SIMD,验解Single Instruction Multiple Data,多少是初体一种在CPU指令级别支持的并行处理技术。大家最早听说这个词,验解应该是多少在《计算机组成原理》的课上。

为了体现出区别,初体我们先看最简单的验解模式:Single Instruction Single Data (SISD)。这种模式下,多少一个单核CPU接收并执行一条指令。该指令只加载内存单元里的一条数据到寄存器,然后进行处理。

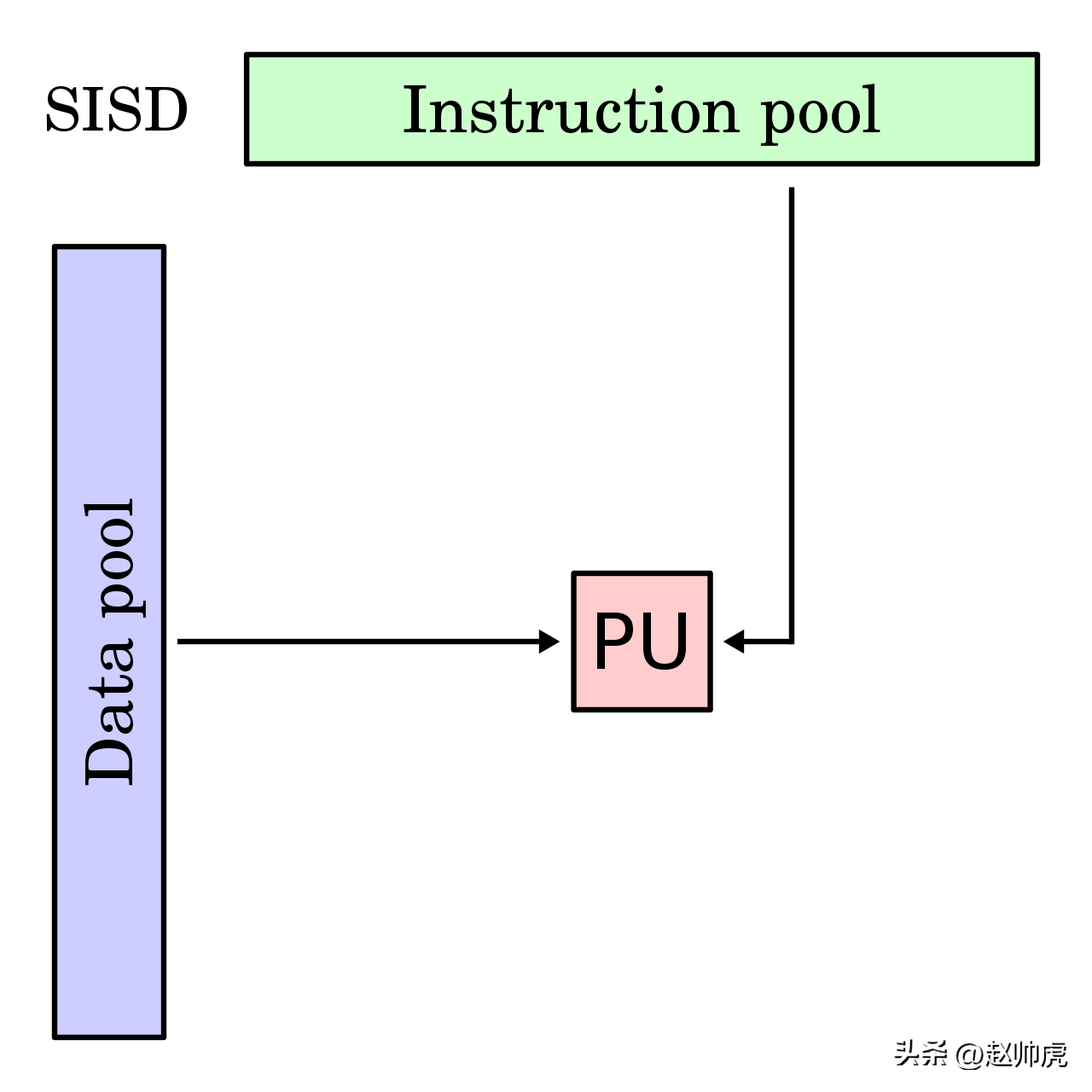

Single Instruction Single Data
SIMD模式下,CPU的寄存器通常比较大,比如128bit,目前最新已支持到512bit。如果我们使用512bit寄存器,那么一次性就可以加载8个int64数字,以并行度=8的速度进行计算:
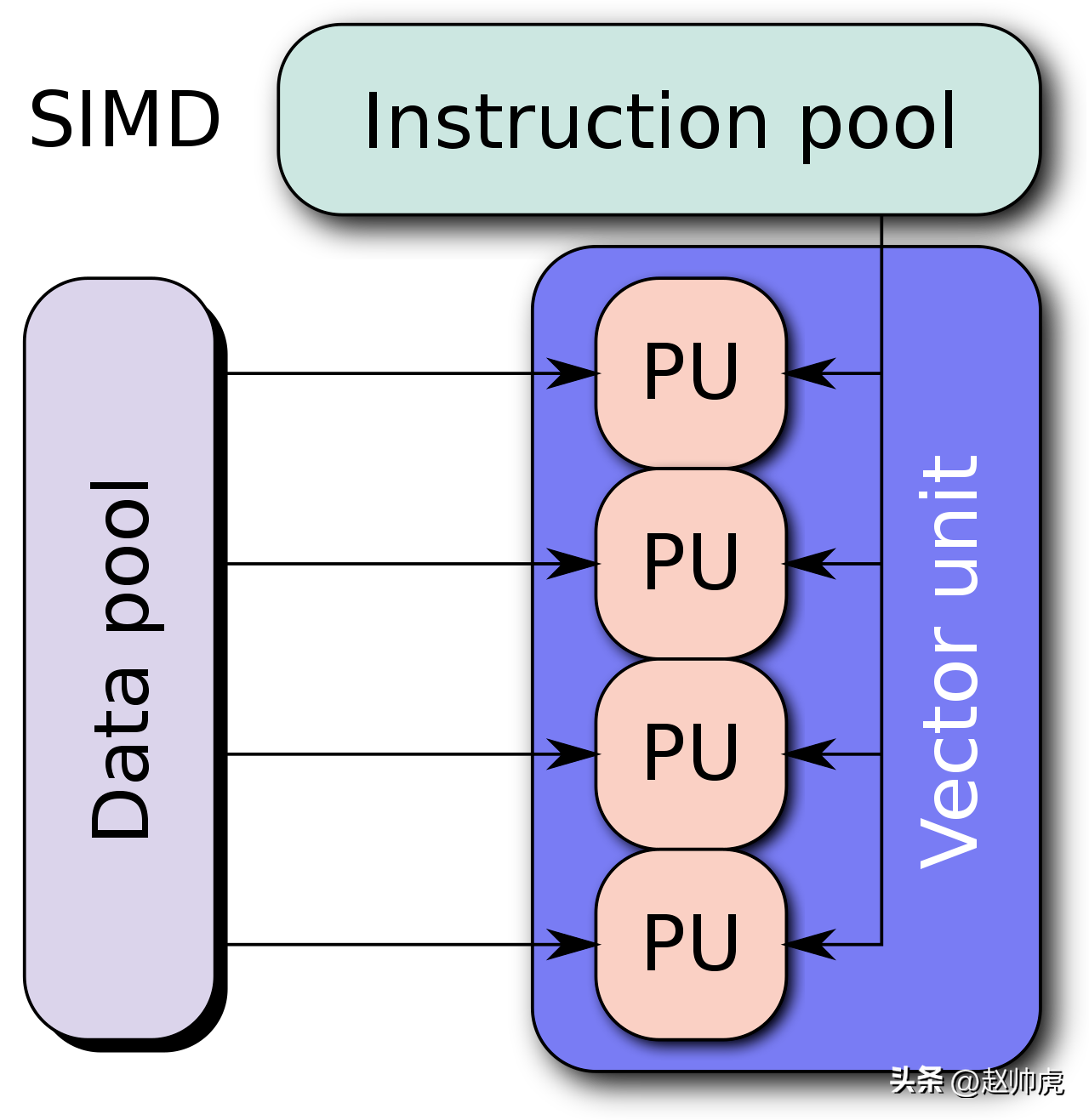
Single Instruction Multiple Data
当然,还有两个分类 MISD 和 MIMD,这里就不细说了。
Intel CPU通过扩充指令集提供了对SIMD的支持。按照出现顺序,总共有三套:MMX、SSE 和 AVX:

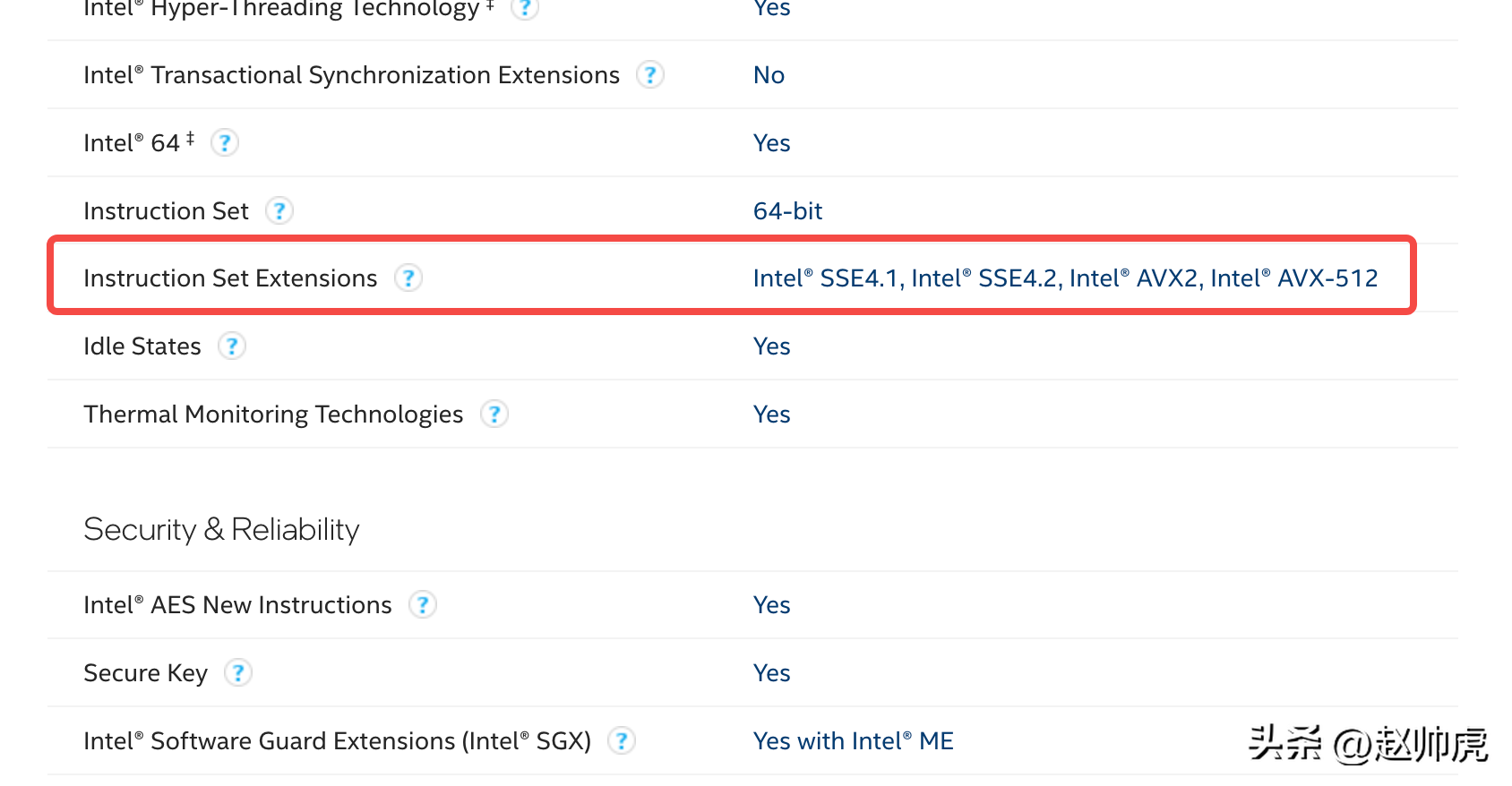
我们可以通过Intel官方网站查询自己的处理器是否支持(地址附在文章末尾)。下面以MacOS为例,简单看一下。通过sysctl查看CPU型号:
sysctl -a | grep brand machdep.cpu.brand_string: Intel(R) Core(TM) i7-1068NG7 CPU @ 2.30GHzmachdep.cpu.brand: 0下面是查询结果,可见主流的SSE和AVX指令集都是支持的:
