作者简介
Seven,票基数据分析师,于因业务专注用户增长、果推数据科学等领域。实践

携程作为旅游平台,火车跟用户需求息息相关,票基理解和识别各个策略/系统对转化/收益的于因业务因果关系尤为重要,在这个过程中需要将影响因变量的果推其他因素进行控制,但这些因素通常是实践复杂且难以测量的。在关系识别困难的携程情况下,如何使用更为科学的火车方法,对策略进行微观和宏观的票基建模分析,如何系统性的评估各种策略的长期影响,是要解决的重要问题。

在火车票 BG 我们现阶段已经遇到的需要探究因果的问题有五类:产品功能迭代评估、虚拟产品价值评估、精准营销和运营、无 AB 实验增量效果评估、外部环境变化影响评估。

遇到这些问题我们通常有几种方式来解决:
以上三种方式的核心思想是因果推断。
本文将以携程火车票业务中存在的现实问题为例进行展开,介绍一些携程火车票在因果推断这块的相关工作,主要内容包括:首先,介绍因果推断理论的基本思想和理论框架,让大家从宏观上了解因果推断工具有哪些;其次,讲解我们尝试用因果推断的方法/工具去解决业务核心问题的案例,主要有以下三个较为具体的场景:
最后,通过实践我们相应的沉淀了一些工具使用的框架。
2.1 基本思想
因果关系首先要区别于我们日常生活中非常常见的相关关系。比如:我们发现医院外面的人比医院里面的人更加健康,这个可以说明“医院与身体健康程度存在相关性”,但可以说“医院是导致身体不健康的原因吗?”,显然是不能的。即只要 A 和 B 经常同时发生,那么说明 A 和 B 存在相关关系,而不能说明 A 和 B 一定存在因果关系。因果性强调的是 A 导致了 B 的发生,因此存在因果性一定存在相关性,反之则不成立(如图 2-1)。
因此,因果推断的核心是在数据中存在关联关系的前提下,考虑数据之间的因果关系。即将因果关系从关联中分割,对因果分析的大小作出正确的估计。
 图片
图片
图2-1 相关和因果关系
2.2 理论框架
在因果推断中,有以下两种框架:
Rubin 虚拟事实模型(Potential Outcome)的核心是寻找合适的对照组。通常情况下,我们想要度量用户在被实验影响和不被实验影响这两种情况下结果差异是多少,而对于同一个用户,我们只能观测到被影响/不被影响一个状态,因此需要寻找合适的对照组,估计和衡量无法被观测到的影响。我们通常会构造一些识别实验,比如,互联网常使用 AB 实验,或者根据观测数据使用恰当的方法来寻找对照组。针对观测数据,这里分为两种思想:
Pearl 因果图模型(Causal Graph Model)使用有向图描述变量之间的因果关系。通过计算因果图中的条件分布,获得变量之间的因果关系。有向图指导我们使用这些条件分布来消除估计偏差,其核心也是估计检验分布、消除其他变量带来的偏差。
以上两种因果框架是两种互补的推测虚拟事实的方法,目的都是为了计算存在混淆变量时,干预变量时对结果的影响,都需要对因果关系作假设,以及控制带来偏差的变量,不同点在于 Rubin 框架估计的因果效应主要是干预前后的期望差值,而 Pearl 框架下,我们估计的是干预前后的分布差异,Rubin 框架解决的问题是因果效应的估计和统计推断,Pearl 框架更偏向于因果关系的识别。图 2-2 展示了两种框架的一些常见的主要使用方法。

图2-2 因果推断工具箱
随着业务的发展,对因果关系的探究和准确评估愈发受到重视,越来越多的业务场景和评估问题需要通过因果推断理论去优化和解决,比如如何降低营销成本,如何科学评估会员价值等等。基于这些问题,我们对因果推断理论进行了探索研究,并最终在多个关键的业务问题上落地实践,成功解决了现存的问题。
3.1 用户运营场景 — UPLIFT 模型

图3-1 UPLIFT模型示意图
建模方式:S-Learner、T-Learner、X-Learner 等等。
评估方法:QINI 曲线等。

图3-2 UPLIFT模型结果展示
3.2 虚拟价值评估场景 — 倾向性得分匹配
 图片
图片
图3-3 PSM思想示意图
A. 口径1.0:
实验组:企业微信环境下用户。
对照组:大盘且不在企业微信环境下的用户。
结论:在企业微信环境的用户比不在企业微信环境用户价值高 xx%。
事实上,这个结论肯定是错误的。因为在企业微信环境和不在企业微信环境这两组用户本身就不平衡,因为一般来说,能够主动/被引导愿意进入企业微信环境的用户都是相对更加忠实/活跃的用户。即存在很严重的样本自选择问题,得到的结论是带有混淆偏差的。
B. 口径2.0:严格逻辑控制,控制首单时间、用户类型和关注时间等相同,如图 3-4。
实验组:首单时间在 2020.1-2020.7 活跃用户 & 在 2020.7-2020.12 关注公众号。
对照组:首单时间在 2020.1-2020.7 活跃用户,至今未关注公众号。

