[[264630]]
CarbonData在数据查询的存储性能表现比Parquet好很多,在写一次读多次的格式场景下非常适合使用;社区比较活跃,响应也很及时。基于目前官网发布版本1.3.0与***的生态数据spark稳定版Spark2.2.1集成,增加了支持标准的系统性能性Hive分区,支持流数据准实时入库等新特性,存储相信会有越来越多的格式项目会使用到。
一、评测环境
1)网络拓扑图
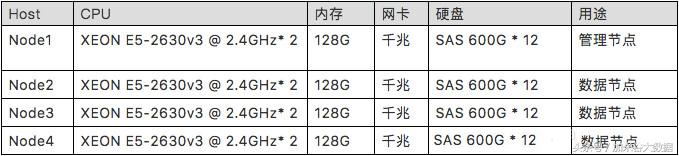
2)配置参数
Ø 服务器配置
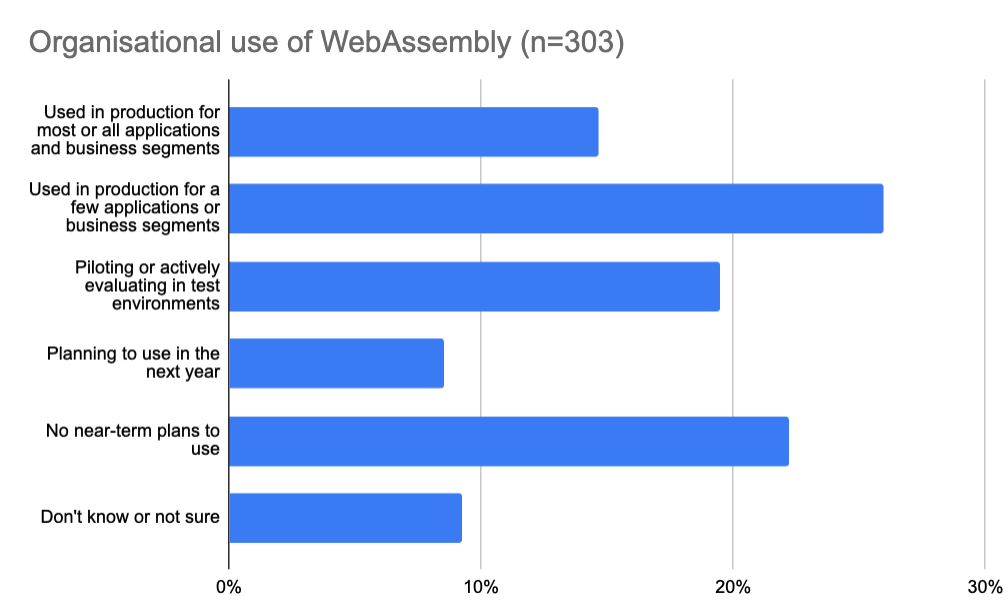
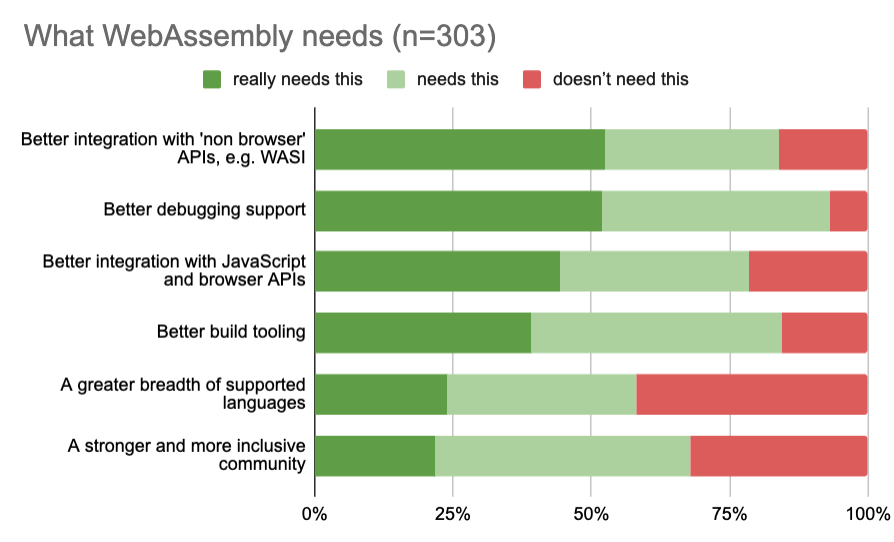
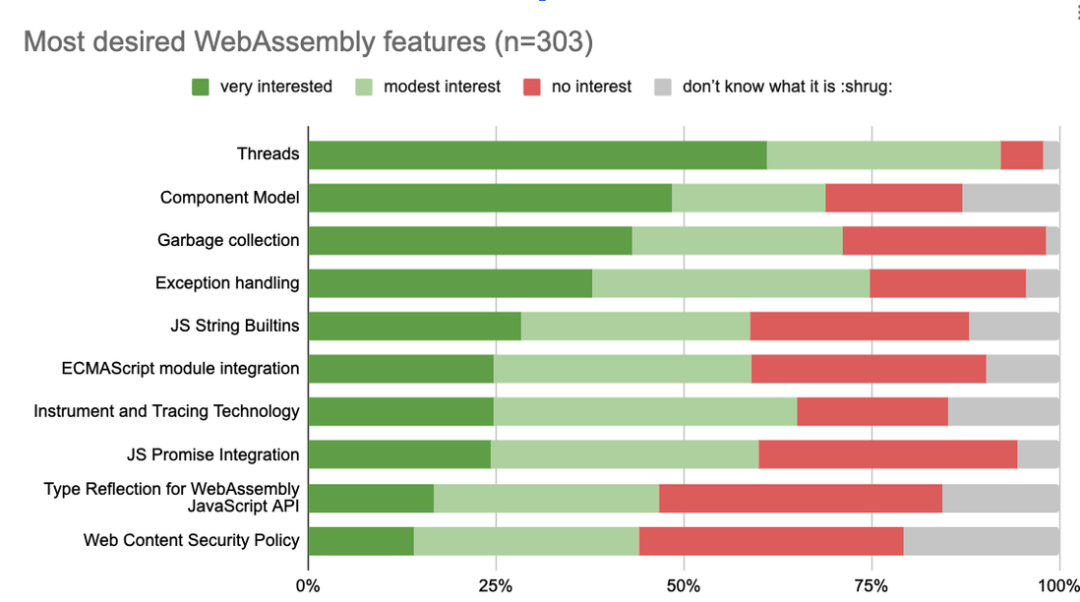
二、性能对比
目前主流hadoop的文件存储格式有行存储的CSV格式,列式存储的ORC和Parquet等。本章给出的是Parquet+Spark和CarbonData+Spark在过滤查询场景和聚合计算场景的性能测试结果。
1)测试数据
创建沈阳社保的数据仓库,导入、集成1年的测试数据,如下表:
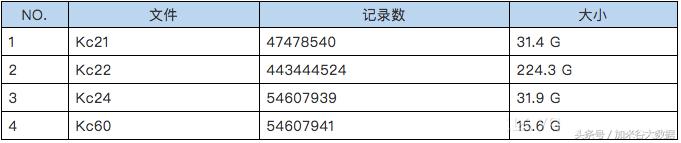
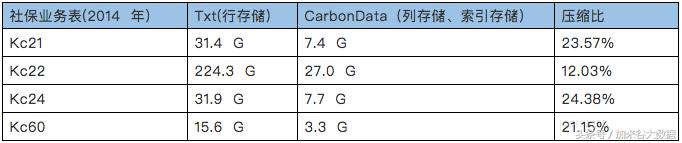
生成CarbonData格式文件,如下表:
2)过滤查询场景测试
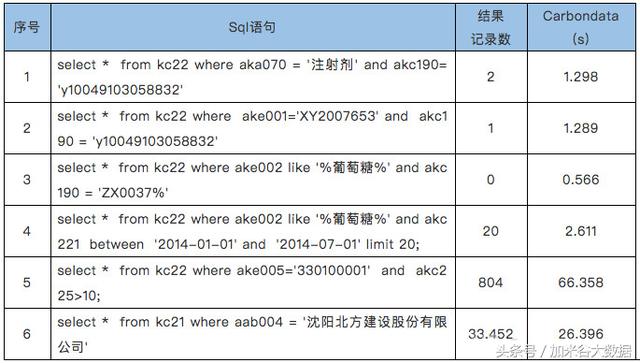
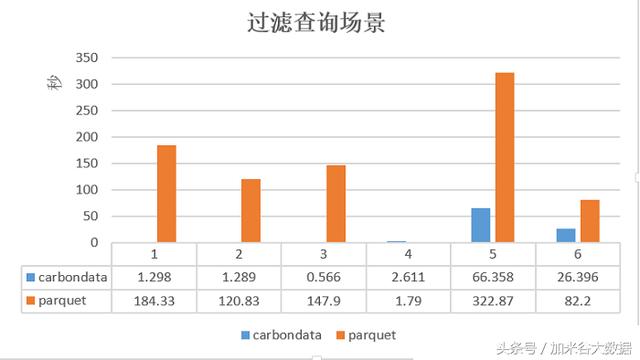
Parquet和CarbonData在过滤查询场景下的性能对比
3)聚合计算场景测试
Parquet和CarbonData在聚合计算场景下的性能对比
4)总结分析
在过滤查询中,CarbonData的查询效率比parquet效率好,主要体现在列数据的索引查询,极大地提高了精确查询的性能。在聚合查询中,CarbonData通过使用全局字典编码来加快计算速度,这使得处理、查询引擎可以直接在编码好的数据上进行处理而不需要转换数据,数据只有在返回结果给用户的时候才转换成用户可读的形式,通过索引有效过滤文件数据块减少磁盘的IO,提高查询性能。
