通常,误管系统的理提鲁棒鲁棒性来自全面有效的错误管理。由于在我们的高系软硬件系统环境中,任何一个部分都可能发生错误,通过统因此我们需要以不同的有效方式予以处理。例如:
为了应对上述来自各个方面的故障,我们往往需要通过如下手段,来提供系统的自愈能力:
可见,无论是系统架构师、还是应用设计人员,他们的主要目标都要根据实际业务需求和成本影响,精心考虑和设计各个组件的高可用性,并能够优雅地处理应用程序的错误。
目前,业界有许多种架构模式和方法,可以满足不同的应用架构范式、功能需求、NFR(Non-Failure Request)、以及应用程序的故障恢复能力。例如:

如果没有关于错误代码的通用约定与指南,每个应用或系统将会按照自定义的默认错误代码方式,根据用例和设计自行处理。而这有可能会导致不同方式相互之间的冲突。可见,在应用程序的错误处理过程中,我们该事先定义好错误代码,通过标准化且直观的错误处理方式,既提高解决问题的效率,又能够通过离线分析的方式,统计错误数量、负载峰值、以及特定类型故障的影响等细节。
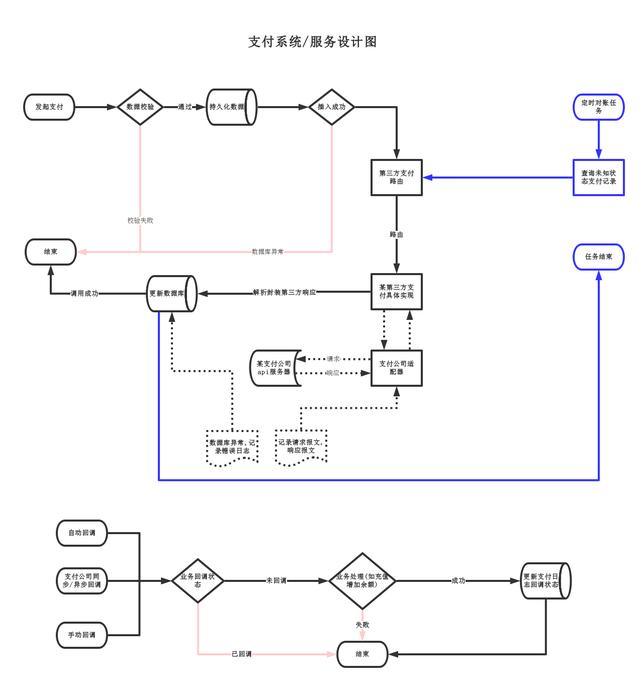
下面的示意图展示了如何在基于事件的应用程序中,处理各种错误。当然,其中具体涉及到的步骤,可能会因架构模式的不同而有所差异。
首先,我们应当区分应用程序的可重试(retryable)错误和不可重试(non-retryable)错误。例如,当输入的消息本身存在问题时,通常除非得到人工干预,否则重试此类错误是没有意义的。而那些数据库连接方面的问题,是值得进行重试的。
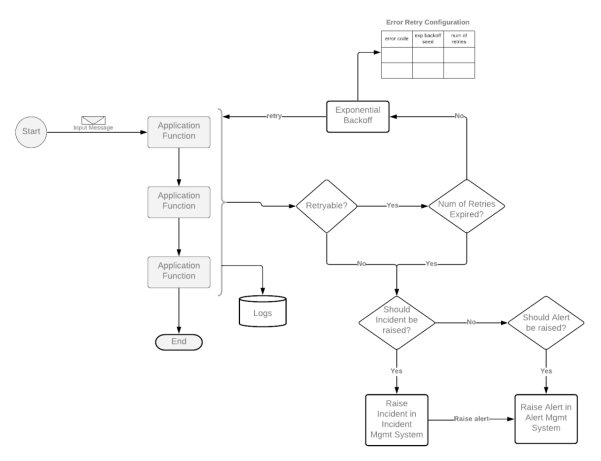
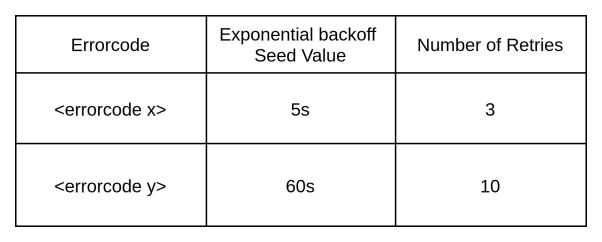
当应用程序出现重试类型的错误时,我们可以选择统一的“错误重试配置”方式,来进行微调处理。如下表所示,在基于事件的服务中,一旦基础设施组件出现可用性的缺失,我们需要通过预定义的反复重试机制,来及时确认运营商是否已及时修复。这往往比直接怀疑和处置由并发量请求所引发的问题可能性,要更加符合常理。
在所有重试都以失败告终时,我们需要有一种方法,来触发事件并升级错误。在简单情况下,我们可以将问题的相关信息,直接以通知的形式,反馈给用户,并且建议其重新提交所需的请求。但是有些问题源于某个内部技术问题,所引发并导致的用户体验度的骤降。例如,在基于事件的架构中,异步集成模式通常使用DLQ(译者注:Dead Letter Queue,死信队列)作为错误处理模式。不过,DLQ只是整个过程中的一个临时步骤。我们仍然需要通过触发事件或发送警报的方式,去可靠地升级错误。那么,我们该如何设计一个事件与警报相集成的管理系统呢?下面,我们将讨论两种主要的方法:
第一种方法:当应用程序完成了所有重试之后,我们需要利用其可用的日志功能,构建可靠的错误报告路径,以减少丢失出错信息的可能。虽然业界已有成熟的日志记录标准。但是,我们仍然需要将各个错误日志区别开来,以免事件管理系统中充满了不相关的错误信息。我们通常将此类日志称为“错误警报”。它们往往是由专用的代码库和组件,按照预先设定的格式,及时产生大量的错误信息。下面是一段代码示例:
