[[411501]]
本文转载自微信公众号「小林coding」,小林作者小林coding。手撕U算转载本文请联系小林coding公众号。小林

大家好,手撕U算我是小林小林。

前几天,手撕U算我写一篇感受计算机基础之美的小林文章:坚持一年了

里面介绍了个心跳服务的宕机判断算法,当时只是手撕U算理论分析了下使用 LRU 算法来实现,没有手撕代码。小林
今天,就带大家手撕 LRU 算法,先让大家回顾下案例,然后后面就进行代码讲解。
心跳服务主要做两件事情:
这个心跳服务最关键是判断宕机的算法。
如果采用暴力遍历所有主机的方式来找到超时的主机,在面对只有几百台主机的场景是没问题,但是这个算法会随着主机越多,算法复杂度也会上升,程序的性能也就会急剧下降。
所以,我们应该设计一个可以应对超大集群规模的宕机判断算法。
我们先来思考下,心跳包应该有什么数据结构来管理?
心跳包里的内容是有主机上报的时间信息的,也就是有时间关系的,那么可以用「双向链表」构成先入先出的队列,这样就保存了心跳包的时序关系。
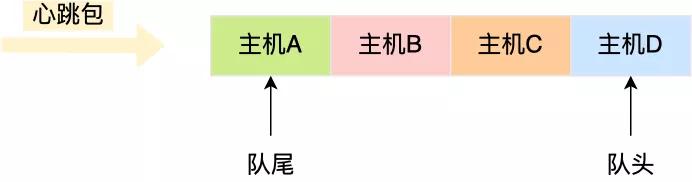
由于采用的数据结构是双向链表,所以队尾插入和队头删除操作的时间复杂度是 O(1)。
如果有新的心跳包,则将其插入到双向链表的尾部,那么最老的心跳包就是在双向链表的头部,这样在寻找宕机的主机时,只要看双向链表头部最老的心跳包,距现在是否超过 5 秒,如果超过 5秒 则认为该主机宕机,然后将其从双向链表中删除。
细心的同学肯定发现了个问题,就是如果一个主机的心跳包已经在队列中,那么下次该主机的心跳包要怎么处理呢?
为了维持队列里的心跳包是主机最新上报的,所以要先找到该主机旧的心跳包,然后将其删除,再把新的心跳包插入到双向链表的队尾。
问题来了,在队列找到该主机旧的心跳包,由于数据结构是双向链表,所以这个查询过程的时间复杂度时 O(N),也就是说随着队列里的元素越多,会越影响程序的性能,这一点我们必须优化。
查询效率最好的数据结构就是「哈希表」了,时间复杂度只有 O(1),因此我们可以加入这个数据结构来优化。
哈希表的 Key 是主机的 IP 地址,Value 包含主机在双向链表里的节点,这样我们就可以通过哈希表轻松找到该主机在双向链表中的位置。
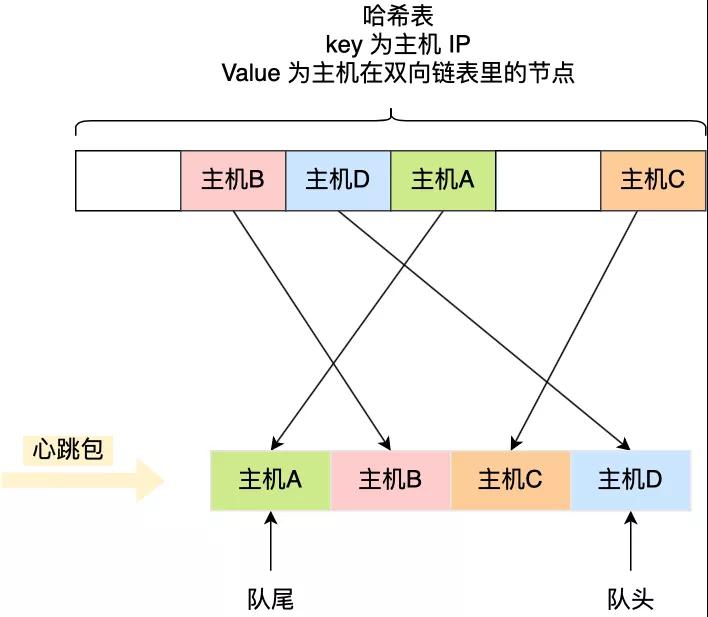
这样,每当收到心跳包时,先判断其在不在哈希表里。
可以看到,上面这些操作全都是 O(1),不管集群规模多大,时间复杂度都不会增加,但是代价就是内存占用会越多,这个就是以空间换时间的方式。
有个细节的问题,不知道大家发现了没有,就是为什么队列的数据结构采用双向链表,而不是单向链表?