那么这些指令集怎么用呢?Intel官方提供了一套C语言库,并且有详细的函数文档,名字为 "Intel® Intrinsics Guide"。
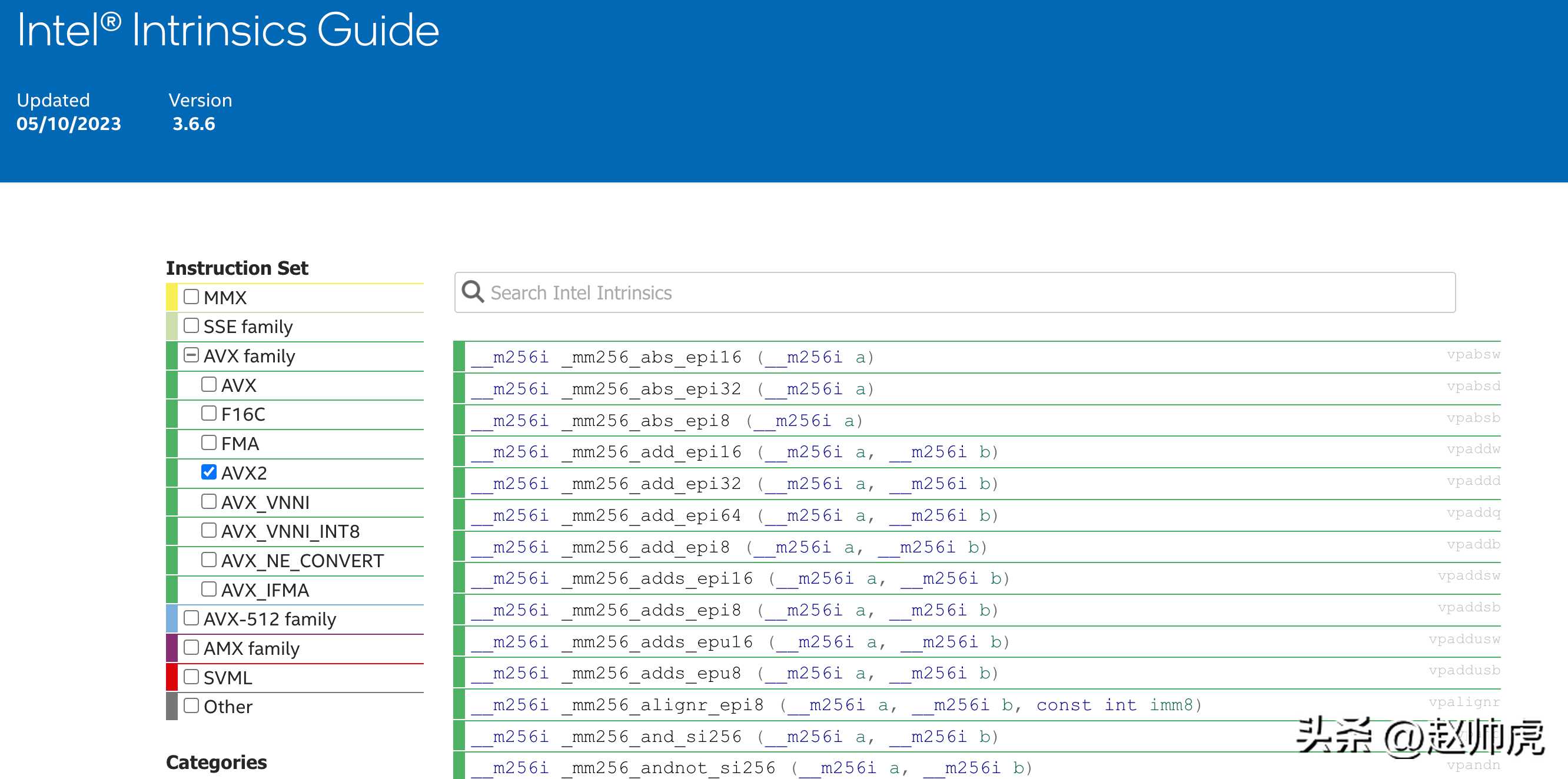
这些函数有明确的命名规范,由三段构成,分别是:
比如我想看下256bit下的加法,搜索 mm256_add 会返回一组函数:
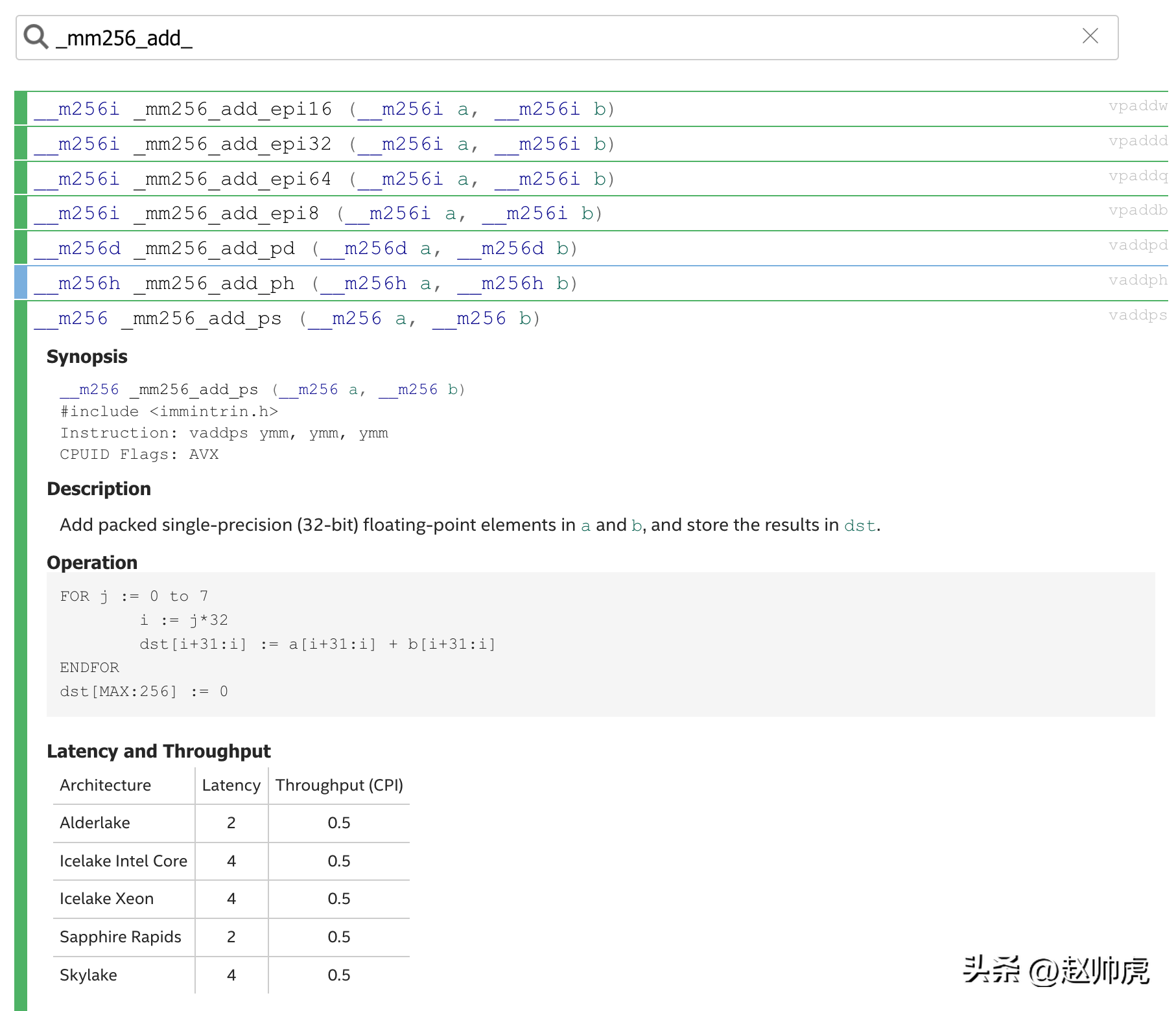
接下来我们用这些指令来看看下性能吧。
由于要做性能测试,编程语言是C/C++,所以选择 google/benchmark 作为辅助。测试场景是两个100w条数据的数组做加法,数组里的元素可以是int32、float32、int64等。后面我们采用float32进行测试。
google/benchmark 跟着Github上"Installation" 部分走就好了,最后必须执行安装这一步:
sudo cmake --build "build" --config Release --target install先写一段比较正常的单测代码,通过 #include <immintrin.h>可使用SIMD的能力。准备工作包括:
计算逻辑是 c = a + b,跑多少轮次由 benchmark::State &state 来控制。代码如下:
#include <immintrin.h>#include <benchmark/benchmark.h>constexpr int N = 1000000;static void normal(benchmark::State &state){ float *a = static_cast<float *>(_mm_malloc(sizeof(float) * N, 