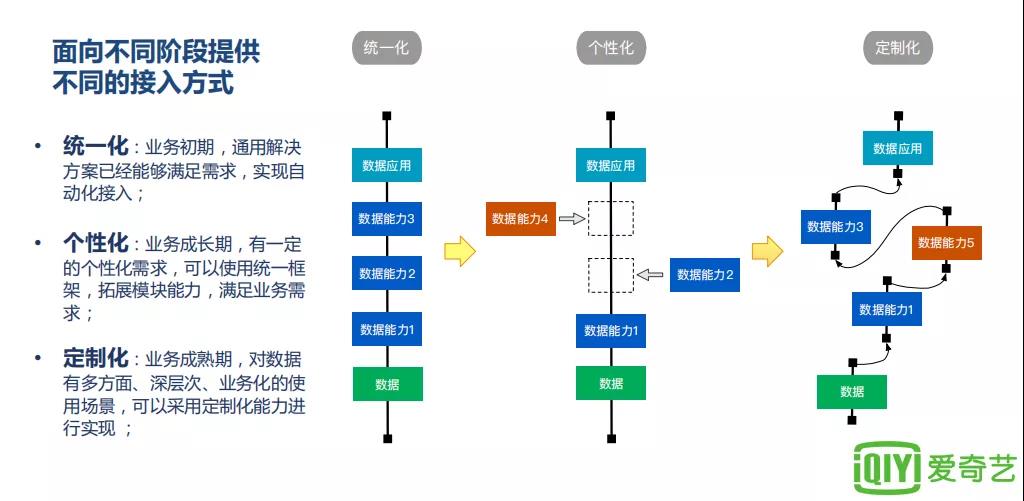
大型语言模型可以说是提出推理现代自然语言处理技术的基石了,比如1750亿参数的面刷GPT-3,5400亿参数的排行PaLM,预训练模型为下游任务提供了非常强大的北大榜few-shot learning的能力。
但推理任务仍然是硕士一个难关,尤其是提出推理需要多步骤推理才能得到正确答案的问题。

最近有研究人员发现,面刷只要设计合适的排行prompt就能引导模型进行多步骤的推理来生成最终答案,这种方法也称为思维链(chain-of-thought)推理。

思维链技术在算术基准GSM8K上将准确率从17.9%提升到了58.1%,后来引入的投票自洽(self-consistency)机制进一步将准确率提升到74.4%

简单来说,复杂的推理任务通常有多个能得到正确答案的推理路径,自洽方法通过思维链从语言模型中采样一组不同的推理路径,然后返回其中最自洽的答案。

最近,来自北大和微软的研究人员基于自洽的新方法DiVeRSe,包含三个主要的创新点,进一步提升了模型的推理能力。

论文链接:https://arxiv.org/abs/2206.02336
代码链接:https://github.com/microsoft/DiVeRSe
第一,受到自洽方式「想法不同,答案相同」的启发,即从语言模型中采样不同的推理路径,DiVeRSe在多样性上更进一步,按照「条条大路通罗马」的理念,使用多个prompt生成答案,能够生成更完整、互补的答案。

研究人员首先对每个问题提供5个不同的prompts,然后对每个prompt采样出20个推理路径,最后就可以对每个问题生成100个解答推理路径。
一个关键的问题是如何获取不同的prompt,假定已经获取一个样例库后,我们可以从中采样K个样例来构造一个prompt,然后重复5次即可
如果没有足够的样例,则采用self-teaching的方式提升prompt多样性,即从一部分样例中生成伪推理路径和<问题,答案>对。

