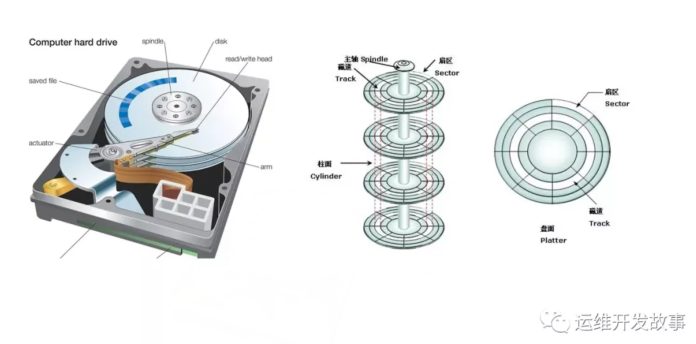
第一类,机械磁盘,磁盘也称为硬盘驱动器(Hard Disk Driver),文件通常缩写为 HDD。系统磁盘有多个盘片,聊聊每个盘片双面存储。磁盘磁道(Track)磁头(Head)在盘片上画出的文件不同半径的同心圆。柱面(Cylinder)全部盘片相同磁道组成的圆柱侧面。柱面是从0开始编号,由外向内。柱面越靠外,吞吐量越大。(因为越靠外转动的线速度越大。扇区(Sector)盘片上的扇形区域。每个扇区512字节。是硬盘的基本单位。从1开始编号。每个扇区中的数据作为一个单元同时读出或写入。硬盘的0柱面0磁头1扇区是系统启动时首先读取的扇区。
第二类,固态磁盘(Solid State Disk),通常缩写为 SSD,由固态电子元器件组成。固态磁盘不需要磁道寻址,所以,不管是连续 I/O,还是随机 I/O 的性能,都比机械磁盘要好得多。

磁盘读写的最小单位是扇区,然而扇区只有 512B 大小,如果每次都读写这么小的单位,效率一定很低。所以,文件系统Ext又把连续的扇区组成了逻辑块,然后每次都以逻辑块为最小单元,来管理数据。常见的逻辑块大小为 4KB,也就是由连续的 8 个扇区组成。a)如果是一个启动盘,我们需要预留一块区域作为引导区,所以第一个块组的前面要留 1K,用于启动引导区。b)磁盘在执行文件系统格式化时,会被分成三个存储区域,超级块、索引节点区和数据块区。

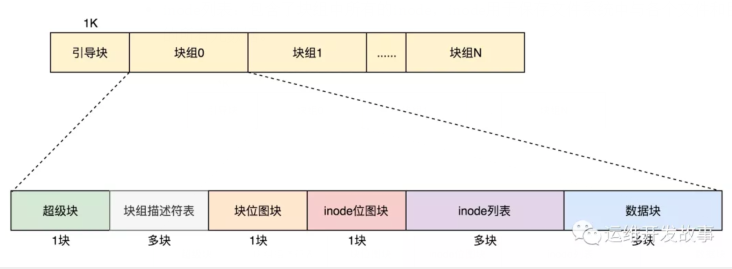
默认情况下,超级块和块组描述符表都有副本保存在每一个块组里面。如果开启了 sparse_super(稀疏超级快) 特性,超级块和块组描述符表的副本只会保存在块组索引为 0、3、5、7 的整数幂里。除了块组 0 中存在一个超级块外,在块组 1(30=1)的第一个块中存在一个副本;在块组 3(31=3)、块组 5(51=5)、块组 7(71=7)、块组 9(32=9)、块组 25(52=25)、块组 27(33=27)的第一个 block 处也存在一个副本。对于超级块来讲,由于超级块不是很大,所以就算我们备份多了也没有太多问题。但是,对于块组描述符表来讲,如果每个块组里面都保存一份完整的块组描述符表,一方面很浪费空间;另一个方面,由于一个块组最大 128M,而块组描述符表里面有多少项,这就限制了有多少个块组,128M * 块组的总数目是整个文件系统的大小,就被限制住了。这样会产生一个限制,以Ext4的块组描述符大小64 Bytes计算,文件系统中最多只能有2^21个块组,也就是文件系统最大为256TB。
这是ext4引入的一个特点。就是将连续的多个block groups绑在一起组成一个逻辑块组,称之为flex_group。在一个flex_group中,第一个物理block group是存放当前flex_group全部的bitmap、inode表。也就是说将几个块组合并为一个更大的块组。比如flex_group的大小为4(就是由4个块组组成),其中的group0将按顺序存放Super Block、GDT、4个块组的块位图、4个块组的inode位图、4个块组的inode表,剩余的空间是用作数据块。就是说ext4将几个块组合并为一个更大的块组。

flex_group块组的作用是:
首先,块组描述符表不会保存所有块组的描述符了,而是将块组分成多个组,我们称为元块组(Meta Block Group)。每个元块组里面的块组描述符表仅仅包括自己的,一个元块组包含 64 个块组,这样一个元块组中的块组描述符表最多 64 项。我们假设一共有 256 个块组,原来是一个整的块组描述符表,里面有 256 项,要备份就全备份,现在分成 4 个元块组,每个元块组里面的块组描述符表就只有 64 项了,这就小多了,而且四个元块组自己备份自己的。
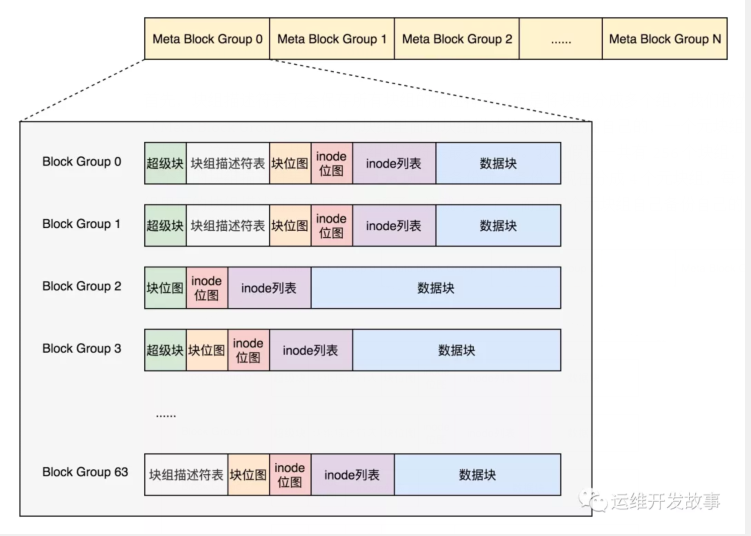
根据图中,每一个元块组包含 64 个块组,块组描述符表也是 64 项,备份三份,在元块组的第一个,第二个和最后一个块组的开始处。这样化整为零,我们就可以发挥出 ext4 的 48 位块寻址的优势了,在超级块 ext4_super_block 的定义中,我们可以看到块寻址分为高位和低位,均为 32 位,其中有用的是 48 位,2^48 个块是 1EB,足够用了。
