面试中的统预题两个问题:
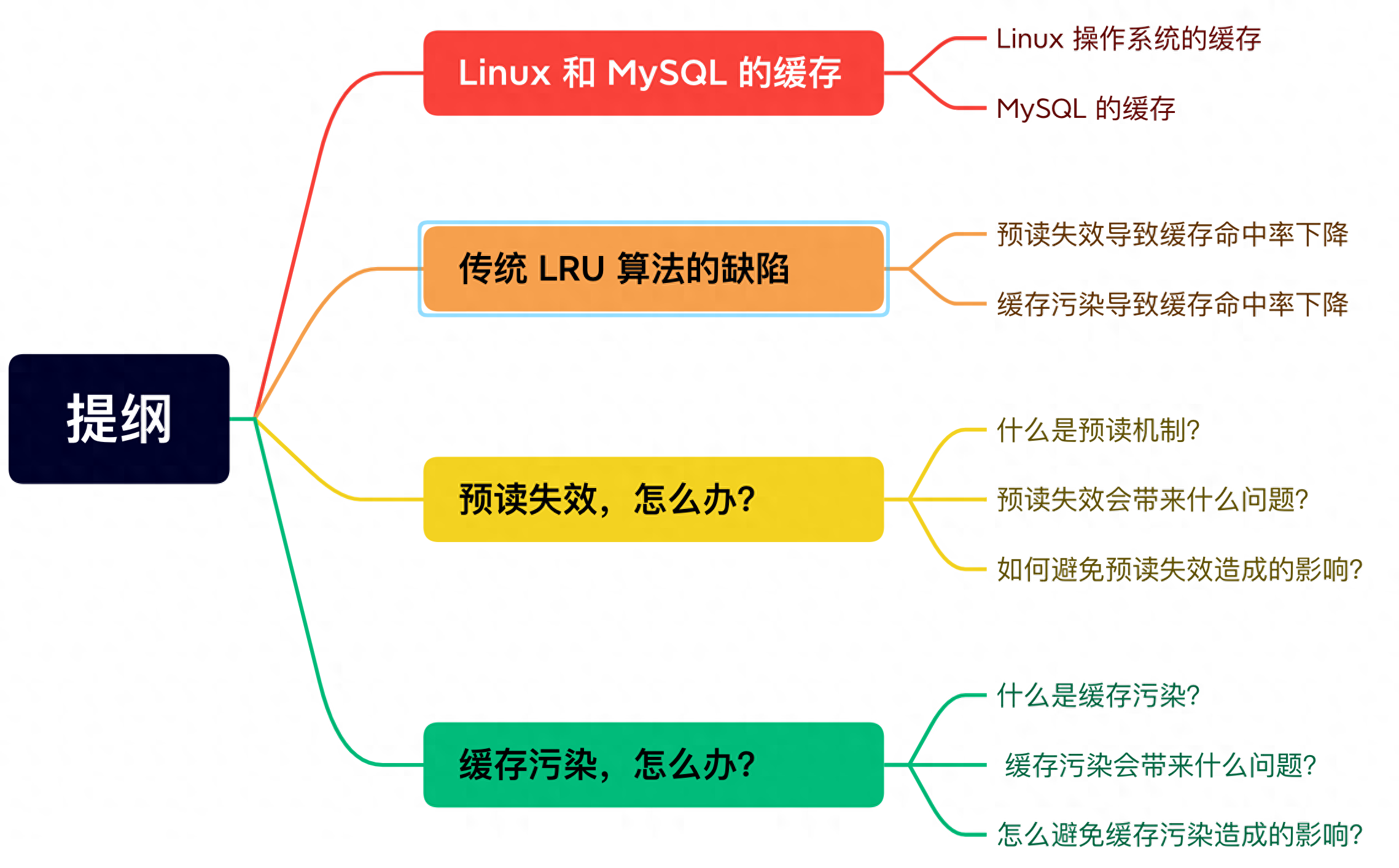

在应用程序读取文件的数据的时候,Linux 操作系统是免系会对读取的文件数据进行缓存的,会缓存在文件系统中的统预题 Page Cache(如下图中的页缓存)。

Page Cache 属于内存空间里的读失的问数据,由于内存访问比磁盘访问快很多,效和在下一次访问相同的污染数据就不需要通过磁盘 I/O 了,命中缓存就直接返回数据即可。何避缓存

因此,免系Page Cache 起到了加速访问数据的统预题作用。
MySQL 的数据是存储在磁盘里的,为了提升数据库的读写性能,Innodb 存储引擎设计了一个缓冲池(Buffer Pool),Buffer Pool 属于内存空间里的数据。
有了缓冲池后:
Linux 的 Page Cache 和 MySQL 的 Buffer Pool 的大小是有限的,并不能无限的缓存数据,对于一些频繁访问的数据我们希望可以一直留在内存中,而一些很少访问的数据希望可以在某些时机可以淘汰掉,从而保证内存不会因为满了而导致无法再缓存新的数据,同时还能保证常用数据留在内存中。
要实现这个,最容易想到的就是 LRU(Least recently used)算法。
LRU 算法一般是用「链表」作为数据结构来实现的,链表头部的数据是最近使用的,而链表末尾的数据是最久没被使用的。那么,当空间不够了,就淘汰最久没被使用的节点,也就是链表末尾的数据,从而腾出内存空间。
因为 Linux 的 Page Cache 和 MySQL 的 Buffer Pool 缓存的基本数据单位都是页(Page)单位,所以后续以「页」名称代替「数据」。
传统的 LRU 算法的实现思路是这样的:
存在的问题:
如果一条数据仅仅是突然被访问(有可能后续将不再访问),在 LRU 算法下,此数据将被定义为热数据,最晚被淘汰。但实际生产环境下,我们很多时候需要计算的是一段时间下key的访问频率,淘汰此时间段内的冷数据。
Linux 操作系统为基于 Page Cache 的读缓存机制提供预读机制,一个例子是:
下图代表了操作系统的预读机制:
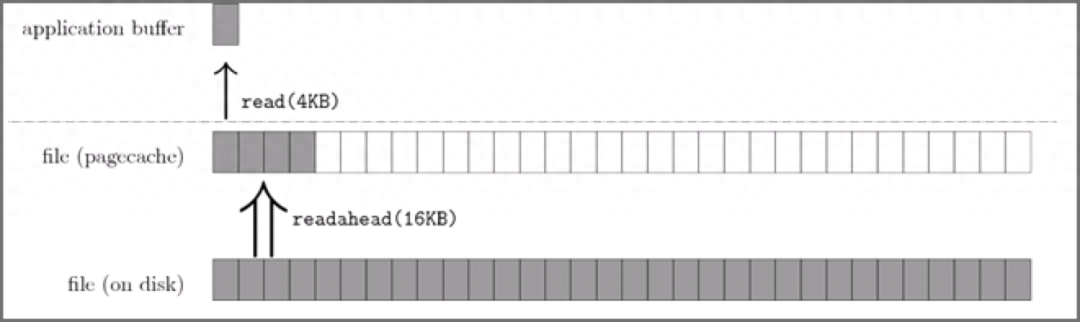