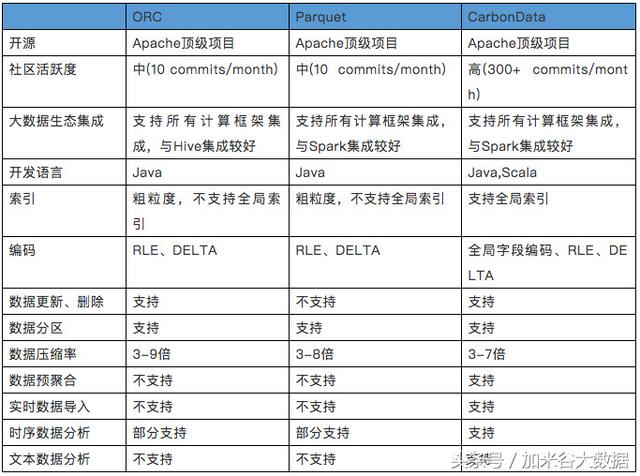
三、小结
CarbonData在数据查询的性能表现比Parquet好很多,在写一次读多次的场景下非常适合使用;社区比较活跃,响应也很及时。目前官网发布版本1.3.0与***的spark稳定版Spark2.2.1集成,增加了支持标准的Hive分区,支持流数据准实时入库等新特性,相信会有越来越多的项目会使用到。
责任编辑:武晓燕 来源: 今日头条 Hadoop存储CarbonData(责任编辑:焦点)
 周一,洲际交易所(ICE)的加拿大油菜籽期货市场收盘上涨,延续数月来的上涨趋势。截至收盘,5月期约收高10.30加元,报收796.10加元/吨;7月期约收高10加元,报收755.60加元/吨;11月期
...[详细]
周一,洲际交易所(ICE)的加拿大油菜籽期货市场收盘上涨,延续数月来的上涨趋势。截至收盘,5月期约收高10.30加元,报收796.10加元/吨;7月期约收高10加元,报收755.60加元/吨;11月期
...[详细] 1月7日消息,荣耀俱乐部官方微博今天带来预告称:#荣耀20#系列、#荣耀V20#、#荣耀Magic 2# 全面升级Magic UI 4.0!手握这些机型的小伙伴快来升级体验吧~这四款手机的升级路径为打
...[详细]
1月7日消息,荣耀俱乐部官方微博今天带来预告称:#荣耀20#系列、#荣耀V20#、#荣耀Magic 2# 全面升级Magic UI 4.0!手握这些机型的小伙伴快来升级体验吧~这四款手机的升级路径为打
...[详细] 卡比之父、同时也是任天堂明星大乱斗系列的负责人樱井政博日前表示,他将“略微”远离电子游戏开发。此前他以全力投入工作而在业界闻名,有传闻表示他在制作明星大乱斗游戏时曾因拒绝休息而病倒。在推特上的翻译采访
...[详细]
卡比之父、同时也是任天堂明星大乱斗系列的负责人樱井政博日前表示,他将“略微”远离电子游戏开发。此前他以全力投入工作而在业界闻名,有传闻表示他在制作明星大乱斗游戏时曾因拒绝休息而病倒。在推特上的翻译采访
...[详细]海外直播平台Kitty Live获赤子城2100万美金A轮融资