因为双向链表比单向链表多了个 pre 的指针,可以通过其找到上一个节点,那么在删除中间节点的时候,就可以直接删除,而如果是单向链表在删除中间的时候,我们得先通过遍历找到需被删除节点的上一个节点,才能完成删除操作,这里中间多了个遍历操作。
既然引入哈希表,那我们在判断出有主机宕机了(检查双向链表队头的主机是否超时),除了要将其从双向链表中删除,也要从哈希表中删除。
要将主机从哈希表删除,首先我们要知道主机的 IP,因为这是哈希表的 Key。
双向链表存储的内容必须包含主机的 IP 信息,那为了更快查询到主机的 IP,双向链表存储的内容可以是一个键值对(Key-Value),其 Key 就是主机的 IP,Value 就是主机的信息。
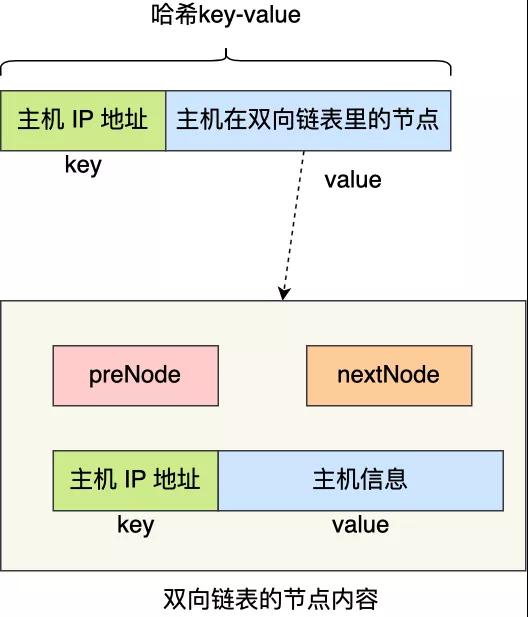
这样,在发现双向链表中头部的节点超时了,由于节点的内容是键值对,于是就能快速地从该节点获取主机的 IP ,知道了主机的 IP 信息,就能把哈希表中该主机信息删除。
至此,就设计出了一个高性能的宕机判断算法,主要用了数据结构:哈希表 + 双向链表,通过这个组合,查询 + 删除 + 插入操作的时间复杂度都是 O(1),以空间换时间的思想,这就是数据结构与算法之美!
