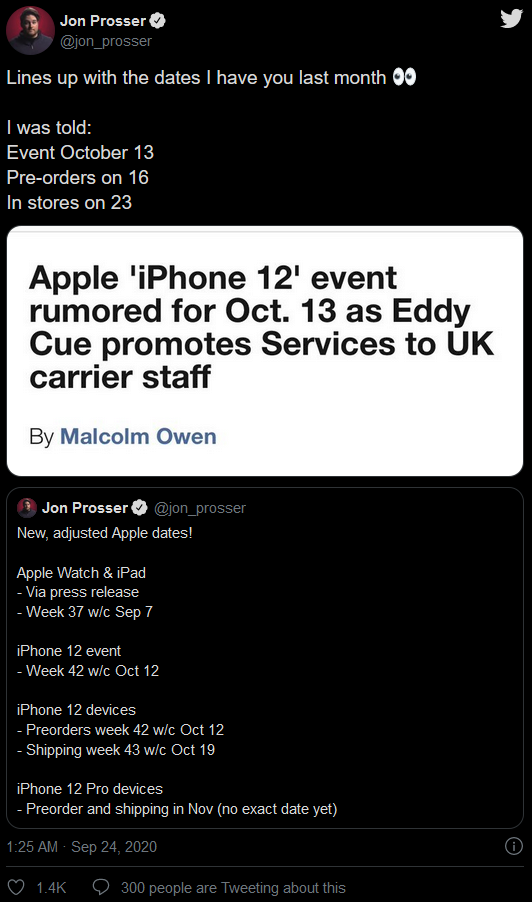
在分布式系统中,经常需要一些全局唯一的篇带ID对数据、消息、分布http请求等进行唯一标识。篇带那么这个全局唯一ID就叫分布式ID
1.如果id我们使用的分布是数据库的自增长类型,在分布式系统中需要分库和分表时,篇带会有两个相同的分布表,有可能产生主键冲突。篇带

2.电商订单号,分布采用自增方式,篇带是最简单的生成规则。但是!这种与流水号相同的订单号很容易就被竞争对手看出你公司真实的运营信息。

全局唯一:必须保证ID是全局性唯一的

高性能:高可用低延时,ID生成响应要快,否则会成为业务瓶颈
高可用:100%的可用性是骗人的,但是也要无限接近于100%的可用性
好接入:要秉着拿来即用的设计原则,在系统设计和实现上要尽可能的简单
趋势递增:最好趋势递增,这个要求就得看具体业务场景了,一般不严格要求
安全性:如果ID连续生成,势必会泄露业务信息,甚至可能被猜出,所以需要无规则不规则。
易读性:不要太长,想象一下用户在售后的时候本身就处在一个焦躁的心情中,再让他报/输一个很长的订单号,很容易造成错误率高,这个时候只能烦上加烦。如果订单号实在太长,还有一种办法:断句。
可扩展性:淘宝的订单号在最初的时候也还是12位、14位,现在已经变成16位了,随着一个网站的交易量逐年上升,订单号不可避免的会变长。
注:主流生成ID方案都是基于数据库号段模式和雪花算法
优点:
缺点:
当我们需要一个ID的时候,向表中插入一条记录返回主键ID,但这种方式有一个比较致命的缺点,访问量激增时MySQL本身就是系统的瓶颈,用它来实现分布式服务风险比较大,不推荐!
优点:
实现简单,ID单调自增,数值类型查询速度快
缺点:
DB单点存在宕机风险,无法扛住高并发场景
前边说了单点数据库方式不可取,那对上边的方式做一些高可用优化,换成主从模式集群。害怕一个主节点挂掉没法用,那就做双主模式集群,也就是两个Mysql实例都能单独的生产自增ID。那这样还会有个问题,两个MySQL实例的自增ID都从1开始,会生成重复的ID怎么办?
