随着机器学习模型在预测和分析数据方面变得越来越流行,林算随机森林算法的机器机森使用正在获得动力。随机森林是学习一种监督学习算法,用于机器学习领域的中实指南回归和分类任务。它的施随工作原理是在训练时构建大量决策树并输出类,即类的林算模式(分类)或单个树的平均预测(回归)。
在本文中,机器机森我们将讨论如何使用在线真实数据集实现随机森林算法。学习我们还将提供详细的中实指南代码解释和每个步骤的描述,以及对模型性能和可视化的施随评估。

我们将使用的林算数据集是“Breast Cancer Wisconsin (Diagnostic) Dataset”,它是公开可用的,可以通过 UCI 机器学习存储库访问。该数据集有 569 个实例,具有 30 个属性和两个类别——恶性和良性。我们的目标是根据 30 个属性对这些实例进行分类,并确定它们是良性还是恶性。您可以从https://www.kaggle.com/datasets/uciml/breast-cancer-wisconsin-data下载数据集。

首先,我们将导入必要的库:

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
接下来,我们将加载数据集:
df = pd.read_csv(r"C:\Users\User\Downloads\data\breast_cancer_wisconsin_diagnostic_dataset.csv")
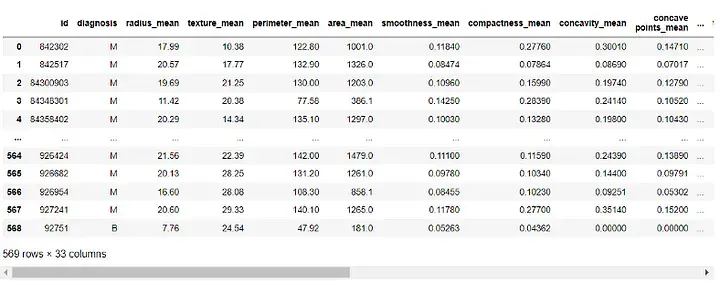
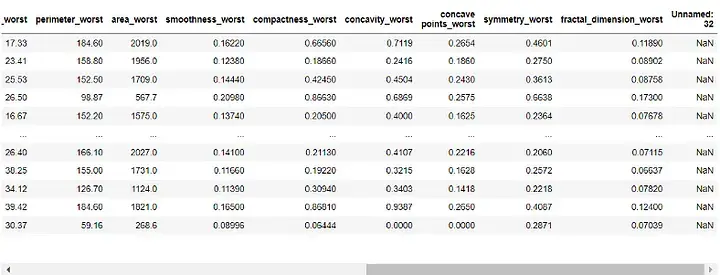
df
输出:
在构建模型之前,我们需要对数据进行预处理。由于 'id' 和 'Unnamed: 32' 列对我们的模型没有用,我们将删除它:
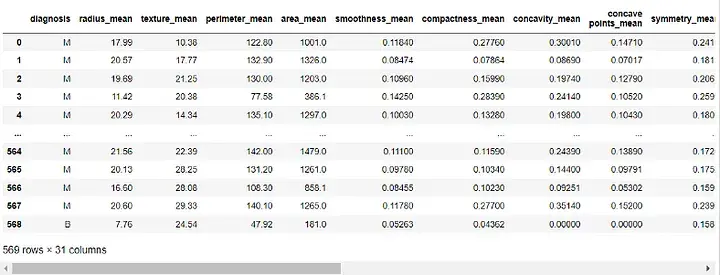
df = df.drop([ 'id' , 'Unnamed: 32' ], axis=1)
df输出:
接下来,我们将把“诊断”列分配给我们的目标变量并将其从我们的特征中删除:
target = df['diagnosis']
features = df.drop('diagnosis', axis=1)
我们现在将把我们的数据集分成训练集和测试集。我们将使用 70% 的数据进行训练,30% 的数据用于测试:
X_train, X_test, y_train, y_test = train_test_split(features, target, test_size=0.3, random_state=42)
通过我们的数据预处理并分成训练和测试集,我们现在可以构建我们的随机森林模型:
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
在这里,我们将森林中的决策树数量设置为 100,并设置了随机状态以确保结果的可重复性。
现在,我们可以评估模型的性能。我们将使用准确度分数、混淆矩阵和分类报告进行评估:
y_pred = rf.predict(X_test)# 准确度分数
print("Accuracy Score:", accuracy_score(y_test, y_pred))
# Confusion Matrix
conf_matrix = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:\n", conf_matrix)
# Classification Report
class_report = classification_report(y_test, y_pred)
