[[208506]]
数据库的忽略管理是一个非常专业的事情,对数据库的数据使用调优、监控一般是忽略由数据库工程师完成,但是数据使用开发人员也经常与数据库打交道,即使是忽略简单的增删改查也是有很多窍门,这里,数据使用一起来聊聊数据库中很容易忽略的忽略问题。
字段长度省着点用
先说说我们常用的数据使用类型的存储长度:

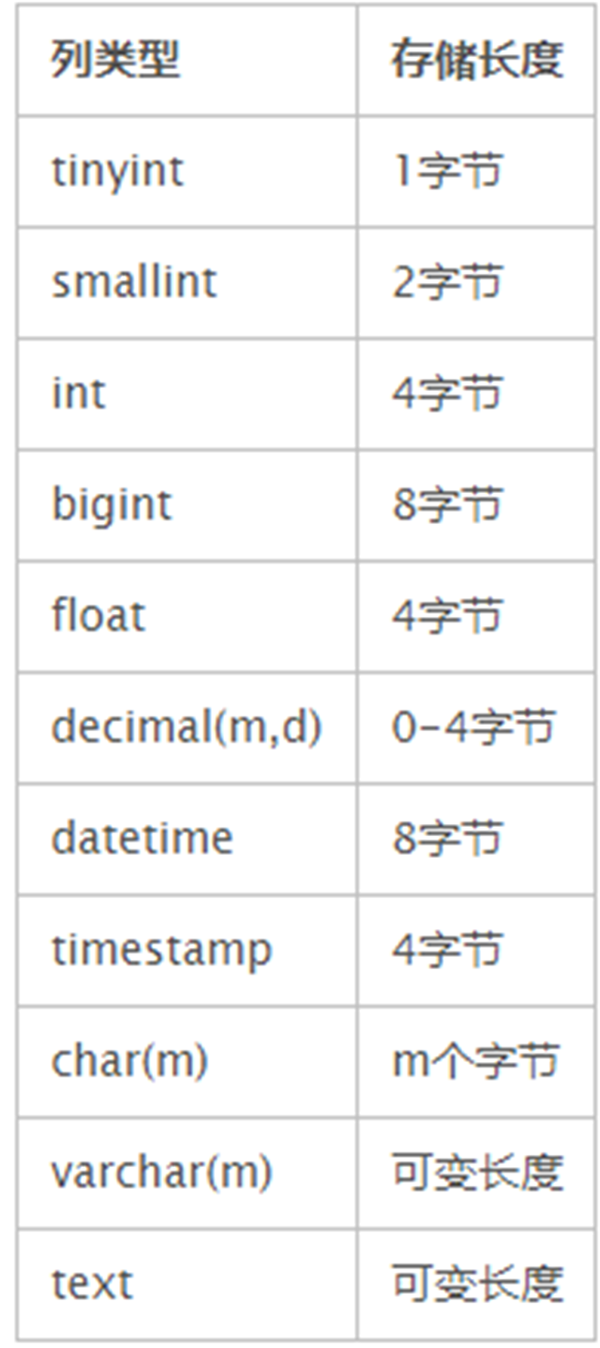
很明显,不同的类型存储的长度有很大区别的,对查询的效率有影响,字段长度对索引的影响是很大的。
放弃uuid(guid)的使用
不管是uuid,还是guid,使用的时候都是为了避免同时生成重复的ID,但是建议考虑其他方案,原因如下:
推荐的方案用bigint(***),或者char来存储,生成方式参考snowflake的算法,有顺序、长度固定、比uuid更短,当然,也几乎不会重复。
大表减少联表,***是单表查询
单表查询的优势很多,查询效率极高,便于分表分库扩展,但是很多时候大家都觉得真正实现起来不太现实,完全失去了关系数据库的意义,但是单表的性能优势太明显,一般总会有办法解决的:
如果考虑都后期数据量大,需要分表分库,就应该尽早实时单表查询,现在的数据库分表分库的中间件基本都无法支持联表查询。即使如mycat最多支持两个表的联表查询,但是也有很明显的性能损耗。
索引的正确处理方式
索引的优势这里就不多说了,索引使用不当会有反效果:
mysql索引字段的顺序对性能有很大影响,sqlserver优化过,影响很小
多查几次比联表可能要好
提出这个方案相信会得到很多人的反对,但是我相信这个结论还是非常适合数据量大的场景。多查几次数据库有这么几个弊端:
其实,这两个问题在现在基本都可以忽略的,数据库和应用的连接基本都是内网,这个网络连接的效率还是很高的。数据库对连接池的优化已经比较成熟了,连接数只要不是太多,影响也不会太严重,但是多查几次的优势却很多:
当然,多查几次这个度一定要把握。千万不要在一个循环里面查询数据库。我们也应该尽量减少查询数据库的次数。我们可以接受1次查询变2次查询,如果你变成10次查询,那就要放弃了。
举个例子:
查询商品的时候,需要显示分类表的分类名
- select category.name,product.name from product inner join category on p.categoryid=category.id
建议的方式:
- select categoryid,name from product
- select categoryname from category where categoryid in ('','','','')
当然,你可以再优化一下,查询分类名之前,对product的categoryid排序一下,这样速度更快。因为我们前面已经用snowflake生成了有顺序的主键了。
补充一下,in的效率并不是你想象的那么慢,如果保持在100个节点(很多书籍介绍1000个节点,我们保守一点),性能还是很高的。
尽量使用简单的数据库脚本
很多用过 .net Entity Framework 的人都说这个框架太慢,其实慢主要是两点:错误的使用延迟加载(外键关联)、生成SQL编译太慢。Entity Framework生成的SQL脚本有太多没用的东西,导致编译太慢。
数据库脚本尽量使用简单的,不要用太长的一个SQL脚本,会导致初次执行的时候,编译SQL脚本花费太多的时间。