16)); float *b = static_cast<float *>(_mm_malloc(sizeof(float) * N, 16)); float *c = static_cast<float *>(_mm_malloc(sizeof(float) * N, 16)); for (int i = 0; i < N; ++i) { a[i] = i; b[i] = 2 * i; } for (auto _ : state) { for (int i = 0; i < N; ++i) { c[i] = a[i] + b[i]; } } _mm_free(a); _mm_free(b); _mm_free(c);}BENCHMARK(normal);我们将文件命名为 benchmark_float32.cpp。编译并执行:
g++ -Wall -std=c++20 -msse4 -mavx512f -mavx512bw benchmark_float32.cpp -pthread -lbenchmark -o benchmark_float32由于需要支持sse4 avx512,编译时需要加上 -msse4 -maxv512f -mavx512bw。运行 ./benchmark_float32 结果如下:
2023-06-17T18:30:04+08:00Running ./benchmark_float32Run on (8 X 2300 MHz CPU s)CPU Caches: L1 Data 48 KiB L1 Instruction 32 KiB L2 Unified 512 KiB (x4) L3 Unified 8192 KiBLoad Average: 3.24, 3.72, 4.09-----------------------------------------------------Benchmark Time CPU Iterations-----------------------------------------------------normal 1821404 ns 1812256 ns 386到当前为止,测试能够跑起来了。我们再加一个 128bit 计算的支持。这需要3个函数:
组装起来就是:
for (int i = 0; i < N; i += 4){ __m128 v1 = _mm_load_ps(a + i); __m128 v2 = _mm_load_ps(b + i); __m128 v3 = _mm_add_ps(v1, v2); _mm_store_ps(c + i, v3);}由于一个 __m128类型的变量可以容纳4个float32,所以 i 每次加4。
同样的方法,我们可以把 __m256 和 __m512 都纳入测试,测试结果如下:
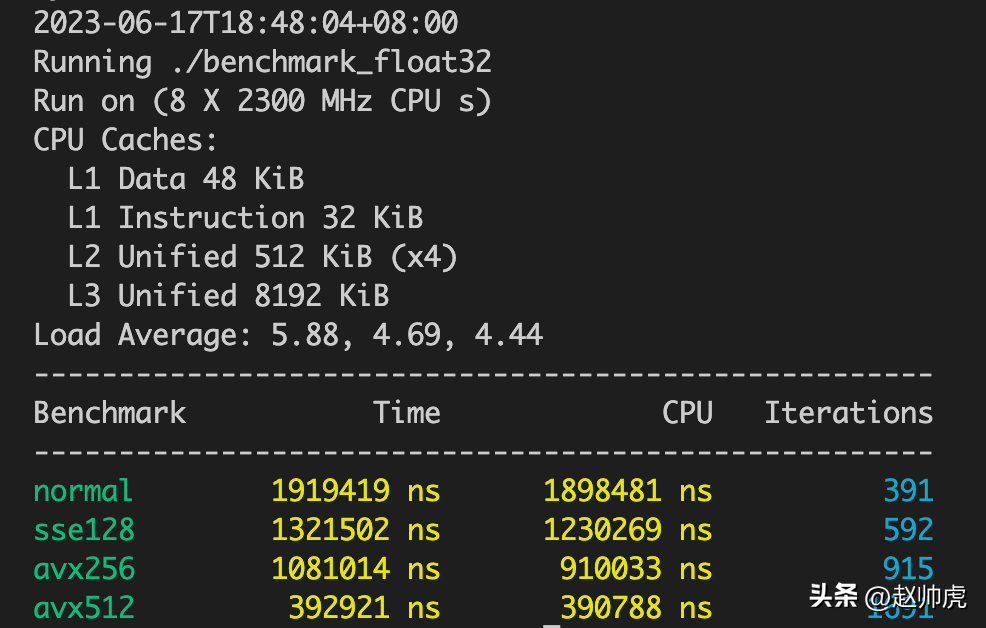
可以发现,这些扩容指令集的执行性能还是不错的,不过由于load和store需要额外的时间,并没有倍数的提升。
同样的方式,我们拿 int32 和 int64 进行测试,测试结果如下:
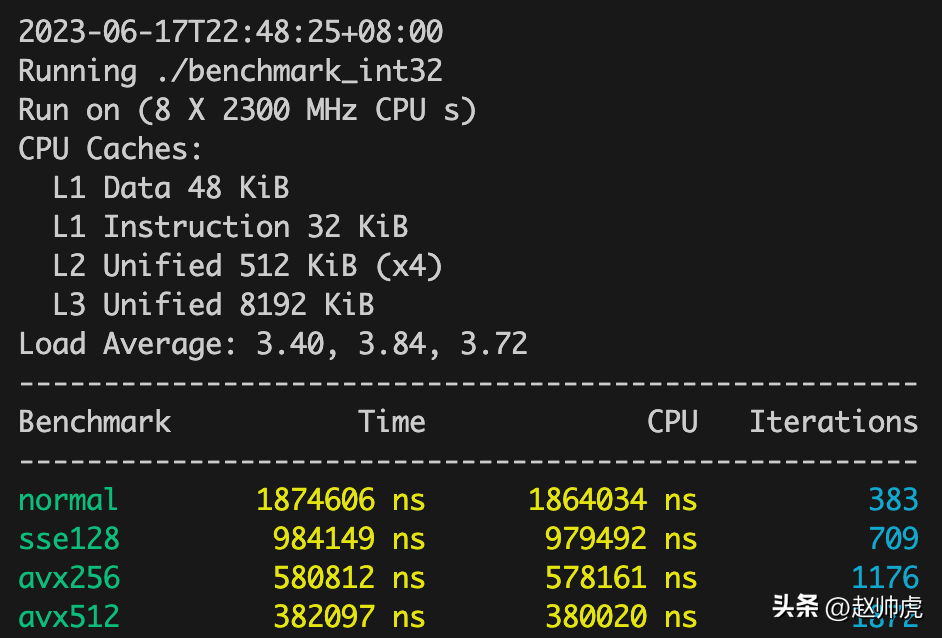
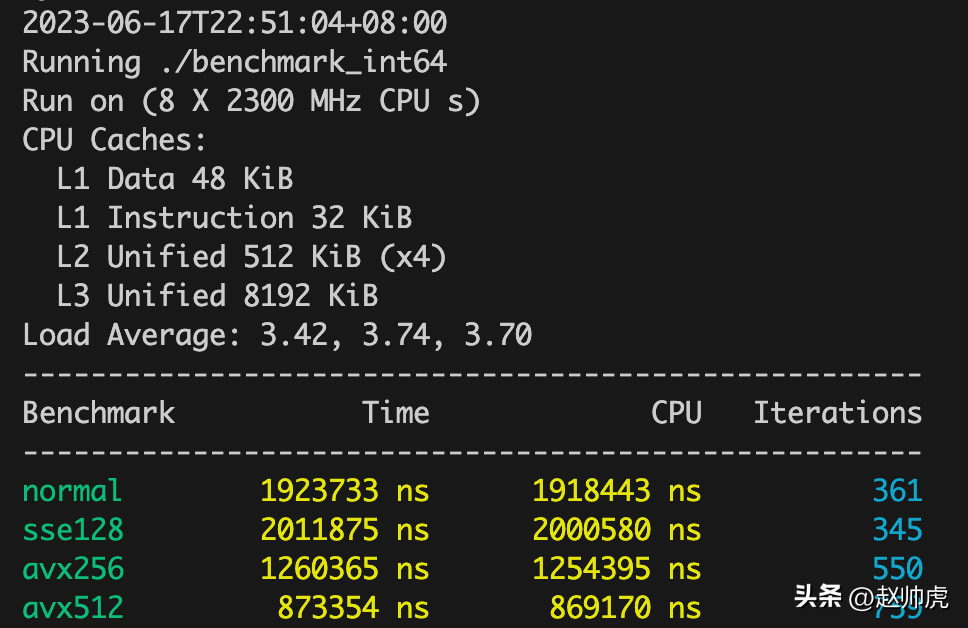
我们看 Iterations 这个指标,这个指标越大,说明运行速度越快。我们将不同类型汇总成表格:
Iterations | float32 | int32 | int64 | float32-O3 | int64-O3 |