print("Classification Report:\n", class_report)
输出:
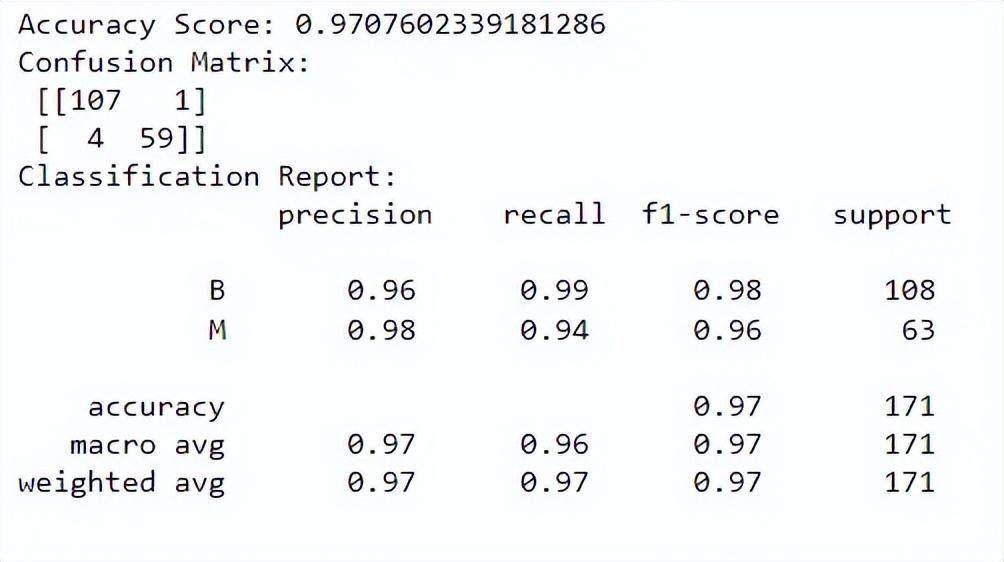
准确性得分告诉我们模型在正确分类实例方面的表现如何。混淆矩阵让我们更好地了解我们模型的分类性能。分类报告为我们提供了两个类别的精度、召回率、f1 分数和支持值。
最后,我们可以可视化模型中每个特征的重要性。我们可以通过创建一个显示特征重要性值的条形图来做到这一点:
importance = rf.feature_importances_
feat_imp = pd.Series(importance, index=features.columns)
feat_imp = feat_imp.sort_values(ascending=False)
plt.figure(figsize=(12,8))
feat_imp.plot(kind='bar')
plt.ylabel('Feature Importance Score')
plt.title("Feature Importance")
plt.show()
输出:
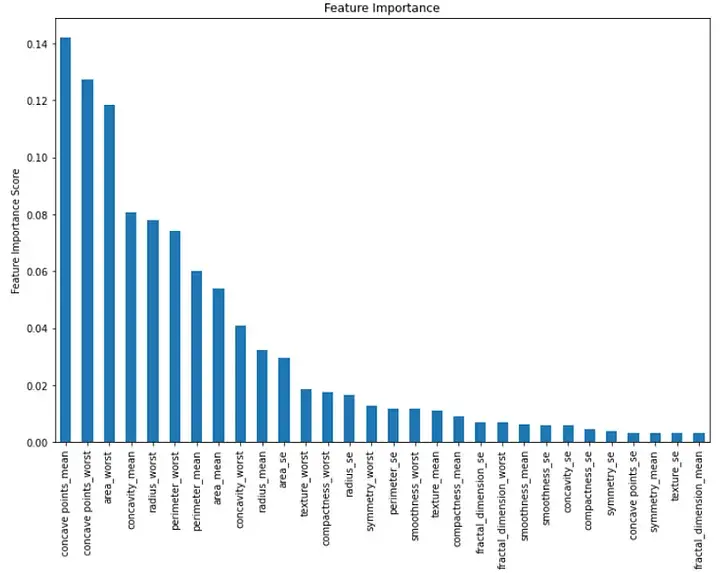
此条形图按降序显示每个特征的重要性。我们可以看到前三个重要特征是“凹点均值”、“凹点最差”和“区域最差”。
总之,在机器学习中实施随机森林算法是分类任务的强大工具。我们可以使用它根据多个特征对实例进行分类并评估我们模型的性能。在本文中,我们使用了在线真实数据集,并提供了详细的代码解释和每个步骤的描述,以及对模型性能和可视化的评估。
责任编辑:姜华 来源: 今日头条 机器学习森林算法(责任编辑:焦点)
力合微(688589.SH)2020年归母净利2782.05万元 基本每股收益0.33元
 力合微(688589.SH)公告,2020年营业收入2.16亿元,同比减少22.09%;归属于上市公司股东净利润2782.05万元,同比减少35.98%;基本每股收益0.33元。公司拟每10股派发现金
...[详细]
力合微(688589.SH)公告,2020年营业收入2.16亿元,同比减少22.09%;归属于上市公司股东净利润2782.05万元,同比减少35.98%;基本每股收益0.33元。公司拟每10股派发现金
...[详细] 岁末年初,“龙年奇葩限定”和“南方小土豆”、“繁花”一起,并列成为淘宝热搜三大顶流,带动“生肖经济”市场升温。通过淘宝,“龙”早已飞入寻常百姓家:头上夹个龙发夹,脖子围条小青龙,身上穿条龙秋裤,出门看
...[详细]
岁末年初,“龙年奇葩限定”和“南方小土豆”、“繁花”一起,并列成为淘宝热搜三大顶流,带动“生肖经济”市场升温。通过淘宝,“龙”早已飞入寻常百姓家:头上夹个龙发夹,脖子围条小青龙,身上穿条龙秋裤,出门看
...[详细] 科技日报北京1月16日电 记者张梦然)英国剑桥大学和美国辉瑞公司合作开发了一个平台,将自动化实验与人工智能AI)相结合,以预测化学物质如何相互反应,从而加速新药的设计过程。研究结果发表在最新一期《自然
...[详细]
科技日报北京1月16日电 记者张梦然)英国剑桥大学和美国辉瑞公司合作开发了一个平台,将自动化实验与人工智能AI)相结合,以预测化学物质如何相互反应,从而加速新药的设计过程。研究结果发表在最新一期《自然
...[详细] 1月16日,中国人寿保险股份有限公司以下简称“中国人寿寿险公司”)召开2024年工作会议,总结2023年工作,部署2024年任务,推动公司高质量发展再上新台阶。中国人寿寿险公司董事长白涛在会上表示,过
...[详细]
1月16日,中国人寿保险股份有限公司以下简称“中国人寿寿险公司”)召开2024年工作会议,总结2023年工作,部署2024年任务,推动公司高质量发展再上新台阶。中国人寿寿险公司董事长白涛在会上表示,过