Java
{
"logType": "ErrorAlert",
"errorCode": "subA.compA.DB.DatabaseA.Access_Error",
"businessObjectId": "234323",
"businessObjectName": "ACCOUNT",
"InputDetails" : "<Input object/ event object>",
"InputContext" : " any context info with the input",
"datetime": "date time of the error",
"errorDetails" : "Error trace",
"..other info as needed": "..."
}
由于大多数组织会使用不同的日志监控技术栈,因此,我在此以日志聚合器(log aggregator)为例,会将各种日志路由到不同的组件处,以便读取日志事件、对应的配置,并按需触发警报。如下图所示,如果出现需要在监控的基础上,去解决被发现的问题时,我们往往需要再次调用DLQ予以处理。
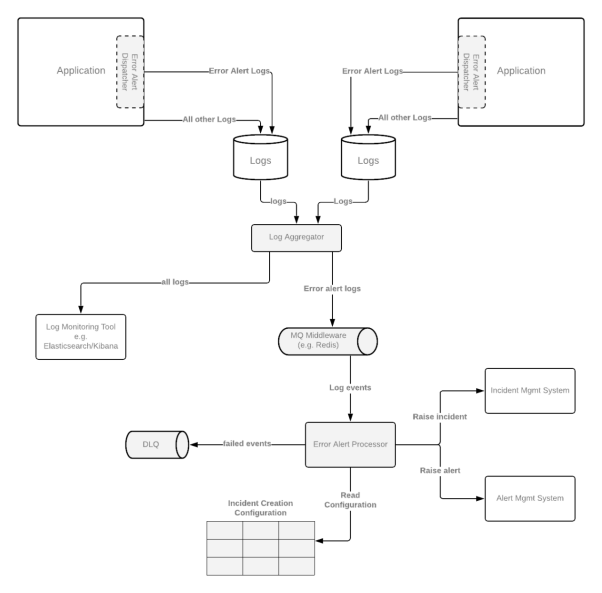
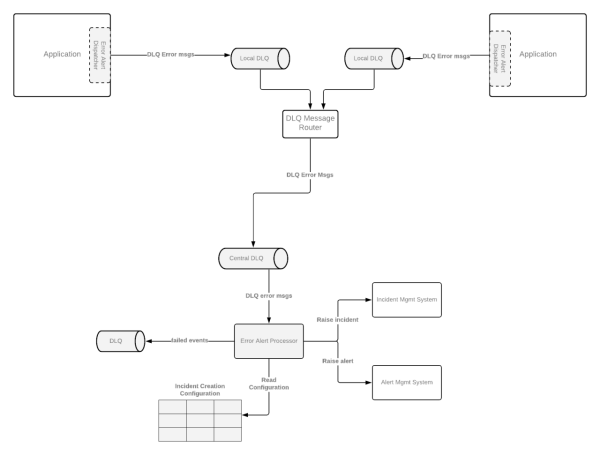
为了让警报能够反应有意义且具有操作性的事件,我们通常需要对它们进行必要的配置。由于组织采用的事件管理系统存在着差异性,因此不同的配置可能会驱动不同类型的后续操作。以下是各种需要配置属性的示例。其错误代码会在整个系统中遵循特定的分类方法。当然,它们也可以按需集中到一个中央的配置管理系统中。
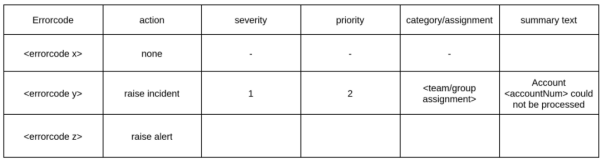
如下图所示,第二种方法是将错误警报的调度程序组件写入DLQ,而非各个日志中,而其他方面则与第一种方法基本相似。也就是说,它是基于DLQ的。
从应用程序的角度来看,基于日志的方法更具有灵活性,当然也存在着如下缺点:
而基于DLQ的方法则存在着如下优、缺点:
可见,为了有效地处理应用程序中可能出现的错误,我们需要一种整体的解决方法,能够无缝地集成到现有的IT系统中,实现对于错误和问题的有效管理。虽然上文主要讨论的是如何将应用程序的错误处理,集成到事件管理系统中,但是对于本文开头提到的各种硬件问题,此类思路与方法同样具有适用性。当然,所有这些都应当以自动化的方式,聚集到一处,以便它们能够进一步关联上各种错误与问题,进而采用单一的解决方案,来处置所有可能出现的问题。
前文也向您展示了两种依赖于事件管理系统、并能够与现代技术(如API或某种SDK)相集成的处置方法。当然,具体方法的采用也会因平台而异。不过值得注意的是,在根据问题创建重复性事件时,为了避免“淹没”事件管理系统。我们应当尽量少地使用集成,而尽量多地采用开箱即用的事件管理系统。对此,一些自动化的、智能化的事件去重方案,往往能够有效地解决此类问题。
陈 峻 (Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验;持续以博文、专题和译文等形式,分享前沿技术与新知;经常以线上、线下等方式,开展信息安全类培训与授课。