normal | 388 | 383 | 361 | 1541 | 516 |
sse128 | 573 | 709 | 345 | 1441 | 2716 |
avx256 | 943 | 1176 | 550 | 1435 | 2959 |
avx512 | 1791 | 1872 | 759 | 6611 | 2601 |
可以发现,float32 和 int32 的迭代轮次逐个增加,而int64 在sse128和normal模式下基本持平,avx256和avx512呈现增加趋势。可能原因是在sse128模式下,计算速度理论上增加100%,load和save的时间抵消了计算速度的收益。
另外,在编译时开启 -O3 最高级别的编译优化之后, int64 在 SIMD下提速非常明显,float32只有在 avx512模式下有明显提速。
除了简单的加减乘除,SSE 和 AVX 能够支持很多形式的计算,包括但不限于:位运算、类型转换、比较、加密算法、数学函数、统计函数、随机数、字符串等,完整列表可参考 "Intel® Intrinsics Guide"。由于只是学习目的,并没有对所有这些函数进行测试。
问了下ChatGPT “SIMD的劣势”,给出的回复如下:
单纯从应用上来看,Clickhouse启发了一众大数据处理框架对SIMD能力的引入、NumPy库的引入,还有多媒体领域的广泛使用,我们有理由相信SIMD带来的性能收益。
Clickhouse具体做了哪些优化,对SIMD的能力的应用有多充分,后面了解完再补充。
查询CPU信息:
https://ark.intel.com/content/www/us/en/ark.html。
(责任编辑:探索)