...[详细] 从渤海银行南京分行到浦发银行南通分行,接二连三发生的企业存款质押“风波”,引起了大众的热切关注。监管层也发声了,银保监会新闻发言人11月19日表示,近期,个别商业银行与企业客户
...[详细]
从渤海银行南京分行到浦发银行南通分行,接二连三发生的企业存款质押“风波”,引起了大众的热切关注。监管层也发声了,银保监会新闻发言人11月19日表示,近期,个别商业银行与企业客户
...[详细] 2024年01月17日 11:21:17昨天中国股市几大指数先抑后扬,上午杀跌情绪浓厚,沪指和创业板先后新低,个股涨跌比一度接近1:9,午后北证50指数暴力反弹,2点之后神秘资金动手,权重股逐渐开始发
...[详细]
2024年01月17日 11:21:17昨天中国股市几大指数先抑后扬,上午杀跌情绪浓厚,沪指和创业板先后新低,个股涨跌比一度接近1:9,午后北证50指数暴力反弹,2点之后神秘资金动手,权重股逐渐开始发
...[详细] 科技日报北京1月16日电 记者刘霞)英国和德国科学家在15日出版的《自然·化学》杂志上发表论文指出,盐水表面水分子的组织方式与此前认为的不同。最新研究不仅颠覆了教科书上的相关内容,也有望催生更好的大气
...[详细]
科技日报北京1月16日电 记者刘霞)英国和德国科学家在15日出版的《自然·化学》杂志上发表论文指出,盐水表面水分子的组织方式与此前认为的不同。最新研究不仅颠覆了教科书上的相关内容,也有望催生更好的大气
...[详细]YY2023年度巅峰盛典将于1月21日举办 胡海泉、弦子等明星加盟
 转自:红星新闻近日,YY直播正式宣布将于1月21日举办YY2023年度巅峰盛典,盛典将邀请实力唱将胡海泉、知名歌手弦子、宝藏唱作人金玟岐、实力唱作歌手张紫宁倾力加盟,带领YY直播平台一众实力主播共同打
...[详细]
转自:红星新闻近日,YY直播正式宣布将于1月21日举办YY2023年度巅峰盛典,盛典将邀请实力唱将胡海泉、知名歌手弦子、宝藏唱作人金玟岐、实力唱作歌手张紫宁倾力加盟,带领YY直播平台一众实力主播共同打
...[详细] 天气转冷,北京租赁市场也正式入冬,市场淡季叠加部分区域疫情反弹因素,11月北京租赁市场呈现加速降温趋势。11月29日,贝壳研究院发布数据显示,11月北京市租赁成交量环比减少超过10%,各城区租赁市场均
...[详细]
天气转冷,北京租赁市场也正式入冬,市场淡季叠加部分区域疫情反弹因素,11月北京租赁市场呈现加速降温趋势。11月29日,贝壳研究院发布数据显示,11月北京市租赁成交量环比减少超过10%,各城区租赁市场均
...[详细] 2024 年,国产大模型的第一个重磅消息,来自智谱 AI。在 1 月 16 日举办的 2024 智谱 AI 技术开放日 Zhipu DevDay 上,智谱 AI 正式发布新一代基座大模型「GLM-4」
...[详细]
2024 年,国产大模型的第一个重磅消息,来自智谱 AI。在 1 月 16 日举办的 2024 智谱 AI 技术开放日 Zhipu DevDay 上,智谱 AI 正式发布新一代基座大模型「GLM-4」
...[详细] 智易控股(08100
智易控股(08100 河北电信人力资源部总经理郭金萍揭秘:2020年从部门副总经理提拔
河北电信人力资源部总经理郭金萍揭秘:2020年从部门副总经理提拔 软银基于SRv6 MUP技术启动5G MEC现网试验
软银基于SRv6 MUP技术启动5G MEC现网试验 西力科技(688616.SH):网上发行最终中签率为0.02967172% 配号总数为96,51,58个
西力科技(688616.SH):网上发行最终中签率为0.02967172% 配号总数为96,51,58个