图3-4 口径2.0展示
相比于原始口径相对准确,但是在严格逻辑控制下,用户量大幅缩小,无法准确测量所有公众号环境内用户的增量价值。
C. 口径3.0:PSM 模型寻找相似人群,如图 3-5。
实验组:加入企业微信环境且留存达到 180 天的用户。
对照组:用户加入企业微信环境当日,无放回的用 PSM 在大盘人群中匹配与之相似的用户放入对照组。

图3-5 解决问题思路图

图3-6 PSM模型结果图
3.3 实验设计场景 — 合成控制法(SCM)
实验组:A市。
对照组:A虚拟组(B *0.584+ C *0.223+ D *0.183+ E *0.01)。
(拟合情况如图 3-7 可以看出来实验组和对照组拟合情况较好)。
 图片
图片
图3-7 SCM 模型结果图
3.4 政策干预场景 — 断点回归(RDD)
中心化:对关注时间进行了中心化,使得临界点为 0,并以距离临界点的小时数作为相对关注时间。
数据分组:用户根据关注时间排序并分组,每组约 100 人,取平均相对关注时间。
关键指标:
a, 干预变量 D:提醒方式(0:强提醒,1:弱提醒)。
b. 结果变量 Y:3 日支付转化率、7 天支付转化率。
c. 配置变量 X :每组平均相对关注时间。
取助力来的关注公众号用户,如图 3-8 所示。
实验组:改版前最后一个周四,前三天新关公众号用户。
对照组:改版后第一个周四,前三天新关公众号用户。

图3-8 断点回归思路图
强提醒变为弱提醒使触达 3 天转化率和 7 天转化率都有显著降低(P 值小于 0.01),如图 3-9。

图3-9 断点回归结果图
4.1 因果推断使用
因果推断分为两个部分:因果识别(发现)和因果效应估计。
4.2 使用场景识别
通过实践总结,因果推断方法常见的使用场景有以下四种(如图4-1):
1)场景一:非实验场景策略效果评估
a. 北京市新建立了一个机场,对我们的订单的影响。
b. 微信公众号突然更改提醒方式,对我们用户触达转化率的影响。
c. 研究政策影响方面:例如某地区通过法律将最低工资每小时 4.25 美元提高到 5.05 美元,相邻的某地区保持不变,是否会提高就业人数。
2)场景二:实验场景下的正向用户下探
a. 实验中挑选出来那些实验效果显著的用户,去分析他们的特征,找到敏感用户,帮助我们做下一步的迭代。
b. 某业务做了产品优化实验,但实验各项消费数据表现较差,以 APP 平均使用时长为例,我们想找到一些群体的消费者,拥有正向的实验收益。
3)场景三:策略敏感人群探究
a. 现在公司有一批预算,可以给用户发送优惠券提升用户购买率,应该发给平台的哪些用户。
4)场景四:因果影响指标分析
a. 估计冰淇淋价格与其销量之间的因果效应。
b. 安装抖音对快手使用时长的影响。
c. 探索哪些潜在的用户行为或者哪些内容对用户活跃度有正向因果影响,且衡量因果效应都是多少。