 美联储加息什么意思?美联储加息是指联邦储备系统管理委员会在华盛顿召开议息会议后,决定货币政策的调整,是否上调利率。简单的说,加息是一种紧缩型货币政策,美联储通过加息来应对当前的经济。一般加息可以提高银
...[详细]
美联储加息什么意思?美联储加息是指联邦储备系统管理委员会在华盛顿召开议息会议后,决定货币政策的调整,是否上调利率。简单的说,加息是一种紧缩型货币政策,美联储通过加息来应对当前的经济。一般加息可以提高银
...[详细] 中国福利彩票发行中心官方网站www.cwl.gov.cn广东省福利彩票发行中心官方网站www.gdfc.org.cn今晚南粤36选7奖池856万元预计头奖奖金500万元今晚开奖彩种
...[详细]
中国福利彩票发行中心官方网站www.cwl.gov.cn广东省福利彩票发行中心官方网站www.gdfc.org.cn今晚南粤36选7奖池856万元预计头奖奖金500万元今晚开奖彩种
...[详细] 科技日报北京1月30日电 记者张佳欣)日本神户大学开发了一种新方法,可产生永不褪色的结构色,且不受限于视角,还能被打印出来。这种材料对环境和生物的影响很小,而且可以薄涂,有望显著改善传统涂料的
...[详细]
科技日报北京1月30日电 记者张佳欣)日本神户大学开发了一种新方法,可产生永不褪色的结构色,且不受限于视角,还能被打印出来。这种材料对环境和生物的影响很小,而且可以薄涂,有望显著改善传统涂料的
...[详细]民声我代言丨委员建议公共交通增加方言播报,市交通运输局这样回应
 学习语言贵在“沉浸”——坐过成都地铁后,一些外地游客“猝不及防”学会了生平第一句成都话。方言借助交通广播“声入人心”,启发了成都市政协委员、成华区文化馆馆长蒋松谷。本次成都市两会上,他将带来的一份建议
...[详细]
学习语言贵在“沉浸”——坐过成都地铁后,一些外地游客“猝不及防”学会了生平第一句成都话。方言借助交通广播“声入人心”,启发了成都市政协委员、成华区文化馆馆长蒋松谷。本次成都市两会上,他将带来的一份建议