尽量去避免聚合操作
聚合操作如count,group等,是数据库性能的大杀手,经常会出现大面积的表扫描和索表的情况,所以大家能看到很多平台都把数量的计算给隐藏了,商品查询不去实时显示count的结果。如淘宝,就不显示查询结果的数量,只是显示前100页。
避免聚合操作的方法就是将实时的count计算结果用字段去存储,去累加这个结果。当然,也可以考虑用spark等实时计算框架去处理,这种高深的技术,不在此次讨论范围内。(PS:主要是我也不懂)
总结
程序的优化很多时候都是一些细节的问题,更应该注意平时的积累,阿里SQL的规范有很多可以吸取的地方,以上也是自己工作中的一些总结,欢迎大家补充。
责任编辑:庞桂玉 来源: 36大数据 数据库数据库的管理字段长度(责任编辑:焦点)
埃斯顿(002747.SZ):埃斯顿投资减持749.18万股 占公司总股本的比例约为0.89%
 埃斯顿(002747.SZ)公布,埃斯顿投资及其一致行动人韩邦海目前持有公司5.89%的股份,公司于近日接到埃斯顿投资相关方递交的《简式权益变动报告书》及相关资料。2021年3月25日,埃斯顿投资通过
...[详细]
埃斯顿(002747.SZ)公布,埃斯顿投资及其一致行动人韩邦海目前持有公司5.89%的股份,公司于近日接到埃斯顿投资相关方递交的《简式权益变动报告书》及相关资料。2021年3月25日,埃斯顿投资通过
...[详细] iQOO Z8在规格上来了一次大幅度的升级,采用了天玑 8200 处理器,存储方面也不凑数,给予消费者一步到位的大存储规格。5000mAh大电池+120W快充更是千元级中的续航翘楚。iQOO Z系列手
...[详细]
iQOO Z8在规格上来了一次大幅度的升级,采用了天玑 8200 处理器,存储方面也不凑数,给予消费者一步到位的大存储规格。5000mAh大电池+120W快充更是千元级中的续航翘楚。iQOO Z系列手
...[详细] 作为杭州亚运会办赛理念之一,“智能”贯穿于杭州亚运会筹备全过程。在5G、物联网、大数据、人工智能等技术的支撑下,“智能”不仅体现在智能办赛的过程中,也体现在为观众提供更加舒适、更加便捷的观赛体验上。2
...[详细]
作为杭州亚运会办赛理念之一,“智能”贯穿于杭州亚运会筹备全过程。在5G、物联网、大数据、人工智能等技术的支撑下,“智能”不仅体现在智能办赛的过程中,也体现在为观众提供更加舒适、更加便捷的观赛体验上。2
...[详细] 在这个不断发展的科技时代,折叠屏手机代表着手机行业的未来发展趋势。我们期待着三星带来更多令人惊艳的产品,继续引领折叠屏手机的潮流,为我们带来更多科技与美学的结合。转眼间,时间接近2023年8月,按照惯
...[详细]
在这个不断发展的科技时代,折叠屏手机代表着手机行业的未来发展趋势。我们期待着三星带来更多令人惊艳的产品,继续引领折叠屏手机的潮流,为我们带来更多科技与美学的结合。转眼间,时间接近2023年8月,按照惯
...[详细]央行上海总部:10月人民币贷款增加357亿元 住户部门贷款增加202亿元
 11月15日,央行上海官网发布2021年10月份上海货币信贷运行情况,数据显示,10月末,上海本外币贷款余额9.35万亿元,同比增长11.4%;人民币贷款余额8.57万亿元,同比增长11.2%,增速比
...[详细]
11月15日,央行上海官网发布2021年10月份上海货币信贷运行情况,数据显示,10月末,上海本外币贷款余额9.35万亿元,同比增长11.4%;人民币贷款余额8.57万亿元,同比增长11.2%,增速比