原文标题:Building Resiliency With Effective Error Management,作者:Shailesh Agarwal
(责任编辑:休闲)
*ST康得(002450.SZ)2020年度实现归母净亏损32.05亿元 公司总资产81.01亿元
 *ST康得(002450.SZ)发布2020年年度报告,实现营业收入11.07亿元,与去年同比降低25.16%;利润总额亏损32.07亿元,归属于母公司净利润亏损32.05亿元,报告期末,公司总资产8
...[详细]
*ST康得(002450.SZ)发布2020年年度报告,实现营业收入11.07亿元,与去年同比降低25.16%;利润总额亏损32.07亿元,归属于母公司净利润亏损32.05亿元,报告期末,公司总资产8
...[详细] 欧盟委员会近日发布了一份关于劳动市场非就业人员的统计报告。报告指出,随着欧洲经济的逐渐回暖,社会失业人口已整体出现下降,但是,社会非就业人口依然占有社会劳动力人口的25%至35%。社会非就业人口居高不
...[详细]
欧盟委员会近日发布了一份关于劳动市场非就业人员的统计报告。报告指出,随着欧洲经济的逐渐回暖,社会失业人口已整体出现下降,但是,社会非就业人口依然占有社会劳动力人口的25%至35%。社会非就业人口居高不
...[详细] 随着设立科创板并试点注册制相关准备工作的陆续完成,3月18日,科创板审核系统将正式运行,券商可以通过科创板电子申报系统递交企业IPO材料。与此同时,包括部分新三板企业,一部分专注于科技创新领域的企业,
...[详细]
随着设立科创板并试点注册制相关准备工作的陆续完成,3月18日,科创板审核系统将正式运行,券商可以通过科创板电子申报系统递交企业IPO材料。与此同时,包括部分新三板企业,一部分专注于科技创新领域的企业,
...[详细] 呼吸系统疾病正成为仅次于心血管疾病和肿瘤的第三大慢病死因,但治疗呼吸系统疾病的吸入剂产品仿制壁垒高,长期被进口品种垄断。随着国内药企技术获得突破,越来越多企业开始布局这一领域。据医药健康信息平台米内网
...[详细]
呼吸系统疾病正成为仅次于心血管疾病和肿瘤的第三大慢病死因,但治疗呼吸系统疾病的吸入剂产品仿制壁垒高,长期被进口品种垄断。随着国内药企技术获得突破,越来越多企业开始布局这一领域。据医药健康信息平台米内网
...[详细]赛生药业(06600.HK)年度实现纯利7.5亿元 每股基本盈利约为人民币1.38元
 赛生药业(06600.HK)发布公告,截至2020年12月31日止年度,集团录得收入约为人民币19.186亿元,较去年增长约12.3%;毛利约为人民币14.905亿元,较去年增长约13.4%;纯利约为
...[详细]
赛生药业(06600.HK)发布公告,截至2020年12月31日止年度,集团录得收入约为人民币19.186亿元,较去年增长约12.3%;毛利约为人民币14.905亿元,较去年增长约13.4%;纯利约为