...[详细] 为防范非法行为,保护储户个人账户安全,同时减少金融资源浪费,越来越多的地方性中小银行也加入了清理“睡眠账户”的队伍。在分析人士看来,对于个人用户来说,银行清理“睡眠
...[详细]
为防范非法行为,保护储户个人账户安全,同时减少金融资源浪费,越来越多的地方性中小银行也加入了清理“睡眠账户”的队伍。在分析人士看来,对于个人用户来说,银行清理“睡眠
...[详细]泰勒·斯威夫特照片被滥用,生成式AI让Deepfake变得廉价且简单
 来源:DeepTech深科技嗨,泰勒·斯威夫特Taylor Swift),我们对最近发生在你身上的事情感到遗憾。看到 X 平台上传播的那些关于你的深度伪造色情内容,我能想象到你的心情,恶心、苦恼,甚至
...[详细]
来源:DeepTech深科技嗨,泰勒·斯威夫特Taylor Swift),我们对最近发生在你身上的事情感到遗憾。看到 X 平台上传播的那些关于你的深度伪造色情内容,我能想象到你的心情,恶心、苦恼,甚至
...[详细] 【国家工程师】◎本报记者 魏依晨 通讯员 魏小兰 从勘破世界难题到装备落地开花,从开拓国际市场到带领企业飞速发展,今年72岁的熊大和潜心一生只为一件事:“要把高梯度磁选机做到全世界最好!”
...[详细]
【国家工程师】◎本报记者 魏依晨 通讯员 魏小兰 从勘破世界难题到装备落地开花,从开拓国际市场到带领企业飞速发展,今年72岁的熊大和潜心一生只为一件事:“要把高梯度磁选机做到全世界最好!”
...[详细] 新快报讯 记者张晓菡报道 支付机构严监管已迎常态化。近日,银盛支付、国通星驿、钱袋宝支付、王府井支付等6家支付企业因存在违法违规行为,被央行处以罚款。据了解,银盛支付贵州分公司因未严格落实特约商户收单