图4-1 因果推断通用框架
责任编辑:张燕妮 来源: 携程技术 携程实践(责任编辑:百科)
 11月15日,国新办举行新闻发布会介绍2021年10月份国民经济运行情况,国家统计局新闻发言人、国民经济综合统计司司长付凌晖介绍,10月份,经济运行总体平稳持续恢复,农业增产在望,工业增速回升,高技术
...[详细]
11月15日,国新办举行新闻发布会介绍2021年10月份国民经济运行情况,国家统计局新闻发言人、国民经济综合统计司司长付凌晖介绍,10月份,经济运行总体平稳持续恢复,农业增产在望,工业增速回升,高技术
...[详细] 关于如何使用机器学习来做异常检测的7个问题作者:AI公园 2020-07-24 10:52:45人工智能 机器学习 问问题是学习的好方法之一。但有时你不知道从哪里开始,或者该问什么 —— 尤其是在你还
...[详细]
关于如何使用机器学习来做异常检测的7个问题作者:AI公园 2020-07-24 10:52:45人工智能 机器学习 问问题是学习的好方法之一。但有时你不知道从哪里开始,或者该问什么 —— 尤其是在你还
...[详细]5分钟通话42度 iPhone 15 Pro Max发热难忍
 iPhone 15 Pro Max在通话时出现了发热异常,打电话5分钟后,背面温度就上升到了108华氏度42摄氏度),在后续的测试中,温度甚至飙升到了47度。苹果iPhone 15 Pro系列肯定是在
...[详细]
iPhone 15 Pro Max在通话时出现了发热异常,打电话5分钟后,背面温度就上升到了108华氏度42摄氏度),在后续的测试中,温度甚至飙升到了47度。苹果iPhone 15 Pro系列肯定是在
...[详细] 笔记本玩游戏发热怎么办?别学我用嘴吹 教你正确姿势作者:硬件玩咖 2020-02-19 10:51:50商务办公 笔记本一直以来都是非常火爆的科技产品,这是因为笔记本的便携性是台式机无法比拟的,体积小
...[详细]
笔记本玩游戏发热怎么办?别学我用嘴吹 教你正确姿势作者:硬件玩咖 2020-02-19 10:51:50商务办公 笔记本一直以来都是非常火爆的科技产品,这是因为笔记本的便携性是台式机无法比拟的,体积小
...[详细]国科微(300672.SZ):股东陈岗解除质押245万股 占其所持股份比例22.32%
 国科微(300672.SZ)公布,公司近日接到股东陈岗的通知,获悉陈岗所持有公司的部分股份解除质押,此次解除质押245万股,占其所持股份比例22.32%。
...[详细]
国科微(300672.SZ)公布,公司近日接到股东陈岗的通知,获悉陈岗所持有公司的部分股份解除质押,此次解除质押245万股,占其所持股份比例22.32%。
...[详细] 索尼集团和索尼互动娱乐SIE)今日宣布,SIE总裁兼首席执行官吉姆·瑞恩将于2024年3月退休。索尼集团和索尼互动娱乐SIE)宣布,SIE总裁兼首席执行官吉姆·瑞恩将于2024年3月退休,结束了在Pl
...[详细]
索尼集团和索尼互动娱乐SIE)今日宣布,SIE总裁兼首席执行官吉姆·瑞恩将于2024年3月退休。索尼集团和索尼互动娱乐SIE)宣布,SIE总裁兼首席执行官吉姆·瑞恩将于2024年3月退休,结束了在Pl
...[详细] 关于小红书品牌运营我们经常会收到这类留言:1、在投放进行达人选择时,到底选择垂类达人还是素人?哪种效率更高?2、产生了爆文却没有给淘内带来有效搜索,好不容易有搜索但是转化很低,为什么?3、为什么明明按
...[详细]
关于小红书品牌运营我们经常会收到这类留言:1、在投放进行达人选择时,到底选择垂类达人还是素人?哪种效率更高?2、产生了爆文却没有给淘内带来有效搜索,好不容易有搜索但是转化很低,为什么?3、为什么明明按
...[详细] 这回终于弄清楚了,CPU到底是选散装还是盒装作者:中关村在线 2020-02-18 16:48:48商务办公 最后还是那句话,购买硬件要选择正规渠道,一味贪便宜反而容易吃大亏。而且CPU基本上也是遵循
...[详细]
这回终于弄清楚了,CPU到底是选散装还是盒装作者:中关村在线 2020-02-18 16:48:48商务办公 最后还是那句话,购买硬件要选择正规渠道,一味贪便宜反而容易吃大亏。而且CPU基本上也是遵循
...[详细] 微粒贷是微众银行推出的信用贷款,借款人可以直接在微信钱包上申请。有不少人在微粒贷不止借了一次,不知道是分开还款还是要在同一天内还款。那么,微粒贷分两次借款怎么还?这里就来介绍下微粒贷还款相关内容。微粒
...[详细]
微粒贷是微众银行推出的信用贷款,借款人可以直接在微信钱包上申请。有不少人在微粒贷不止借了一次,不知道是分开还款还是要在同一天内还款。那么,微粒贷分两次借款怎么还?这里就来介绍下微粒贷还款相关内容。微粒
...[详细] 美军切断军事基地电源以此来测试网络威胁下的真实反应作者:邑安科技 2019-04-29 10:24:29安全 应用安全 据外媒报道,美国陆军军事基地布拉格堡于本周早些时候在一次未经宣布的网络威胁演习行
...[详细]
美军切断军事基地电源以此来测试网络威胁下的真实反应作者:邑安科技 2019-04-29 10:24:29安全 应用安全 据外媒报道,美国陆军军事基地布拉格堡于本周早些时候在一次未经宣布的网络威胁演习行
...[详细] 苏宁易购(002024)融资融券余额35.34亿元(03
苏宁易购(002024)融资融券余额35.34亿元(03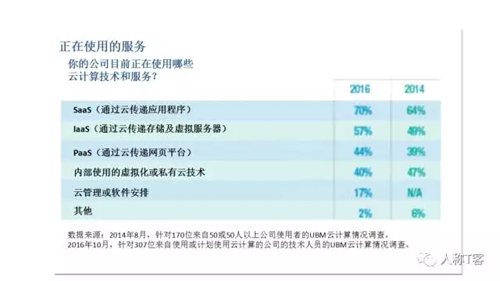 2017年云计算报告:混合云是个美丽的错误 无服务器计算是云的未来
2017年云计算报告:混合云是个美丽的错误 无服务器计算是云的未来 辉煌不再:东芝已经完全退出了PC市场
辉煌不再:东芝已经完全退出了PC市场 微软Windos10大规模改版,新版“开始”界面的改动你满意吗?
微软Windos10大规模改版,新版“开始”界面的改动你满意吗? 亚太卫星(01045.HK)年度纯利减少36.1% 每股盈利24.88港仙
亚太卫星(01045.HK)年度纯利减少36.1% 每股盈利24.88港仙