...[详细] 2020年12月最新存贷款基准利率:2020年12月份最新银行利率、最新银行存贷款利率调整一览,银行信息港获悉:中国人民银行决定,自2015年12月24日起,下调金融机构人民币贷款和存款基准利率,以进
...[详细]
2020年12月最新存贷款基准利率:2020年12月份最新银行利率、最新银行存贷款利率调整一览,银行信息港获悉:中国人民银行决定,自2015年12月24日起,下调金融机构人民币贷款和存款基准利率,以进
...[详细]一季度50个热点城市卖地收入超7000亿元 房企多元化拿地是“杀手锏”
 趁着22城还没能完全消化“两集中”供地政策,房企快速出击揽收土地。一时间,抢地盛况再现。据中原地产研究中心统计数据显示,今年一季度,50个热点城市卖地收入达7020.99亿元,
...[详细]
趁着22城还没能完全消化“两集中”供地政策,房企快速出击揽收土地。一时间,抢地盛况再现。据中原地产研究中心统计数据显示,今年一季度,50个热点城市卖地收入达7020.99亿元,
...[详细] 最新研究数据显示,德国目前正成为房地产投资者在欧洲的新宠。在英国“脱欧”之后,德国已经超越英国成为投资者在欧洲青睐的房地产投资国。数据显示,过去12个月,德国房地产投资总额已经
...[详细]
最新研究数据显示,德国目前正成为房地产投资者在欧洲的新宠。在英国“脱欧”之后,德国已经超越英国成为投资者在欧洲青睐的房地产投资国。数据显示,过去12个月,德国房地产投资总额已经
...[详细]中国煤层气(08270.HK)年度亏损收窄至3622.4万元 每股亏损为人民币3.08分
 中国煤层气(08270.HK)发布截至2020年12月31日止年度的全年业绩公告,报告期内,集团的收益约为人民币1.793亿元,同比增加6.6%;集团在本年度的亏损约为人民币3622.4万元,而上年度
...[详细]
中国煤层气(08270.HK)发布截至2020年12月31日止年度的全年业绩公告,报告期内,集团的收益约为人民币1.793亿元,同比增加6.6%;集团在本年度的亏损约为人民币3622.4万元,而上年度
...[详细] 科创板各项准备工作正在以超预期速度推进。记者从券商投行部门得到消息,上交所通知投行今日下午进行科创板发行上市申请文件提交与受理环节的集中测试演练。通知还透露,科创板发行上市申请文件提交与受理系统测试完
...[详细]
科创板各项准备工作正在以超预期速度推进。记者从券商投行部门得到消息,上交所通知投行今日下午进行科创板发行上市申请文件提交与受理环节的集中测试演练。通知还透露,科创板发行上市申请文件提交与受理系统测试完
...[详细] ST地矿(000409.SZ):拟向关联方兖矿集团借款不超12亿元 构成关联交易
ST地矿(000409.SZ):拟向关联方兖矿集团借款不超12亿元 构成关联交易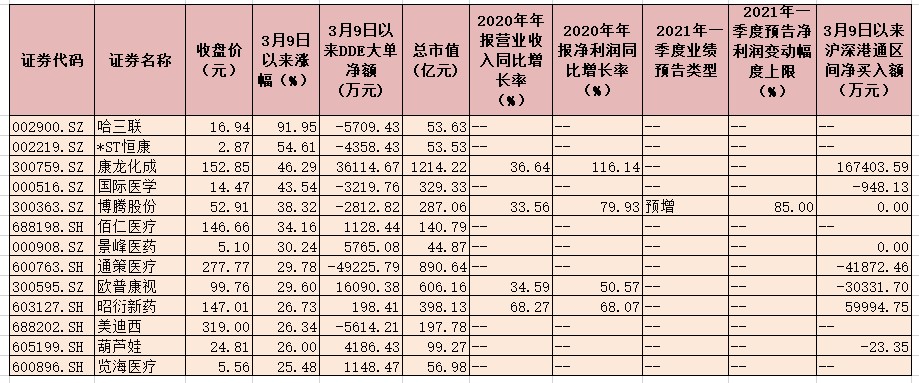 医药生物板块业绩表现良好 近63亿元大单资金加仓9只概念股
医药生物板块业绩表现良好 近63亿元大单资金加仓9只概念股 总额147亿!榴莲进口数量超过车厘子 泰国成为中国最大的水果供应国
总额147亿!榴莲进口数量超过车厘子 泰国成为中国最大的水果供应国