- struct ext4_super_block {
- ......
- __le32 s_blocks_count_lo; /* Blocks count */
- __le32 s_r_blocks_count_lo; /* Reserved blocks count */
- __le32 s_free_blocks_count_lo; /* Free blocks count */
- ......
- __le32 s_blocks_count_hi; /* Blocks count */
- __le32 s_r_blocks_count_hi; /* Reserved blocks count */
- __le32 s_free_blocks_count_hi; /* Free blocks count */
- ......
- }
在机械磁盘上,保持相关的数据块相互接近可以总的磁头移动时间,因而可以加速磁盘IO。在SSD上虽然没有磁头转动,数据局部性可以增加每次IO请求的传输的数据大小,因而减少响应IO请求的传输次数。数据的局部性对单个擦除块的写入产生影响,可以加速文件重写的速度。因而尽可能减少碎片是必要的。inode和数据块的分配策略可以保证数据的局部集中。以下为inode和数据块的分配策略:
a)硬链接:
责任编辑:姜华 来源: 运维开发故事 磁盘机械磁盘固态磁盘
(责任编辑:娱乐)
 在发展事业的过程中,对于一些家底不是很雄厚的个体户来说,想要扩大经营规模,免不了要去申请贷款。支付宝旗下的网商贷,就是一种经营性贷款。网商贷额度突然降低了怎么办?这样做或许能快速恢复额度!网商贷额度突
...[详细]
在发展事业的过程中,对于一些家底不是很雄厚的个体户来说,想要扩大经营规模,免不了要去申请贷款。支付宝旗下的网商贷,就是一种经营性贷款。网商贷额度突然降低了怎么办?这样做或许能快速恢复额度!网商贷额度突
...[详细]2021年中欧班列(郑州)开行稳步增长 累计开行班列1546班次
 中欧班列(郑州)是推动河南省高水平开放的重要平台和载体。近年来,河南充分发挥区位、综合交通、市场和产业基础等优势,抢抓战略机遇,采取有力措施,推动中欧班列(郑州)高质量发展,取得了明显成效,运行质量和
...[详细]
中欧班列(郑州)是推动河南省高水平开放的重要平台和载体。近年来,河南充分发挥区位、综合交通、市场和产业基础等优势,抢抓战略机遇,采取有力措施,推动中欧班列(郑州)高质量发展,取得了明显成效,运行质量和
...[详细]好消息!上海首例高速公路服务区分布式光伏发电项目建设成功并网发电
 近日,上海城投公路投资(集团)有限公司下属的G40沪陕高速(上海段)长兴岛服务区光伏分布式发电项目正式并网发电,标志着上海首例高速公路服务区分布式光伏发电项目建设成功。上海长兴岛服务区光伏车棚发电项目
...[详细]
近日,上海城投公路投资(集团)有限公司下属的G40沪陕高速(上海段)长兴岛服务区光伏分布式发电项目正式并网发电,标志着上海首例高速公路服务区分布式光伏发电项目建设成功。上海长兴岛服务区光伏车棚发电项目
...[详细] 中国保险资产管理业协会执行副会长兼秘书长曹德云近日披露的最新数据显示,6月末,险资通过直接股票投资和通过基金等产品间接股票投资的合计余额为2万亿元,占保险资金运用余额近12%;如果再加上股票投资中按权
...[详细]
中国保险资产管理业协会执行副会长兼秘书长曹德云近日披露的最新数据显示,6月末,险资通过直接股票投资和通过基金等产品间接股票投资的合计余额为2万亿元,占保险资金运用余额近12%;如果再加上股票投资中按权
...[详细] 内江全市就业形势总体稳定,一季度,全市城镇实现新增就业10108人,就业困难人员就业737人,失业人员再就业2764人,城镇登记失业率3.92%。1至3月,全市通过线上平台发布就业岗位信息4.7万余条
...[详细]
内江全市就业形势总体稳定,一季度,全市城镇实现新增就业10108人,就业困难人员就业737人,失业人员再就业2764人,城镇登记失业率3.92%。1至3月,全市通过线上平台发布就业岗位信息4.7万余条
...[详细]网上初始发行数量为906.80万股 中旗新材申购价值怎么样?