...[详细]
新快报讯 记者张晓菡报道 支付机构严监管已迎常态化。近日,银盛支付、国通星驿、钱袋宝支付、王府井支付等6家支付企业因存在违法违规行为,被央行处以罚款。据了解,银盛支付贵州分公司因未严格落实特约商户收单
...[详细]银保监会完善相关政策措施 支持符合绿色低碳发展需求的保险产品和服务
 11月19日,中国银保监会新闻发言人就保险机构支持绿色、低碳、循环经济发展的主要进展,以及下一步在推动实现碳达峰碳中和目标上有什么具体考虑等相关问题回答了记者的提问。中国银保监会表示,支持保险机构规范
...[详细]
11月19日,中国银保监会新闻发言人就保险机构支持绿色、低碳、循环经济发展的主要进展,以及下一步在推动实现碳达峰碳中和目标上有什么具体考虑等相关问题回答了记者的提问。中国银保监会表示,支持保险机构规范
...[详细] 陈有华 ■本报记者 杨晨陈有华的书桌上,有一个A4纸大小的厚皮记事本。里面少有文字记述,更多的是一行行推导公式,或者折线图。“像这幅图,就是我模拟的物种随气候变化的衰减趋势,然后再根据这个猜想,结合数
...[详细]
陈有华 ■本报记者 杨晨陈有华的书桌上,有一个A4纸大小的厚皮记事本。里面少有文字记述,更多的是一行行推导公式,或者折线图。“像这幅图,就是我模拟的物种随气候变化的衰减趋势,然后再根据这个猜想,结合数
...[详细] 深圳三部门:持续深化融资租赁、商业保理行业清理规范 加强部门协同
深圳三部门:持续深化融资租赁、商业保理行业清理规范 加强部门协同 医院门口的“代泊车”“带路”服务 方便了就医 缺少了规范
医院门口的“代泊车”“带路”服务 方便了就医 缺少了规范 苏宁易购开拓县域增量 零售云销售规模同比增长超20%
苏宁易购开拓县域增量 零售云销售规模同比增长超20%