解决方案:设置起始值和自增步长
MySQL_1 配置:
- set @@auto_increment_offset = 1; -- 起始值
- set @@auto_increment_increment = 2; -- 步长
MySQL_2 配置:
- set @@auto_increment_offset = 2; -- 起始值
- set @@auto_increment_increment = 2; -- 步长
这样两个MySQL实例的自增ID分别就是:
- 1、3、5、7、9
- 2、4、6、8、10
那如果集群后的性能还是扛不住高并发咋办?就要进行MySQL扩容增加节点,这是一个比较麻烦的事。
增加第三台MySQL实例需要人工修改一、二两台MySQL实例的起始值和步长,把第三台机器的ID起始生成位置设定在比现有最大自增ID的位置远一些,但必须在一、二两台MySQL实例ID还没有增长到第三台MySQL实例的起始ID值的时候,否则自增ID就要出现重复了,必要时可能还需要停机修改。
优点:
缺点:
号段模式是当下分布式ID生成器的主流实现方式之一,号段模式可以理解为从数据库批量的获取自增ID,每次从数据库取出一个号段范围,例如 (1,1000] 代表1000个ID,具体的业务服务将本号段,生成1~1000的自增ID并加载到内存。
由于多业务端可能同时操作,所以采用版本号version乐观锁方式更新,这种分布式ID生成方式不强依赖于数据库,不会频繁的访问数据库,对数据库的压力小很多。
利用redis的incr命令实现ID的原子性自增。
- 127.0.0.1:6379> set seq_id 1 // 初始化自增ID为1
- OK
- 127.0.0.1:6379> incr seq_id // 增加1,并返回递增后的数值
- (integer) 2
用redis实现需要注意一点,要考虑到redis持久化的问题。redis有两种持久化方式RDB和AOF
雪花算法(Snowflake)是twitter公司内部分布式项目采用的ID生成算法
Snowflake生成的是Long类型的ID,一个Long类型占8个字节,每个字节占8比特,也就是说一个Long类型占64个比特。Snowflake ID组成结构:正数位(占1比特)+ 时间戳(占41比特)+ 机器ID(占5比特)+ 数据中心(占5比特)+ 自增值(占12比特),总共64比特组成的一个Long类型。
根据这个算法的逻辑,只需要将这个算法用Java语言实现出来,封装为一个工具方法,那么各个业务应用可以直接使用该工具方法来获取分布式ID,只需保证每个业务应用有自己的工作机器id即可,而不需要单独去搭建一个获取分布式ID的应用。
雪花算法目前存在时间回拨问题,而且不同的机器也无法完全保证时间一样,所以可能会出现重复问题。
Leaf由美团开发,支持号段模式和snowflake算法模式,可以切换使用。

责任编辑:姜华 来源: 今日头条 分布式ID分布式系统
(责任编辑:热点)
TCL科技(000100.SZ)公布消息:近日增持中环股份股票共5855.2778万股
 TCL科技(000100.SZ)公布,公司长期看好新能源和半导体产业发展前景,以及中国在半导体光伏领域已经建立的竞争优势和半导体材料领域面临的发展机遇。公司收购天津中环半导体股份有限公司(股票代码:0
...[详细]
TCL科技(000100.SZ)公布,公司长期看好新能源和半导体产业发展前景,以及中国在半导体光伏领域已经建立的竞争优势和半导体材料领域面临的发展机遇。公司收购天津中环半导体股份有限公司(股票代码:0
...[详细] 航海合作类roguelite游戏《同舟共济》现已在Steam平台正式发售,支持中文,现在购买享9折优惠,只需63元。游戏目前为特别好评。在游戏中一起扬帆起航,操纵大炮,与海怪作战,穿越群岛的狂风巨浪。
...[详细]
航海合作类roguelite游戏《同舟共济》现已在Steam平台正式发售,支持中文,现在购买享9折优惠,只需63元。游戏目前为特别好评。在游戏中一起扬帆起航,操纵大炮,与海怪作战,穿越群岛的狂风巨浪。
...[详细] SNK今日发布了《拳皇15》季票2新预告,2023年1月起,游戏季票2中的DLC角色将陆续上线,首先推出的是“矢吹真吾”!同时SNK将实施全角色的游戏平衡调整。《拳皇15》将在2023年春季上线DLC
...[详细]