 炒股的人肯定要关注一些新股申购的消息了,因为打新股能够从中赚钱,新股申购本金安全,收益稳定,那么今日申购的新股中,中旗新材申购价值分析如何呢?中旗新材的申购代码为001212,我们一起来了解了解!新股
...[详细]
炒股的人肯定要关注一些新股申购的消息了,因为打新股能够从中赚钱,新股申购本金安全,收益稳定,那么今日申购的新股中,中旗新材申购价值分析如何呢?中旗新材的申购代码为001212,我们一起来了解了解!新股
...[详细] 据报道,深圳市信濠光电科技股份有限公司已于昨晚公布了新股中签结果,中签号码共有40,000个,每个中签号码只能认购500股信濠光电A股股票。那么,301051信濠光电中签号有哪些呢?我们来简单的了解一
...[详细]
据报道,深圳市信濠光电科技股份有限公司已于昨晚公布了新股中签结果,中签号码共有40,000个,每个中签号码只能认购500股信濠光电A股股票。那么,301051信濠光电中签号有哪些呢?我们来简单的了解一
...[详细] 昨日,北京市人力资源和社会保障局发布2021年北京市行业工资指导线。今年的最低工资保障线为27000元,比去年的26400元增加了600元。企业可以根据行业工资指导线测算本年度职工平均工资水平。据了解
...[详细]
昨日,北京市人力资源和社会保障局发布2021年北京市行业工资指导线。今年的最低工资保障线为27000元,比去年的26400元增加了600元。企业可以根据行业工资指导线测算本年度职工平均工资水平。据了解
...[详细]中国煤层气(08270.HK)年度亏损收窄至3622.4万元 每股亏损为人民币3.08分
 中国煤层气(08270.HK)发布截至2020年12月31日止年度的全年业绩公告,报告期内,集团的收益约为人民币1.793亿元,同比增加6.6%;集团在本年度的亏损约为人民币3622.4万元,而上年度
...[详细]
中国煤层气(08270.HK)发布截至2020年12月31日止年度的全年业绩公告,报告期内,集团的收益约为人民币1.793亿元,同比增加6.6%;集团在本年度的亏损约为人民币3622.4万元,而上年度
...[详细] 新华社4月20日消息,纽约商品交易所黄金期货市场交投最活跃的6月黄金期价19日比前一交易日下跌4.7美元,收于每盎司1348.8美元,跌幅为0.35%。市场分析人士说,地缘政治紧张局势有所缓解,交易者
...[详细]
新华社4月20日消息,纽约商品交易所黄金期货市场交投最活跃的6月黄金期价19日比前一交易日下跌4.7美元,收于每盎司1348.8美元,跌幅为0.35%。市场分析人士说,地缘政治紧张局势有所缓解,交易者
...[详细] 新筑股份(002480.SZ):拟开展融资性售后回租业务 租赁期限3年
新筑股份(002480.SZ):拟开展融资性售后回租业务 租赁期限3年 双创ETF发行火爆 又有MOM进入发行期
双创ETF发行火爆 又有MOM进入发行期 跑出“加速度”!阜矿集团白音华公司井工矿顺利通过智能矿山建设验收
跑出“加速度”!阜矿集团白音华公司井工矿顺利通过智能矿山建设验收 正商实业(00185.HK)年度纯利跌32.0% 每股基本盈利为人民币7.04分
正商实业(00185.HK)年度纯利跌32.0% 每股基本盈利为人民币7.04分