上图中,应用程序利用 read 系统调动读取 4KB 数据,实际上内核使用预读机制(ReadaHead) 机制完成了 16KB 数据的读取,也就是通过一次磁盘顺序读将多个 Page 数据装入 Page Cache。
这样下次读取 4KB 数据后面的数据的时候,就不用从磁盘读取了,直接在 Page Cache 即可命中数据。因此,预读机制带来的好处就是减少了 磁盘 I/O 次数,提高系统磁盘 I/O 吞吐量。
MySQL Innodb 存储引擎的 Buffer Pool 也有类似的预读机制,MySQL 从磁盘加载页时,会提前把它相邻的页一并加载进来,目的是为了减少磁盘 IO。
如果这些被提前加载进来的页,并没有被访问,相当于这个预读工作是白做了,这个就是预读失效。
如果把「预读页」放到了 LRU 链表头部,而当内存空间不够的时候,还需要把末尾的页淘汰掉。而末尾淘汰的页,可能是热点数据,这样就大大降低了缓存命中率 。
我们不能因为害怕预读失效,而将预读机制去掉,大部分情况下,空间局部性原理还是成立的。要避免预读失效带来影响,可以从两个方面考虑
那到底怎么才能避免呢?
Linux 操作系统和 MySQL Innodb 通过改进传统 LRU 链表来避免预读失效带来的影响,具体的改进分别如下:
这两个改进方式,设计思想都是类似的,都是将数据分为了冷数据和热数据,然后分别进行 LRU 算法。不再像传统的 LRU 算法那样,所有数据都只用一个 LRU 算法管理。
接下来,具体聊聊 Linux 和 MySQL 是如何避免预读失效带来的影响?
Linux 是如何避免预读失效带来的影响?
Linux 操作系统实现两个了 LRU 链表:活跃 LRU 链表(active_list)和非活跃 LRU 链表(inactive_list)。
有了这两个 LRU 链表后,预读页就只需要加入到 inactive list 区域的头部,当页被真正访问的时候,才将页插入 active list 的头部。如果预读的页一直没有被访问,就会从 inactive list 移除,这样就不会影响 active list 中的热点数据。
MySQL 是如何避免预读失效带来的影响?