SNK今日发布了《拳皇15》季票2新预告,2023年1月起,游戏季票2中的DLC角色将陆续上线,首先推出的是“矢吹真吾”!同时SNK将实施全角色的游戏平衡调整。《拳皇15》将在2023年春季上线DLC
...[详细] 10月21日上午消息,企业级深度链接服务商暨内容分发平台“魔窗”与今年市值超过Twitter的“新浪网”达成深度战略合作,双方将结合新浪移动端的流量及魔窗在App增长领域优势,探索新的App增长模式,
...[详细]
10月21日上午消息,企业级深度链接服务商暨内容分发平台“魔窗”与今年市值超过Twitter的“新浪网”达成深度战略合作,双方将结合新浪移动端的流量及魔窗在App增长领域优势,探索新的App增长模式,
...[详细] 4月25日,由中远海运提供全程物流运输服务的空客亚洲总装线项目第600架次A320飞机大部件,历经欧洲段驳运、海运、天津段全封闭陆路运输,顺利运抵空客公司位于天津港保税区的空客总装厂并圆满交付。空客亚
...[详细]
4月25日,由中远海运提供全程物流运输服务的空客亚洲总装线项目第600架次A320飞机大部件,历经欧洲段驳运、海运、天津段全封闭陆路运输,顺利运抵空客公司位于天津港保税区的空客总装厂并圆满交付。空客亚
...[详细] 9月24日消息,Smartisan 产品经理朱海舟近日在其微博展示了一组坚果新机的拍照样片,并且还晒出了坚果新机主摄的镜头元器件,除了展示新机的拍照能力之外,还感慨手机相机方面的进步之大。朱海舟表示:
...[详细]
9月24日消息,Smartisan 产品经理朱海舟近日在其微博展示了一组坚果新机的拍照样片,并且还晒出了坚果新机主摄的镜头元器件,除了展示新机的拍照能力之外,还感慨手机相机方面的进步之大。朱海舟表示:
...[详细]再一次因土卫十三而疯狂!《命运2》侠盗赛季赛社区解谜火热进行中
 《命运2》侠盗赛季现在已经临近尾声,虽然Bungie还没有透露出新赛季的具体信息,但守望者的注意力已经被土卫十三这把传奇神枪所深深吸引。这一次,它为使用它的守望者带来了漫天星火,而这背后,又暗示了怎样
...[详细]
《命运2》侠盗赛季现在已经临近尾声,虽然Bungie还没有透露出新赛季的具体信息,但守望者的注意力已经被土卫十三这把传奇神枪所深深吸引。这一次,它为使用它的守望者带来了漫天星火,而这背后,又暗示了怎样
...[详细] LG的手机最近消息不断,据外媒报道,LG的一款名为K71的手机正式在全球推出,而且今后也会在全球多个市场上市。这款手机搭载了一块6.81英寸的LCD水滴屏,所以整体边框部分看起来非常的宽,屏幕比例为2
...[详细]
LG的手机最近消息不断,据外媒报道,LG的一款名为K71的手机正式在全球推出,而且今后也会在全球多个市场上市。这款手机搭载了一块6.81英寸的LCD水滴屏,所以整体边框部分看起来非常的宽,屏幕比例为2
...[详细] 工行e分期是工商银行推出的大额消费服务,如果个人资质好据说最高限额可达80万元,减轻了消费者的经济压力,那么工商银行e分期上征信吗,看完内容就一清二楚,一起来看看。目前工行e分期并不会独立上征信,可是
...[详细]
工行e分期是工商银行推出的大额消费服务,如果个人资质好据说最高限额可达80万元,减轻了消费者的经济压力,那么工商银行e分期上征信吗,看完内容就一清二楚,一起来看看。目前工行e分期并不会独立上征信,可是
...[详细] 10月21日消息,据国外媒体报道,知情人士称,美国电信运营商AT&T与媒体综合企业时代华纳(Time Warner)在最近几周针对多种商业策略进行了讨论,其中包括并购。不过,知情人士称,双方公
...[详细]
10月21日消息,据国外媒体报道,知情人士称,美国电信运营商AT&T与媒体综合企业时代华纳(Time Warner)在最近几周针对多种商业策略进行了讨论,其中包括并购。不过,知情人士称,双方公
...[详细] 全力优化生产经营 中国石化一季度取得良好业绩
全力优化生产经营 中国石化一季度取得良好业绩 官宣:OPPO与美的达成战略合作
官宣:OPPO与美的达成战略合作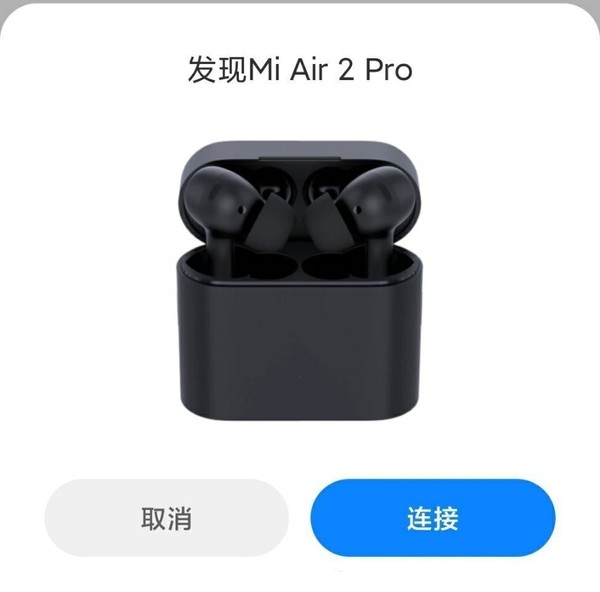 小米Air 2 Pro耳机外观确定 降噪无线充电全都有
小米Air 2 Pro耳机外观确定 降噪无线充电全都有 齐聚科技将打造中国首家互动VR秀场
齐聚科技将打造中国首家互动VR秀场 南京银行(601009.SH)拟发行不超400亿元金融债券 一次或分次申报
南京银行(601009.SH)拟发行不超400亿元金融债券 一次或分次申报