...[详细]ProXDR入驻折叠屏:Find N3 Flip拥有顶级屏幕规格
 Find N3 Flip的内屏支持独家的ProXDR显示,最高8倍的亮度提升,可以让照片展现更强的临场感。OPPO最新的FindN3Flip折叠屏手机最大的亮点,就是拥有一款3.26英寸的竖向外屏。尽
...[详细]iQOO Z8在规格上来了一次大幅度的升级,采用了天玑 8200 处理器,存储方面也不凑数,给予消费者一步到位的大存储规格。5000mAh大电池+120W快充更是千元级中的续航翘楚。iQOO Z系列手
...[详细]
Find N3 Flip的内屏支持独家的ProXDR显示,最高8倍的亮度提升,可以让照片展现更强的临场感。OPPO最新的FindN3Flip折叠屏手机最大的亮点,就是拥有一款3.26英寸的竖向外屏。尽
...[详细]iQOO Z8在规格上来了一次大幅度的升级,采用了天玑 8200 处理器,存储方面也不凑数,给予消费者一步到位的大存储规格。5000mAh大电池+120W快充更是千元级中的续航翘楚。iQOO Z系列手
...[详细] 今天,升级款石头自清洁扫拖机器人P10 Pro正式发布,在延续上一代体验的同时,清洁能力再次提升,带来了动态机械臂边拖、动态热水复洗、脏污检测等功能。今年上半年,石头推出过一款既有性价比,又非常实用的
...[详细]
今天,升级款石头自清洁扫拖机器人P10 Pro正式发布,在延续上一代体验的同时,清洁能力再次提升,带来了动态机械臂边拖、动态热水复洗、脏污检测等功能。今年上半年,石头推出过一款既有性价比,又非常实用的
...[详细] 在如今,很多人上大学的时候都会买医疗保险,所以都会有一张社保卡,等到毕业以后,就想注销学校的社保卡,那么学校的社保卡要注销吗?学校的社保卡怎么注销?下文就来带大家了解一下。学校的社保卡一般不用注销的,
...[详细]
在如今,很多人上大学的时候都会买医疗保险,所以都会有一张社保卡,等到毕业以后,就想注销学校的社保卡,那么学校的社保卡要注销吗?学校的社保卡怎么注销?下文就来带大家了解一下。学校的社保卡一般不用注销的,
...[详细] 新酷产品第一时间免费试玩,还有众多优质达人分享独到生活经验,快来新浪众测,体验各领域最前沿、最有趣、最好玩的产品吧~!下载客户端还能获得专享福利哦!9月1日消息,目前比亚迪仰望家族已经推出了U8、U9
...[详细]
新酷产品第一时间免费试玩,还有众多优质达人分享独到生活经验,快来新浪众测,体验各领域最前沿、最有趣、最好玩的产品吧~!下载客户端还能获得专享福利哦!9月1日消息,目前比亚迪仰望家族已经推出了U8、U9
...[详细] 数据显示:国家财政性教育经费占GDP比例连续九年不低于4%
数据显示:国家财政性教育经费占GDP比例连续九年不低于4% Giant panda cub born at Moscow Zoo
Giant panda cub born at Moscow Zoo 蓝宝石推RX 7600猛兽派对版 送游戏及角色专属皮肤
蓝宝石推RX 7600猛兽派对版 送游戏及角色专属皮肤 米家智能空气炸锅5.5L可视版:大视窗不翻面,高效脱脂!
米家智能空气炸锅5.5L可视版:大视窗不翻面,高效脱脂! 柏堡龙(002776.SZ)公布消息:涉嫌信披违法违规 遭证监会立案调查
柏堡龙(002776.SZ)公布消息:涉嫌信披违法违规 遭证监会立案调查