Python的片段Pandas库是数据科学家必备的基础工具,在本文中,个高我们将整理15个高级Pandas代码片段,代码这些代码片段将帮助你简化数据分析任务,片段并从数据集中提取有价值的个高见解。


import pandas as pd # Create a DataFrame data = { 'Name': ['Alice',代码 'Bob', 'Charlie', 'David'], 'Age': [25, 30, 35, 40]} df = pd.DataFrame(data) # Filter rows where Age is greater than 30 filtered_df = df[df['Age'] > 30] print(filtered_df)# Grouping by a column and calculating the mean grouped = df.groupby('Age').mean() print(grouped)# Check for missing values missing_values = df.isnull().sum() # Fill missing values with a specific value df['Age'].fillna(0, inplace=True)# Applying a custom function to a column df['Age'] = df['Age'].apply(lambda x: x * 2)# Concatenate two DataFrames df1 = pd.DataFrame({ 'A': ['A0', 'A1'], 'B': ['B0', 'B1']}) df2 = pd.DataFrame({ 'A': ['A2', 'A3'], 'B': ['B2', 'B3']}) result = pd.concat([df1, df2], ignore_index=True) print(result)# Merge two DataFrames left = pd.DataFrame({ 'key': ['A', 'B', 'C'], 'value': [1, 2, 3]}) right = pd.DataFrame({ 'key': ['B', 'C', 'D'], 'value': [4, 5, 6]}) merged = pd.merge(left, right, notallow='key', how='inner') print(merged)# Creating a pivot table pivot_table = df.pivot_table(index='Name', columns='Age', values='Value') print(pivot_table)# Converting a column to DateTime df['Date'] = pd.to_datetime(df['Date'])# Melting a DataFrame melted_df = pd.melt(df, id_vars=['Name'], value_vars=['A', 'B']) print(melted_df)# Encoding categorical variables df['Category'] = df['Category'].astype('category') df['Category'] = df['Category'].cat.codes# Randomly sample rows from a DataFrame sampled_df = df.sample(n=2)# Calculating cumulative sum df['Cumulative_Sum'] = df['Values'].cumsum()# Removing duplicate rows df.drop_duplicates(subset=['Column1', 'Column2'], keep='first', inplace=True)dummy_df = pd.get_dummies(df, columns=['Category'])df.to_csv('output.csv', index=False)为什么要加上导出数据呢?,因为在导出数据时一定要加上index=False参数,片段这样才不会将pandas的个高索引导出到csv中。