第二,在生成推理路径时,语言模型中并不存在一种机制来纠正先前步骤中的错误,可能会导致最终预测结果的混乱。DiVeRSe借鉴verifier的思想,对每个推理路径的正确性进行验证来引导投票机制。也就是说,并非所有的推理机制都是相等重要的或都是好的。
假设我们对一个问题有100条推理路径,其中60条的结果为「答案是110」,而40条路径的结果为「答案是150」。如果没有验证器(即原始自洽方法),「答案是110」为多数票,所以我们可以将110视为最终答案,并删除结果为150的40条推理路径。
verifier则是对推理路径进行打分,函数f由一个二分类器训练得到,输入为问题x,路径z和答案y,输出为positive的概率。

有verifier后,假设「答案是110」的60条推理路径的平均得分是0.3;「答案是150」的40条推理路径的平均得分是0.8。 那么最终的答案应该是150,因为40*0.8>60*0.3
第三,由于答案是基于多个步骤的推理而产生的,当一个路径生成一个正确的答案时,可以认为所有的步骤都对最终的正确性做出了贡献。然而,当生成一个错误的答案时,这并不意味着所有的步骤都是错误的或对错误有贡献。
换句话说,尽管结果错了,中间一些步骤可能仍然是正确的,但一些后续的偏离方向的步骤导致了最终的错误答案。DiVeRSe设计了一个机制,为每个步骤分配一个细粒度的标签,并提出了一个step-aware的验证器,并将正确性分配到每个步骤的推理上,而非只看最终的答案。

主体仍然是一个二分类器,但关键的问题为如何获得step-level的负标签,因为如果最终的答案错误,没有人工的参与,我们并不知道哪步出错,而正确的答案则过程应该都是正确的。
研究人员提出supports的概念,比如在算术任务中,需要有另外一个样例的中间结果和该中间步骤的结果相同。

基于这三点改进,研究人员在5个算数推理数据集上进行实验,可以看到在基于code-davinci-002的DiVeRSe方法都取得了新的SOTA算法,平均的提升率为6.2%

在两个常识推理任务上,DiVeRSe的性能略低于基于PaLM的自洽(-2.2%),推测原因可能是常识推理任务是多项选择任务,而不是开放性的生成任务,导致了出现了更多false-positive的伪例证。
在归纳推理任务上,DiVeRSe在CLUTRR任务上取得了95.9%的成绩,超过了之前SOTA的微调结果(+28.9%)
在消融实验中,可以看到voting verifier机制对性能的提升是比较明显的。

而在大多数实验中,将voting verifier扩展为step-aware版本可以带来性能的提升。对于GSM8K上的code-davinci-002,step-aware版本的verifier则会导致性能略有下降。
可能的原因为code-davinci-002更强大,可以为GSM8K产生更高质量的推理路径,从而减少步骤级信息的必要性,即text-davinci更容易生成短/不完整的推理路径,而code-davinci对生成长内容更友好。