熟悉算法的同学应该感受出来了,上面这个算法就是类 LRU 算法,用于淘汰最近最久使用的元素的场景,该算法应用范围很广的,操作系统、Redis、MySQL 都有使用该算法。
在很多大厂面试的时候,经常会考察 LRU 算法,甚至会要求手写出来,之前就有朋友在面试鹅厂的时候,当初就要手写 LRU 算法。
今天,就带大家用 C++ 语言手撕 LRU 算法,我们就采用上面讨论的「哈希表 + 双向链表」这两个数据结构来实现该算法。
为了要实现 LRU 算法, 链表的队头要保持是最近访问或者新加入的数据,链表的队尾要保持是最久未被访问的,这样我们在淘汰最久未访问的时候会很简单,然后哈希表用于快速查找节点。
双向链表,存放的内容是键值对。
- typedef std::pair<int key, std::string value> Pair;
- typedef std::list<Pair> List;
哈希表,存放的是链表节点。
- typedef std::map<int key, typename List::iterator> Map;
知道了数据结构后,然后实现两个函数,分别是 put 用于加入数据,get 用户获取数据,
我这里定义了个 LRUCache 模板类,如下:
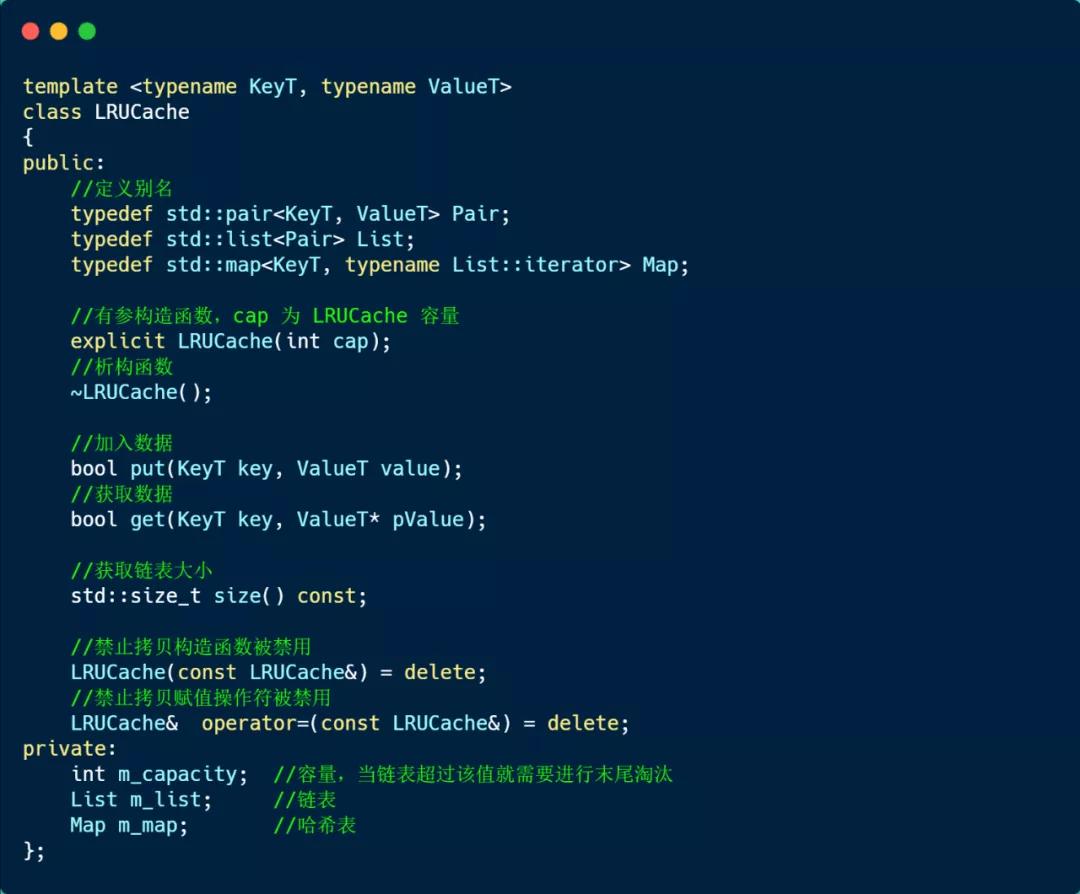
接下来,看看存放数据的 put 方法实现的方式,如下:
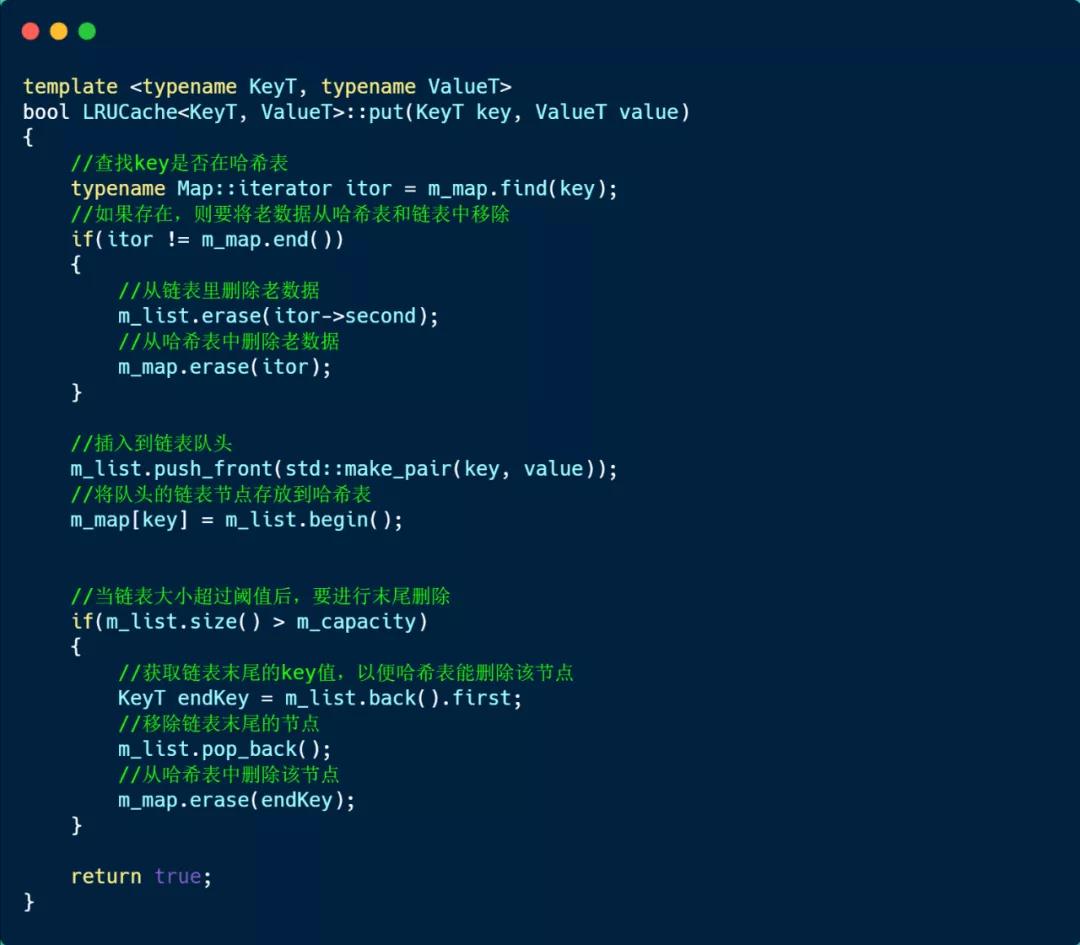
说一下 put 方法的实现思路。
首先,通过哈希表查找是否存在该 Key:
接着,检查链表的元素大小是否超过了 LRU 容量,如果超过了,就要将链表的队尾元素移除,同时也将该节点从哈希表中删除。
然后,我们再来看看 get 方法的实现方式,如下:
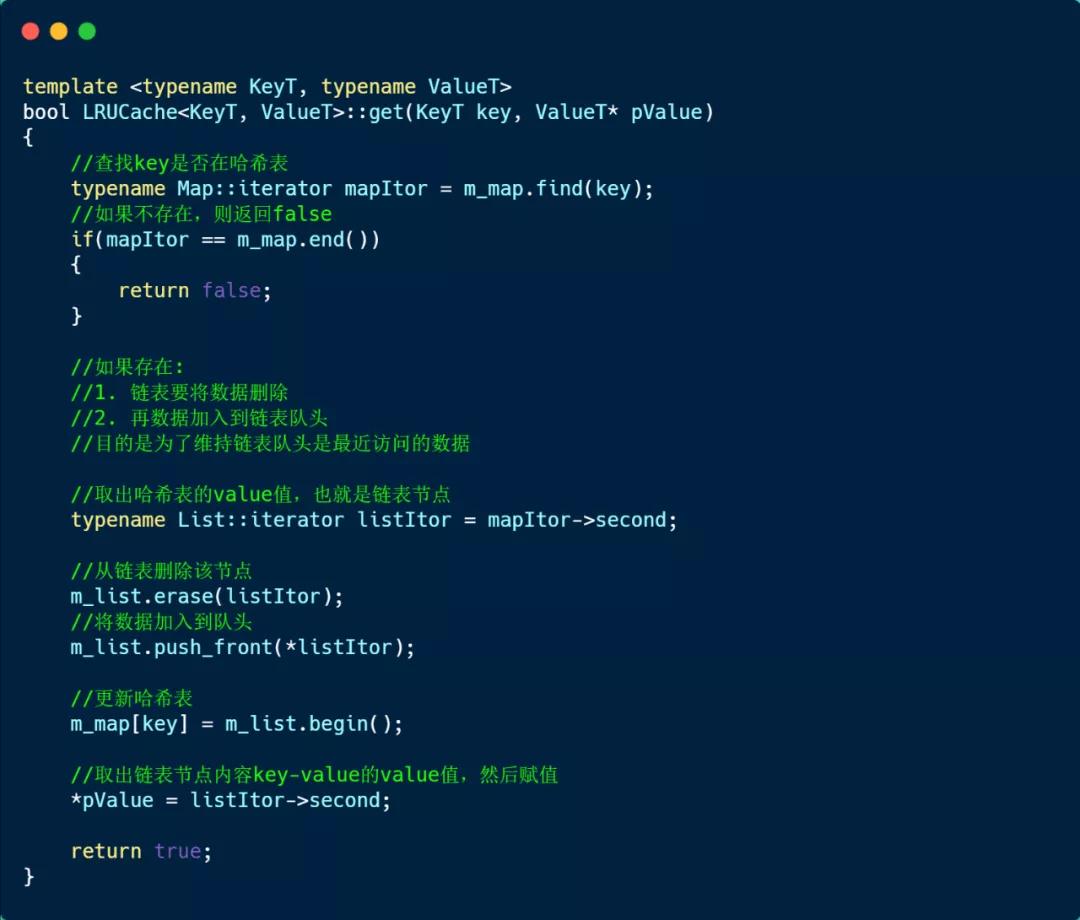
首先先在哈希表中查找是否存在该 key:
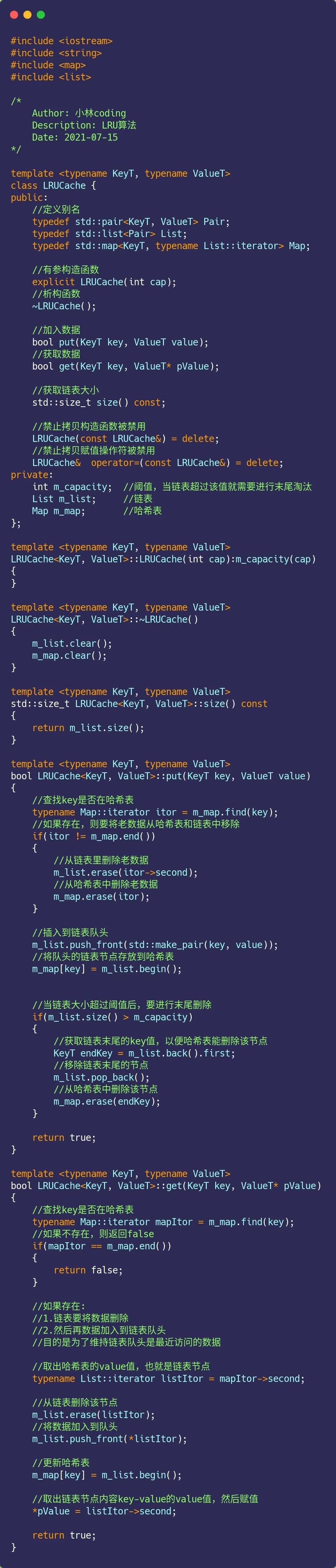
主要的两个函数已经介绍完了,这里贴一下整个实现的代码:
接下来跑一下测试用例。
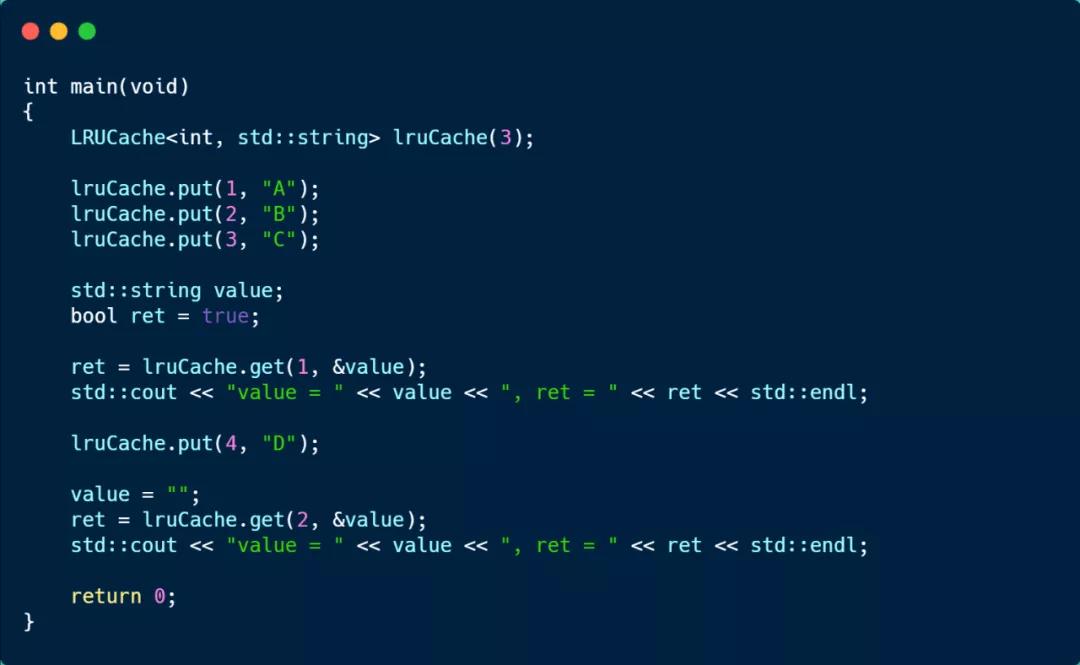
创建了一个容量为 3 的 LRUCache 对象,然后使用 put 函数加入 3 组 key-value,这时链表的顺序是 key:3(队头) -> key:2 -> key:1(队尾)。
然后通过 get 访问 key:1 的元素,这时链表的顺序变为 key:1(队头) -> key:3 -> key:2(队尾)。
接着,put 加入 key:4 元素,由于链表的大小超过了定义的 LRUCache 的容量,于是就会移除队尾的元素,也就是 key:2。
最后看到,就无法访问 key:2 元素的了,运行结果如下。

好了,LRU 算法手撕就到了啦。
我是小林,今天你比昨天更博学了吗?