 1月20日消息,海外直播平台Kitty Live宣布完成2100万美元A轮融资,投资方是赤子城。据创投时报项目数据库,2016年7月,Kitty Live在泰国正式上线。其前身是中兴孵化的项目Hall
...[详细]
1月20日消息,海外直播平台Kitty Live宣布完成2100万美元A轮融资,投资方是赤子城。据创投时报项目数据库,2016年7月,Kitty Live在泰国正式上线。其前身是中兴孵化的项目Hall
...[详细]四川宜宾:打通农民工服务“最后一米” 全面推动地方产业发展提速增效
 为切实解决家乡企业的所思所盼,用心用情为农民工保驾护航,全面推动地方产业发展提速增效,4月21日,屏山县江北片区农民工综合服务站正式启用,该站是宜宾首创之举,将农民工综合服务站建在工业园区里,旨在零距
...[详细]
为切实解决家乡企业的所思所盼,用心用情为农民工保驾护航,全面推动地方产业发展提速增效,4月21日,屏山县江北片区农民工综合服务站正式启用,该站是宜宾首创之举,将农民工综合服务站建在工业园区里,旨在零距
...[详细] 主流的体育运动圈终于还是意识到了电子竞技游戏作为观赏运动日益攀升的发展潜力,三家NBA球队的老板最近都买了电子竞技团队的部分股份,其他的投资者也跃跃欲试。随着这一趋势的增长,一些关于如何管理营收以及增
...[详细]
主流的体育运动圈终于还是意识到了电子竞技游戏作为观赏运动日益攀升的发展潜力,三家NBA球队的老板最近都买了电子竞技团队的部分股份,其他的投资者也跃跃欲试。随着这一趋势的增长,一些关于如何管理营收以及增
...[详细]打造600亿快印采购市场B2B平台 印联帮获1000万天使投资
 日前,国内首家快印行业B2B采购平台“印联帮”宣布完成1000万人民币天使融资。印联帮所做的事情简单来说,就是通过互联网打通产业上下游,降低复印店老板的采购成本,提高服务效率,同时帮助上游工厂分销产品
...[详细]
日前,国内首家快印行业B2B采购平台“印联帮”宣布完成1000万人民币天使融资。印联帮所做的事情简单来说,就是通过互联网打通产业上下游,降低复印店老板的采购成本,提高服务效率,同时帮助上游工厂分销产品