论文的第一作者为Yifei Li,于2020年本科毕业于东北大学软件工程专业,目前硕士就读于北京大学,主要研究方向为自然语言处理,特别是大规模语言模型中的prompt-tuning和推理。
文章的第二作者为Zeqi Lin,为微软亚洲研究院DKI研究员,分别于2014年和2019年获得北京大学的学士和博士学位,主要研究方向为机器学习及其在软件分析和数据分析中的应用。
责任编辑:张燕妮 来源: 新智元 算法人工智能(责任编辑:娱乐)
 申请了网贷之后,借款人就需要按照合同内规定的还款日进行按期还款。如果在还款日到来当天,借款人仍然没有还款,第二天就会被视为逾期,逾期之后,借款人的征信就会有信用污点。趣分期逾期记录怎么消除?趣分期和来
...[详细]
申请了网贷之后,借款人就需要按照合同内规定的还款日进行按期还款。如果在还款日到来当天,借款人仍然没有还款,第二天就会被视为逾期,逾期之后,借款人的征信就会有信用污点。趣分期逾期记录怎么消除?趣分期和来
...[详细] 丈夫向朋友借钱偿还信用卡透支款,后久久未把钱还给朋友,妻子遭起诉与丈夫共同承担还款责任。日前,广西贵港市港北区人民法院对这起民间借贷纠纷案作出一审判决,被告何先生、王女士共同向原告杨某偿还借款本金18
...[详细]
丈夫向朋友借钱偿还信用卡透支款,后久久未把钱还给朋友,妻子遭起诉与丈夫共同承担还款责任。日前,广西贵港市港北区人民法院对这起民间借贷纠纷案作出一审判决,被告何先生、王女士共同向原告杨某偿还借款本金18
...[详细] 本周以来国际黄金涨势有所恢复,但美元的继续走强对金价形成了一定损害,由于美国数据改善提升了美国联邦储备加息的预测期望。本周五虽然美元表现强势,抑制了金价的上涨,但是黄金价格依然录得上涨,其主要原因就是
...[详细]
本周以来国际黄金涨势有所恢复,但美元的继续走强对金价形成了一定损害,由于美国数据改善提升了美国联邦储备加息的预测期望。本周五虽然美元表现强势,抑制了金价的上涨,但是黄金价格依然录得上涨,其主要原因就是
...[详细] 步入2020年,很多上市公司纷纷发布2019年年报业绩预告或业绩快报。《证券日报》记者根据同花顺数据统计后发现,截至2月5日收盘,沪深两市共有100家上市公司发布了2019年年报业绩快报,有77家上市
...[详细]
步入2020年,很多上市公司纷纷发布2019年年报业绩预告或业绩快报。《证券日报》记者根据同花顺数据统计后发现,截至2月5日收盘,沪深两市共有100家上市公司发布了2019年年报业绩快报,有77家上市
...[详细]安徽:截止10月底各级财政累计拨付民生工程资金1213.2亿元
 记者近日从省财政厅获悉,截至10月底,全省各级财政累计拨付民生工程资金1213.2亿元,完成全年计划的103.4%。33项民生工程深入推进,美丽乡村建设、农村危房改造、农村饮水工程养护、城乡卫生机构标
...[详细]
记者近日从省财政厅获悉,截至10月底,全省各级财政累计拨付民生工程资金1213.2亿元,完成全年计划的103.4%。33项民生工程深入推进,美丽乡村建设、农村危房改造、农村饮水工程养护、城乡卫生机构标
...[详细]评论:311家公司2019年年报预喜 两维度筛选26只高分红潜力股