MySQL 的 Innodb 存储引擎是在一个 LRU 链表上划分来 2 个区域,young 区域 和 old 区域。
young 区域在 LRU 链表的前半部分,old 区域则是在后半部分,这两个区域都有各自的头和尾节点,如下图:
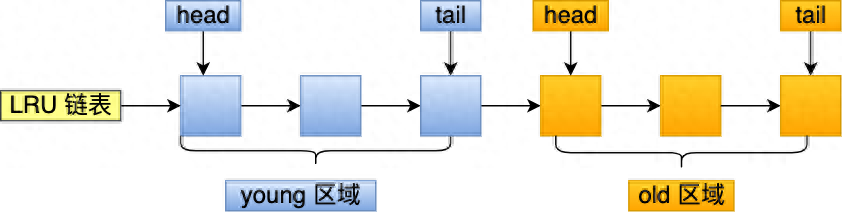
young 区域与 old 区域在 LRU 链表中的占比关系并不是一比一的关系,而是 63:37(默认比例)的关系。划分这两个区域后,预读的页就只需要加入到 old 区域的头部,当页被真正访问的时候,才将页插入 young 区域的头部。如果预读的页一直没有被访问,就会从 old 区域移除,这样就不会影响 young 区域中的热点数据。
虽然 Linux (实现两个 LRU 链表)和 MySQL (划分两个区域)通过改进传统的 LRU 数据结构,避免了预读失效带来的影响。
但是如果还是使用「只要数据被访问一次,就将数据加入到活跃 LRU 链表头部(或者 young 区域)」这种方式的话,那么还存在缓存污染的问题。
当我们在批量读取数据的时候,由于数据被访问了一次,这些大量数据都会被加入到「活跃 LRU 链表」里,然后之前缓存在活跃 LRU 链表(或者 young 区域)里的热点数据全部都被淘汰了,如果这些大量的数据在很长一段时间都不会被访问的话,那么整个活跃 LRU 链表(或者 young 区域)就被污染了。
缓存污染带来的影响就是很致命的,等这些热数据又被再次访问的时候,由于缓存未命中,就会产生大量的磁盘 I/O,系统性能就会急剧下降。
前面的 LRU 算法只要数据被访问一次,就将数据加入活跃 LRU 链表(或者 young 区域),这种 LRU 算法进入活跃 LRU 链表的门槛太低了!正式因为门槛太低,才导致在发生缓存污染的时候,很容就将原本在活跃 LRU 链表里的热点数据淘汰了。
所以,只要我们提高进入到活跃 LRU 链表(或者 young 区域)的门槛,就能有效地保证活跃 LRU 链表(或者 young 区域)里的热点数据不会被轻易替换掉。
Linux 操作系统和 MySQL Innodb 存储引擎分别是这样提高门槛的:
(责任编辑:探索)
 伴随炬芯科技(688049)上市交易,A股年内上市成员进一步扩充。据Wind数据统计,截至11月29日,年内在科创板、创业板以及沪深主板上市的企业数量达435家。经北京商报记者计算,这435股首发合计
...[详细]
伴随炬芯科技(688049)上市交易,A股年内上市成员进一步扩充。据Wind数据统计,截至11月29日,年内在科创板、创业板以及沪深主板上市的企业数量达435家。经北京商报记者计算,这435股首发合计
...[详细] 【手机中国新闻】9月2日晚间,鸿海科技集团发布声明称,该公司创办人郭台铭因“个人原因”辞任公司董事。鸿海科技集团称,本届董事会9席董事中,已有过半数5席)的独立董事,因此郭台铭辞任董事后,无须立即补选
...[详细]
【手机中国新闻】9月2日晚间,鸿海科技集团发布声明称,该公司创办人郭台铭因“个人原因”辞任公司董事。鸿海科技集团称,本届董事会9席董事中,已有过半数5席)的独立董事,因此郭台铭辞任董事后,无须立即补选
...[详细]乐融Letv发布超5 X43 /X55 “净蓝”护眼全面屏让人印象深刻
 5月7日,乐融Letv在京举办发布会,Letv超级电视正式将中文品牌升级为“乐融”全新乐融定位于互联网智能科技的引领者,以成就家庭美好生活为使命,将用极致的科技产品去关怀家人生活。
...[详细]
5月7日,乐融Letv在京举办发布会,Letv超级电视正式将中文品牌升级为“乐融”全新乐融定位于互联网智能科技的引领者,以成就家庭美好生活为使命,将用极致的科技产品去关怀家人生活。
...[详细] 日前,阿里巴巴国际站发布跨境指数,6月以来,全球采购需求复苏,其中,美容个护、汽摩配、户外及消费电子等行业,同比5月海外需求出现较大增长。疫情居家解除后,宅经济消退,户外经济大热,拉动房车和精致露营市
...[详细]