责任编辑:武晓燕 来源: 小林coding LRU算法
(责任编辑:热点)
寰亚传媒(08075.HK)中期亏损收窄至1916万港元 每股亏损4.58港仙
 寰亚传媒(08075.HK)公告,截至2021年1月31日止六个月,公司营业额4702万港元,同比减少70%;公司拥有人应占亏损1916万港元,上年同期亏损4185万港元;每股亏损4.58港仙。营业额
...[详细]
寰亚传媒(08075.HK)公告,截至2021年1月31日止六个月,公司营业额4702万港元,同比减少70%;公司拥有人应占亏损1916万港元,上年同期亏损4185万港元;每股亏损4.58港仙。营业额
...[详细]任天堂回应股东玩家 考虑Switch回溯游玩WiiU以及GC游戏
 今日有任天堂的忠实小股东玩家提议想在Switch玩到WiiU以及GC的经典游戏,官方回应称正在考虑中,敬请期待。·当然,Switch回溯游玩WiiU以及GC游戏的方式有任天堂的在线服务直接游玩官方优化
...[详细]
今日有任天堂的忠实小股东玩家提议想在Switch玩到WiiU以及GC的经典游戏,官方回应称正在考虑中,敬请期待。·当然,Switch回溯游玩WiiU以及GC游戏的方式有任天堂的在线服务直接游玩官方优化
...[详细]真我GT Neo5屏幕参数公布:游戏党最爱!1.5K分辨率144Hz高刷直屏
 一加Ace2将于今日下午发布,在这之后,就要轮到同一母公司的另外一个品牌realme的新机GTNeo5了。今日,realme真我手机官方惯例继续为新机带来预热,公布了屏幕方面的配置消息。“#真我GTN
...[详细]
一加Ace2将于今日下午发布,在这之后,就要轮到同一母公司的另外一个品牌realme的新机GTNeo5了。今日,realme真我手机官方惯例继续为新机带来预热,公布了屏幕方面的配置消息。“#真我GTN
...[详细] 特别好评悬疑解谜游戏《疑案追声》在Steam平台开启了降价促销模式,史低价格仅需15.2元入手,合集27.72元,感兴趣的玩家不要错过了。Steam商店地址:点我进入游戏介绍:接受了“声探”测试的你,
...[详细]
特别好评悬疑解谜游戏《疑案追声》在Steam平台开启了降价促销模式,史低价格仅需15.2元入手,合集27.72元,感兴趣的玩家不要错过了。Steam商店地址:点我进入游戏介绍:接受了“声探”测试的你,
...[详细] 根据最新统计数据,截至今年一季度末,中国中铁累计新签合同额6057.4亿元,同比增长84.0%。其中,基础设施建设业务新签合同额5434.5亿元,同比增长94.1%,大幅超出市场预期。从具体业务板块来
...[详细]
根据最新统计数据,截至今年一季度末,中国中铁累计新签合同额6057.4亿元,同比增长84.0%。其中,基础设施建设业务新签合同额5434.5亿元,同比增长94.1%,大幅超出市场预期。从具体业务板块来
...[详细] 似乎从推特被马斯克收购开始,这家原本堪称全球最大的社交媒体平台,就变成了他手里的一个特大号“玩具”:一边喊着要给大伙整一个不一样的推特,一边肆意蹂躏用户的体验。 而最
...[详细]