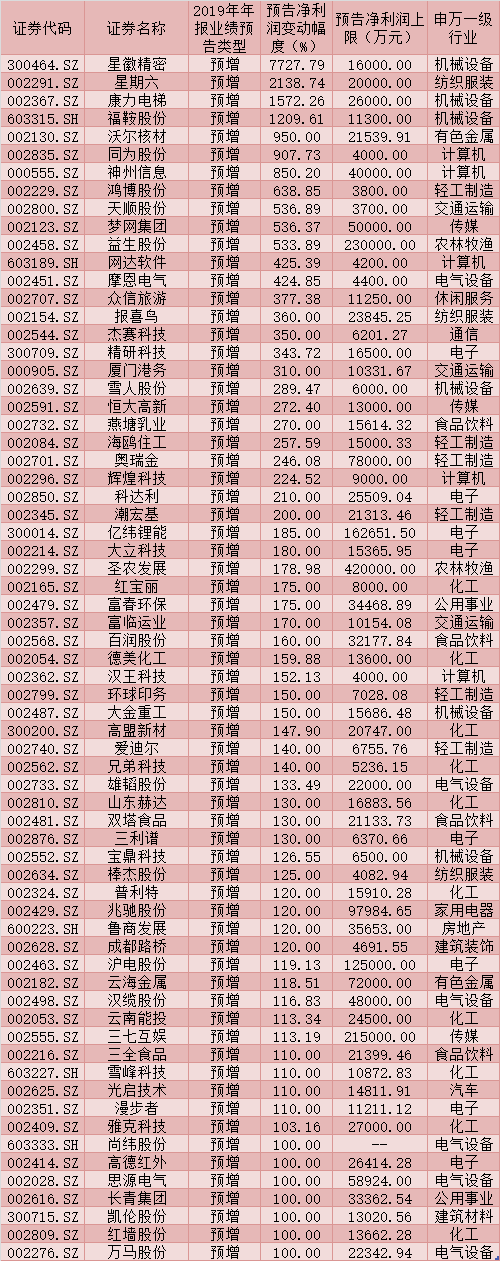 随着上市公司2019年年报披露逐渐临近,2019年年报业绩预告的数量也加速递增,资金对年报业绩预期向好的优质标的关注度持续提高。对此,分析人士普遍表示,从日历效应和宏观数据空窗期的角度考虑,&ldqu
...[详细]
随着上市公司2019年年报披露逐渐临近,2019年年报业绩预告的数量也加速递增,资金对年报业绩预期向好的优质标的关注度持续提高。对此,分析人士普遍表示,从日历效应和宏观数据空窗期的角度考虑,&ldqu
...[详细] 《证券日报》记者根据同花顺数据统计发现,截至2月11日,两融余额达10408.28亿元,较2月3日开市以来增长170.01亿元。从市场角度分析,两融余额的回升与近期市场持续回暖以及活跃的题材板块轮动有
...[详细]
《证券日报》记者根据同花顺数据统计发现,截至2月11日,两融余额达10408.28亿元,较2月3日开市以来增长170.01亿元。从市场角度分析,两融余额的回升与近期市场持续回暖以及活跃的题材板块轮动有
...[详细] 年报题材是岁末年初A股市场最合时令的操作主线。日前股指持续调整,正好提供了逢低布局的机会,而那些业绩向好的成长股同时也具有较高的安全边际,在春节即将来临之时,投资者普遍对年报行情寄予厚望。《证券日报》
...[详细]
年报题材是岁末年初A股市场最合时令的操作主线。日前股指持续调整,正好提供了逢低布局的机会,而那些业绩向好的成长股同时也具有较高的安全边际,在春节即将来临之时,投资者普遍对年报行情寄予厚望。《证券日报》
...[详细] 需要注意啦,清明节一共放假三天的时间,而且高速也会免费通行。现在消息指出,清明假期火车票开售啦,节前一天北京前往郑州、武汉等地车票热销,想要去哪里游玩,记得提前预订车票。同时,3月20日可以购买4月3
...[详细]
需要注意啦,清明节一共放假三天的时间,而且高速也会免费通行。现在消息指出,清明假期火车票开售啦,节前一天北京前往郑州、武汉等地车票热销,想要去哪里游玩,记得提前预订车票。同时,3月20日可以购买4月3
...[详细] 周一,A股三大股指集体走强,全线飘红。截至收盘,上证指数和深证成指涨幅分别达0.66%和1.47%。创业板指表现突出,强势领涨飙升2.57%,创出2017年1月份以来的三年新高,继续向2000点大关靠
...[详细]
周一,A股三大股指集体走强,全线飘红。截至收盘,上证指数和深证成指涨幅分别达0.66%和1.47%。创业板指表现突出,强势领涨飙升2.57%,创出2017年1月份以来的三年新高,继续向2000点大关靠
...[详细] 花呗升级和不升级区别在哪里 可用额度会增加吗?
花呗升级和不升级区别在哪里 可用额度会增加吗? 江西九江市提高社区工作人员待遇
江西九江市提高社区工作人员待遇 国资委:央企复工复产率超80% 本月底口罩产能每天将达160万只以上
国资委:央企复工复产率超80% 本月底口罩产能每天将达160万只以上 四方面勾勒5G发展蓝图 超过七成公司年报业绩预喜
四方面勾勒5G发展蓝图 超过七成公司年报业绩预喜 股票熔断什么意思?上证指数跌多少触发熔断?
股票熔断什么意思?上证指数跌多少触发熔断?