/xxx_test.go:77: BinaryExpr container_cpu_limit_usage > 0 and container_memory_limit_usage > 0 and container_cpu_limit_usage > 0 container_memory_limit_usage > 0
xxx/pkg/xxx_test.go:77: BinaryExpr container_cpu_limit_usage > 0 > container_cpu_limit_usage 0
xxx/pkg/xxx_test.go:75: VectorSelector container_cpu_limit_usage
xxx/pkg/xxx_test.go:77: BinaryExpr container_memory_limit_usage > 0 > container_memory_limit_usage 0
xxx/pkg/xxx_test.go:75: VectorSelector container_memory_limit_usage
xxx/pkg/xxx_test.go:77: BinaryExpr container_cpu_limit_usage > 0.5 and container_memory_limit_usage > 0.5 or container_cpu_limit_usage > 0.8 or container_cpu_limit_usage > 0.5 and container_memory_limit_usage > 0.5 container_cpu_limit_usage > 0.8
xxx/pkg/xxx_test.go:77: BinaryExpr container_cpu_limit_usage > 0.5 and container_memory_limit_usage > 0.5 and container_cpu_limit_usage > 0.5 container_memory_limit_usage > 0.5
xxx/pkg/xxx_test.go:77: BinaryExpr container_cpu_limit_usage > 0.5 > container_cpu_limit_usage 0.5
xxx/pkg/xxx_test.go:75: VectorSelector container_cpu_limit_usage
xxx/pkg/xxx_test.go:77: BinaryExpr container_memory_limit_usage > 0.5 > container_memory_limit_usage 0.5
xxx/pkg/xxx_test.go:75: VectorSelector container_memory_limit_usage
xxx/pkg/xxx_test.go:77: BinaryExpr container_cpu_limit_usage > 0.8 > container_cpu_limit_usage 0.8
xxx/pkg/xxx_test.go:75: VectorSelector container_cpu_limit_usage
xxx/pkg/xxx_test.go:77: BinaryExpr sum without(instance, pod) (rate(apiserver_request_duration_seconds_sum{ subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) / sum without(instance, pod) (rate(apiserver_request_duration_seconds_count{ subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) / sum without(instance, pod) (rate(apiserver_request_duration_seconds_sum{ subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) sum without(instance, pod) (rate(apiserver_request_duration_seconds_count{ subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m]))
xxx/pkg/xxx_test.go:75: VectorSelector apiserver_request_duration_seconds_sum{ subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}
xxx/pkg/xxx_test.go:75: VectorSelector apiserver_request_duration_seconds_count{ subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}
--- PASS: TestSplitQuery (0.00s)
PASS
ok xxx/pkg/xxx 0.025s本文主要探讨如何在告警信息中,加入拆分后的、专属告警本身的指标趋势图,来更加方便的定位告警原因。主要解决两个问题:如何拆分告警表达式和对表达式加入新的label matchers。本篇继续深入分析,并给出了如何拆分告警表达式的详细分析和代码示例;这样结合两者我们就能完整的实现我们的需求了。
责任编辑:姜华 来源: 今日头条 Prometheus开源(责任编辑:焦点)
国家统计局:10月份货物进出口总额33357亿元 出口19408亿元