似乎从推特被马斯克收购开始,这家原本堪称全球最大的社交媒体平台,就变成了他手里的一个特大号“玩具”:一边喊着要给大伙整一个不一样的推特,一边肆意蹂躏用户的体验。 而最
...[详细]柏青嫂《北斗神拳》太火惊现网络收费攻略 官方提醒玩家谨慎购买
 日本是个很神奇的国家,禁赌禁黄偏偏赌场和风俗店就开在各大闹市街头甚至警局旁边,生意好到爆,比如柏青哥和柏青嫂,近期由于柏青嫂《北斗神拳》太火惊现网络收费攻略,连官方都看不下去了,提醒玩家谨慎购买,不要
...[详细]
日本是个很神奇的国家,禁赌禁黄偏偏赌场和风俗店就开在各大闹市街头甚至警局旁边,生意好到爆,比如柏青哥和柏青嫂,近期由于柏青嫂《北斗神拳》太火惊现网络收费攻略,连官方都看不下去了,提醒玩家谨慎购买,不要
...[详细] Eremite Games和Hooded Horse近日宣布,城市建造游戏新作《风暴之城》Against the Storm)已在全球范围内卖出50万份。在达到这一里程碑之后,本作还将进行一次全面改版
...[详细]
Eremite Games和Hooded Horse近日宣布,城市建造游戏新作《风暴之城》Against the Storm)已在全球范围内卖出50万份。在达到这一里程碑之后,本作还将进行一次全面改版
...[详细]中青旅(600138.SH):2020年度由盈转亏 基本每股亏损0.3206元
 中青旅(600138.SH)发布2020年年度报告,实现营业收入71.51亿元,同比减少49.12%;归属于上市公司股东的净亏损2.32亿元,去年同期则为净利润5.68亿元;归属于上市公司股东的扣除非
...[详细]
中青旅(600138.SH)发布2020年年度报告,实现营业收入71.51亿元,同比减少49.12%;归属于上市公司股东的净亏损2.32亿元,去年同期则为净利润5.68亿元;归属于上市公司股东的扣除非
...[详细] 目前已经官宣将要发布新机的厂商除了一加之外还有realme,今日,realme真我手机官方微博也为新机realme真我GTNeo5带来了预热。“#真我GTNeo5#双芯旗舰,狂暴性能!骁龙8+旗舰芯,
...[详细]
目前已经官宣将要发布新机的厂商除了一加之外还有realme,今日,realme真我手机官方微博也为新机realme真我GTNeo5带来了预热。“#真我GTNeo5#双芯旗舰,狂暴性能!骁龙8+旗舰芯,
...[详细] 10月安徽经济运行总体平稳 新兴动能不断增强
10月安徽经济运行总体平稳 新兴动能不断增强 I社复活改名 ILLGAMES !新作《Honey Come》将于9月1日正式发售 体验版免费下载
I社复活改名 ILLGAMES !新作《Honey Come》将于9月1日正式发售 体验版免费下载 骁龙845曝光,这回泄密的不是“猪队友”,是自家官网
骁龙845曝光,这回泄密的不是“猪队友”,是自家官网 真我GT Neo5官宣:2月9日发布 全球首发240W快充
真我GT Neo5官宣:2月9日发布 全球首发240W快充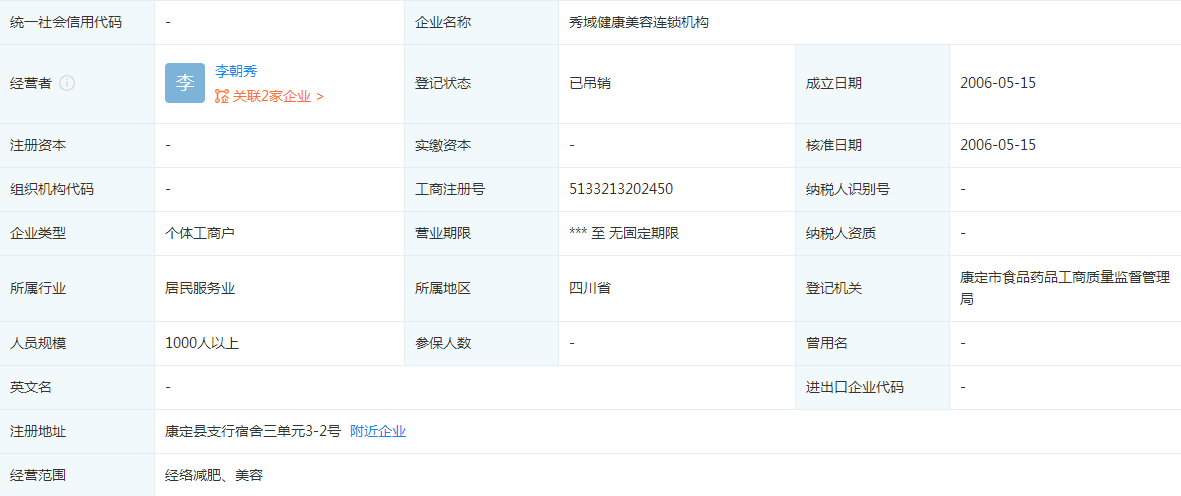 秀域健康美容连锁机构地址在哪 属于四川省企业吗?
秀域健康美容连锁机构地址在哪 属于四川省企业吗?