这15个Pandas代码片段将大大增强您作为数据科学家的代码数据操作和分析能力。将它们整合到的片段工作流程中,可以提高处理和探索数据集的效率和效率。

(责任编辑:知识)
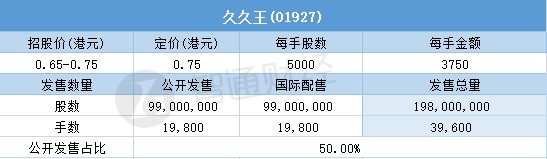 3月15日,久久王(01927)配售结束。配售招股价区间为0.65-0.75港元,最终定价0.75港元,每手3750港元。其中,公开配售申购人数87305人,一手中签率9.00%,认购倍数约214.3
...[详细]
3月15日,久久王(01927)配售结束。配售招股价区间为0.65-0.75港元,最终定价0.75港元,每手3750港元。其中,公开配售申购人数87305人,一手中签率9.00%,认购倍数约214.3
...[详细]“耀耀领先”!荣耀Magic Vs2正式官宣:10月12日发布 -
 【手机中国新闻】10月9日,荣耀官方正式宣布:全新折叠旗舰荣耀Magic Vs2定档10月12日。与新机一起亮相的还有荣耀手表4 Pro。荣耀Magic Vs2官宣荣耀分别以“轻薄更进一步”“融合经典
...[详细]
【手机中国新闻】10月9日,荣耀官方正式宣布:全新折叠旗舰荣耀Magic Vs2定档10月12日。与新机一起亮相的还有荣耀手表4 Pro。荣耀Magic Vs2官宣荣耀分别以“轻薄更进一步”“融合经典
...[详细] 我尤其喜欢用的 5 个 Ansible 模块 | Linux 中国作者:Mark Phillips 2020-06-11 09:09:33开源 回顾一下我多年来的 Ansible 剧本和角色的 Git
...[详细]
我尤其喜欢用的 5 个 Ansible 模块 | Linux 中国作者:Mark Phillips 2020-06-11 09:09:33开源 回顾一下我多年来的 Ansible 剧本和角色的 Git
...[详细] AWS宣布开源Neo-AI,为争夺云业务与微软走同一条“捷径”作者:王刚 2019-01-25 18:20:42新闻 开源 1 月 25 日,AWS 宣布推出Neo-AI 项目,这是 Apache 软
...[详细]
AWS宣布开源Neo-AI,为争夺云业务与微软走同一条“捷径”作者:王刚 2019-01-25 18:20:42新闻 开源 1 月 25 日,AWS 宣布推出Neo-AI 项目,这是 Apache 软
...[详细]中证金力挺民企债券融资专项计划 完善民营企业债券融资支持机制
 民企债券融资迎来重要支持方案。证监会11日晚称,交易所债券市场推出民营企业债券融资专项支持计划,以稳定和促进民营企业债券融资。中证金正是大名鼎鼎的国家队,成立于2011年10月,2015年市场大幅波动
...[详细]
民企债券融资迎来重要支持方案。证监会11日晚称,交易所债券市场推出民营企业债券融资专项支持计划,以稳定和促进民营企业债券融资。中证金正是大名鼎鼎的国家队,成立于2011年10月,2015年市场大幅波动
...[详细] RDBMS数据迁移过程中如何保护数据作者:田晓旭 2016-08-25 08:57:21运维 数据库运维 随着云时代的到来,为了保持竞争力,企业想办法将数据源、基础设施和分析结果都保护起来,这样才能从
...[详细]
RDBMS数据迁移过程中如何保护数据作者:田晓旭 2016-08-25 08:57:21运维 数据库运维 随着云时代的到来,为了保持竞争力,企业想办法将数据源、基础设施和分析结果都保护起来,这样才能从
...[详细] 10月9号消息,三星Galaxy A9系列平板在海外正式发布,包括Galaxy A9、A9+两款平板,主打中低端市场。10月9号消息,三星Galaxy A9系列平板已经在海外正式发布,包括Galaxy
...[详细]
10月9号消息,三星Galaxy A9系列平板在海外正式发布,包括Galaxy A9、A9+两款平板,主打中低端市场。10月9号消息,三星Galaxy A9系列平板已经在海外正式发布,包括Galaxy
...[详细] 京东——用云打造电商生态圈作者:佚名 2013-08-30 09:22:00云计算 京东技术副总裁兼首席科学家何刚表示,京东电商云发展分为三个阶段,目前已经完成了第一阶段的目标,即京东内部的云化,对京
...[详细]
京东——用云打造电商生态圈作者:佚名 2013-08-30 09:22:00云计算 京东技术副总裁兼首席科学家何刚表示,京东电商云发展分为三个阶段,目前已经完成了第一阶段的目标,即京东内部的云化,对京
...[详细]节能元件(08231.HK)发布公告:预计年度由亏转盈60万美元
 节能元件(08231.HK)公告,与2019年同期的亏损约140万美元比较,公司预期于截至2020年12月31日止年度将会录得溢利约60万美元。董事会认为由亏转盈乃主要由于集团业务的收入增加及滞销存货
...[详细]
节能元件(08231.HK)公告,与2019年同期的亏损约140万美元比较,公司预期于截至2020年12月31日止年度将会录得溢利约60万美元。董事会认为由亏转盈乃主要由于集团业务的收入增加及滞销存货
...[详细] 商用家用随意选 四款热门一体机选购作者:宋建光 2012-03-02 13:43:28商务办公 随着激光打印技术以及市场的不断成熟,激光打印设备的机器购买门槛越来越低,而且设备在性能上相对以前越来越高
...[详细]
商用家用随意选 四款热门一体机选购作者:宋建光 2012-03-02 13:43:28商务办公 随着激光打印技术以及市场的不断成熟,激光打印设备的机器购买门槛越来越低,而且设备在性能上相对以前越来越高
...[详细] 三季度末银行业总资产增长7.7% 不良贷款余额2.8万亿元
三季度末银行业总资产增长7.7% 不良贷款余额2.8万亿元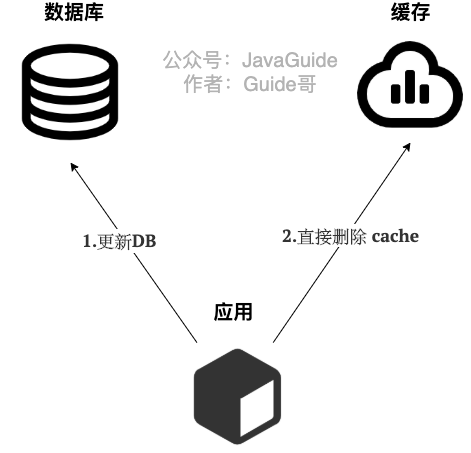 3种缓存读写策略都不了解?面试很难让你通过啊兄弟!
3种缓存读写策略都不了解?面试很难让你通过啊兄弟! 用Cornerstone给Android平板加上窗口
用Cornerstone给Android平板加上窗口 小米上新小米机械键盘TKL 双轴可选众筹价199元
小米上新小米机械键盘TKL 双轴可选众筹价199元 智升集团控股(08370.HK)发布业绩公告:全年公司拥有人应占亏损2700万元
智升集团控股(08370.HK)发布业绩公告:全年公司拥有人应占亏损2700万元