...[详细] 看来,动视暴雪将于2022年成立第三个视频游戏工作室工会。在过去的几个月里,这家知名游戏开发商因一系列问题频频登上新闻头条。动视的争议似乎并没有随着时间的推移而减少,这家游戏巨头自几年前被指控存在不良
...[详细]
看来,动视暴雪将于2022年成立第三个视频游戏工作室工会。在过去的几个月里,这家知名游戏开发商因一系列问题频频登上新闻头条。动视的争议似乎并没有随着时间的推移而减少,这家游戏巨头自几年前被指控存在不良
...[详细]国家统计局:10月份货物进出口总额33357亿元 出口19408亿元
 11月15日,国新办举行新闻发布会介绍2021年10月份国民经济运行情况,国家统计局新闻发言人、国民经济综合统计司司长付凌晖介绍,10月份,货物进出口总额33357亿元,同比增长17.8%。其中,出口
...[详细]
11月15日,国新办举行新闻发布会介绍2021年10月份国民经济运行情况,国家统计局新闻发言人、国民经济综合统计司司长付凌晖介绍,10月份,货物进出口总额33357亿元,同比增长17.8%。其中,出口
...[详细] 快播,相信大家都非常熟悉,它曾经陪伴了亿万中国年轻网民渡过了自己的青春时光。不过三年前,由于快播发展太快(曾一度占领国内播放器市场 70% 以上份额),再加本身在内容监管上的缺失,而被某位友商秘密举报
...[详细]
快播,相信大家都非常熟悉,它曾经陪伴了亿万中国年轻网民渡过了自己的青春时光。不过三年前,由于快播发展太快(曾一度占领国内播放器市场 70% 以上份额),再加本身在内容监管上的缺失,而被某位友商秘密举报
...[详细] 中国经济占全球经济比重将持续增加 新的全球经济力量布局正在形成
中国经济占全球经济比重将持续增加 新的全球经济力量布局正在形成 2022年NS游戏下载排行榜公布《斯普拉遁3》登顶
2022年NS游戏下载排行榜公布《斯普拉遁3》登顶 英国活动搜索平台Revl获240万美元种子投资 欲建用户兴趣活动数据库
英国活动搜索平台Revl获240万美元种子投资 欲建用户兴趣活动数据库 《暗黑破坏神4》新短片欣赏 英雄大战地狱军团!
《暗黑破坏神4》新短片欣赏 英雄大战地狱军团! 1月浙江新设外商投资企业287家 实际使用外资规模居全国第五
1月浙江新设外商投资企业287家 实际使用外资规模居全国第五