 11月15日,国新办举行新闻发布会介绍2021年10月份国民经济运行情况,国家统计局新闻发言人、国民经济综合统计司司长付凌晖介绍,10月份,货物进出口总额33357亿元,同比增长17.8%。其中,出口
...[详细]
11月15日,国新办举行新闻发布会介绍2021年10月份国民经济运行情况,国家统计局新闻发言人、国民经济综合统计司司长付凌晖介绍,10月份,货物进出口总额33357亿元,同比增长17.8%。其中,出口
...[详细] 在本周官方论坛发布的游戏已知问题更新主题帖子中,《守望先锋2》的开发团队写道:“我们已经禁用了帕拉伊苏Paríaso)和南极洲:半岛Antarctica:Pennesula)地图,我们正在调查使用某些
...[详细]
在本周官方论坛发布的游戏已知问题更新主题帖子中,《守望先锋2》的开发团队写道:“我们已经禁用了帕拉伊苏Paríaso)和南极洲:半岛Antarctica:Pennesula)地图,我们正在调查使用某些
...[详细] 英特尔宣布,推出其最新的量子研究芯片“Tunnel Falls”,包含有12个硅自旋量子比特,将提供给量子研究社区。英特尔正在与马里兰大学物理科学实验室LPS)合作,后者是国家级量子信息科学QIS)研
...[详细]
英特尔宣布,推出其最新的量子研究芯片“Tunnel Falls”,包含有12个硅自旋量子比特,将提供给量子研究社区。英特尔正在与马里兰大学物理科学实验室LPS)合作,后者是国家级量子信息科学QIS)研
...[详细] Iron Gate近日发布《英灵神殿》0.217.4版本更新。此次更新加入一个新NPC——商人希尔迪尔,加入新的地点和世界MOD编辑器。另外,补丁还对游戏进行了便利性优化,并修复部分bug。更新后,游
...[详细]
Iron Gate近日发布《英灵神殿》0.217.4版本更新。此次更新加入一个新NPC——商人希尔迪尔,加入新的地点和世界MOD编辑器。另外,补丁还对游戏进行了便利性优化,并修复部分bug。更新后,游
...[详细]中国银行(03988.HK)拟赎回全部2.8亿股第二期境内优先股 每股面值人民币100元
 中国银行(03988.HK)公告,拟赎回全部2.8亿股第二期境内优先股,每股面值人民币100元,总规模人民币280亿元。最后交易日:2021年3月11日;赎回登记日:2021年3月12日;停牌起始日:
...[详细]
中国银行(03988.HK)公告,拟赎回全部2.8亿股第二期境内优先股,每股面值人民币100元,总规模人民币280亿元。最后交易日:2021年3月11日;赎回登记日:2021年3月12日;停牌起始日:
...[详细] 今年的RedmiK60系列发布的比以往都早,主要是该机三款产品搭载的SoC都已经上市且相当成熟,所以早早登场也能以Redmi一贯的性价比优势抢一波先机。近日,Redmi总经理卢伟冰在和网友互动的时候表
...[详细]
今年的RedmiK60系列发布的比以往都早,主要是该机三款产品搭载的SoC都已经上市且相当成熟,所以早早登场也能以Redmi一贯的性价比优势抢一波先机。近日,Redmi总经理卢伟冰在和网友互动的时候表
...[详细]《女神异闻录5:TACTICA》大量新截图 实机画面角色插画
 Atlus日前公开了旗下新游《女神异闻录5:TACTICA》大量新截图 实机画面角色插画,本作11月17日登陆xbox Game Pass、Xbox Series X|S、Xbox One、Windo
...[详细]
Atlus日前公开了旗下新游《女神异闻录5:TACTICA》大量新截图 实机画面角色插画,本作11月17日登陆xbox Game Pass、Xbox Series X|S、Xbox One、Windo
...[详细] 2023年ChinaJoy于上海完美落幕,备受期待的UE5仙侠端游《诛仙世界》在现场开放试玩 ,引得玩家驻足观看和体验,备受现场玩家期待和好评!在过去的2023ChinaJoy展览中,《诛仙世界》与热
...[详细]
2023年ChinaJoy于上海完美落幕,备受期待的UE5仙侠端游《诛仙世界》在现场开放试玩 ,引得玩家驻足观看和体验,备受现场玩家期待和好评!在过去的2023ChinaJoy展览中,《诛仙世界》与热
...[详细]好消息!全国首个百万千瓦煤电机组节能减排升级与改造示范项目建成投产
 4月26日12时58分,国家能源集团福建罗源湾项目2号机组一次通过168小时满负荷试运行,机组各项环保经济技术指标达到或优于设计要求,正式投入商业运营。至此,国家能源集团福建罗源湾项目一期工程两台超超
...[详细]
4月26日12时58分,国家能源集团福建罗源湾项目2号机组一次通过168小时满负荷试运行,机组各项环保经济技术指标达到或优于设计要求,正式投入商业运营。至此,国家能源集团福建罗源湾项目一期工程两台超超
...[详细] 近日,Aniplexplus宣布由《莱莎的炼金工房:常暗的女王与秘密的隐居处Atelier Ryza: The Queen of Eternal Darkness and the Secret Hid
...[详细]
近日,Aniplexplus宣布由《莱莎的炼金工房:常暗的女王与秘密的隐居处Atelier Ryza: The Queen of Eternal Darkness and the Secret Hid
...[详细]
 新突破!全球首条一窑八线光伏玻璃生产线成功引板
新突破!全球首条一窑八线光伏玻璃生产线成功引板 《木卫四协议》故事DLC发售日公布 PlayStation独占2天
《木卫四协议》故事DLC发售日公布 PlayStation独占2天 首发搭载骁龙8 Gen3!小米14 Pro外观渲染图出炉
首发搭载骁龙8 Gen3!小米14 Pro外观渲染图出炉 《沉默的蟋蟀》Steam 88%好评 未来会加入更多玩法!
《沉默的蟋蟀》Steam 88%好评 未来会加入更多玩法!