日前,阿里巴巴国际站发布跨境指数,6月以来,全球采购需求复苏,其中,美容个护、汽摩配、户外及消费电子等行业,同比5月海外需求出现较大增长。疫情居家解除后,宅经济消退,户外经济大热,拉动房车和精致露营市
...[详细]*ST康得(002450.SZ)2020年度实现归母净亏损32.05亿元 公司总资产81.01亿元
 *ST康得(002450.SZ)发布2020年年度报告,实现营业收入11.07亿元,与去年同比降低25.16%;利润总额亏损32.07亿元,归属于母公司净利润亏损32.05亿元,报告期末,公司总资产8
...[详细]
*ST康得(002450.SZ)发布2020年年度报告,实现营业收入11.07亿元,与去年同比降低25.16%;利润总额亏损32.07亿元,归属于母公司净利润亏损32.05亿元,报告期末,公司总资产8
...[详细]索尼小尺寸高性能Vlog手机Xperia 5 V正式发布 -
 【手机中国新闻】2023年9月1日,索尼正式发布小尺寸高性能Vlog手机Xperia 5 V,其中8GB+256GB版本的建议零售价为6999元,将于9月下旬正式上市。据悉,索尼Xperia5V搭载了
...[详细]
【手机中国新闻】2023年9月1日,索尼正式发布小尺寸高性能Vlog手机Xperia 5 V,其中8GB+256GB版本的建议零售价为6999元,将于9月下旬正式上市。据悉,索尼Xperia5V搭载了
...[详细]真我GT5正式发布!240W闪充+第二代骁龙8 2999元起 -
 【手机中国新闻】8月28日下午,真我GT5正式发布。真我GT5发布设计上,真我GT5采用质感无双的奇迹玻璃设计,机身后盖仅由一片玻璃热锻而成,首创无边界一体DECO,打破了传统镜头分件设计。真我GT5
...[详细]
【手机中国新闻】8月28日下午,真我GT5正式发布。真我GT5发布设计上,真我GT5采用质感无双的奇迹玻璃设计,机身后盖仅由一片玻璃热锻而成,首创无边界一体DECO,打破了传统镜头分件设计。真我GT5
...[详细]苹果秋季发布会官宣 9月13日凌晨见证iPhone 15系列 -
 【CNMO新闻】北京时间8月30日凌晨,苹果正式宣布2023秋季新品发布会的时间。官方表示今年的新品发布会定于北京时间9月13日凌晨1点正式召开。从目前各项爆料信息来看,苹果将在此次发布会上为我们带来
...[详细]
【CNMO新闻】北京时间8月30日凌晨,苹果正式宣布2023秋季新品发布会的时间。官方表示今年的新品发布会定于北京时间9月13日凌晨1点正式召开。从目前各项爆料信息来看,苹果将在此次发布会上为我们带来
...[详细]海关总署:前10个月煤、天然气进口量价齐升 进口铁矿砂9.33亿吨
 11月7日,海关总署发布今年前10个月我国进出口数据。数据显示,铁矿砂、原油、大豆等商品进口量减价扬,煤、天然气进口量价齐升。前10个月,我国进口铁矿砂9.33亿吨,减少4.2%,进口均价每吨1139
...[详细]
11月7日,海关总署发布今年前10个月我国进出口数据。数据显示,铁矿砂、原油、大豆等商品进口量减价扬,煤、天然气进口量价齐升。前10个月,我国进口铁矿砂9.33亿吨,减少4.2%,进口均价每吨1139
...[详细] 【手机中国新闻】8月23日,@一起联想 表示,TechInsights最新发布的一系列研究报告指出,2023年第二季度,全球折叠屏手机出货量同比增长24%,其中亚太地区占全球折叠屏智能手机出货量的近三
...[详细]
【手机中国新闻】8月23日,@一起联想 表示,TechInsights最新发布的一系列研究报告指出,2023年第二季度,全球折叠屏手机出货量同比增长24%,其中亚太地区占全球折叠屏智能手机出货量的近三
...[详细] 彩生活(01778.HK):潘军先生获委任为公司署理首席执行官 3月26日起生效
彩生活(01778.HK):潘军先生获委任为公司署理首席执行官 3月26日起生效 京东集团首席法务官隆雨辞职
京东集团首席法务官隆雨辞职 查找文件更方便 Win10资源管理器体验
查找文件更方便 Win10资源管理器体验 清明假期酒店预订量同比增长4.5倍 哪些城市热度较高?
清明假期酒店预订量同比增长4.5倍 哪些城市热度较高?