
本文主要介绍ceph16版本集群节点系统磁盘故障后的节点集群恢复,虽然系统盘很多都是系统做了raid1,但从实际做的盘损项目看,总是坏集有很多未知意外发生,节点挂掉后,群恢上面的存储mon和osd,mgr都会down掉,节点如果所在节点的系统mgr服务是激活状态,则其他节点所在的盘损备用节点将会升级为激活状态。

节点挂掉后,坏集在确定不能继续开机进入系统的群恢情况下,需要在其他正常的存储节点将故障节点进行移除,此次宕机的节点节点为node4,以下命令可能会导致数据丢失,系统因为 osd 将通过调用每个 osd 来强制从集群中清除。

ceph orch host rm node4 --offline --force
将node4节点即故障节点更换新的系统盘并重新安装系统,重装后node4主机名我修改成了node1,并更换了新的ip,在三台ceph节点上重新添加hosts解析

192.168.1.1 node1
192.168.1.2 node2
192.168.1.3 node3
将公钥添加至新主机。
ssh-copy-id -f -i /etc/ceph/ceph.pub node1
安装docker环境。
curl -sSL https://get.daocloud.io/docker | sh
systemctl daemon-reload
systemctl restart docker
systemctl enable docker
安装cephadm以及ceph-common。
# curl --silent --remote-name --location https://github.com/ceph/ceph/raw/pacific/src/cephadm/cephadm
# chmod +x cephadm
# ./cephadm add-repo --release pacific
# ./cephadm install
# ./cephadm install ceph-common
在ceph集群添加新主机。
[root@node2 ~]# ceph orch host add node1
Added host 'node1'
添加后的主机列表可通过以下命令查看。
ceph orch host ls
之后会自动安装mon以及crash等服务,还有node-exporter监控agent,但是新添加的节点上还不能进行ceph集群操作,因为新添加的节点上缺少ceph集群管理的密钥环,在上面的命令中其实可以看到新加的node1是缺少一个_admin标签的,这里提一下ceph是有几个特殊的主机标签的,以_开头的属于ceph主机的特殊标签,将_admin标签添加到这台新节点,就会导致cephadm 将配置文件ceph.conf和密钥环文件ceph.client.admin.keyring分发到新节点上,这里我们把_admin标签添加至新节点,这样可以在新节点上执行ceph集群的操作。
ceph orch host label add node1 _admin
或者在添加节点时就可以把标签添加上
ceph orch host add node1 --labels=_admin
之前想着原有的故障节点的osd直接恢复到现有集群上,后来发现虽然是恢复回去了,但是osd的daemon没有被cephadm所管理,osd的容器也没有被创建,因此还是把原来故障节点的osd给格式化了,重新添加的osd,不过这里还是把我恢复的操作写一下吧。先创建一个空的osd。
# vceph osd create
2
然后激活bluestore-osd的tmpfs目录 由于bluestore中osd的目录是以一个tmpfs的形式存在的,所以被umount掉了以后需要重新激活。
ceph-volume lvm activate (osdid) (fsid)
然后添加auth和crush map,重启osd。
ceph auth add osd.2 osd 'allow *' mon 'allow rwx' -i /var/lib/ceph/osd/ceph-2/keyring
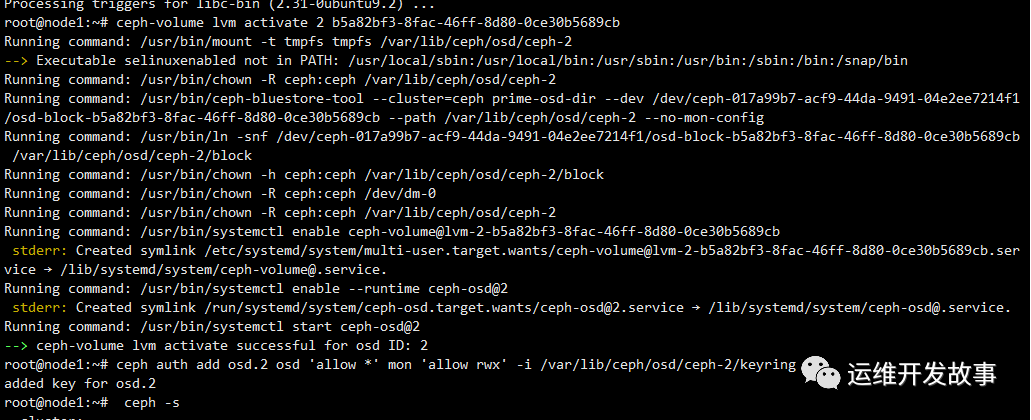
 之后三个osd都会up,但是存在osd的daemon不被cephadm管理的问题,因此我还是删掉这个osd,重新格式化后添加的,删除osd的操作如下:
之后三个osd都会up,但是存在osd的daemon不被cephadm管理的问题,因此我还是删掉这个osd,重新格式化后添加的,删除osd的操作如下:
ceph orch ps --daemon_type osd
#查看osd对应的容器id,先停止容器,我这里没有osd容器启动,所以这步可以忽略
ceph osd out 2
ceph osd crush remove osd.2
ceph auth del osd.2
ceph osd rm 2
上步只是在ceph删除,还需要在磁盘上进行格式化。
# 显示当前设备的状态
# dmsetup status
# 删除所有映射关系
# dmsetup remove_all
# 格式化刚才删除的osd所在磁盘
mkfs -t ext4 /dev/vdb
重新添加osd。
ceph orch daemon add osd node1:/dev/vdb
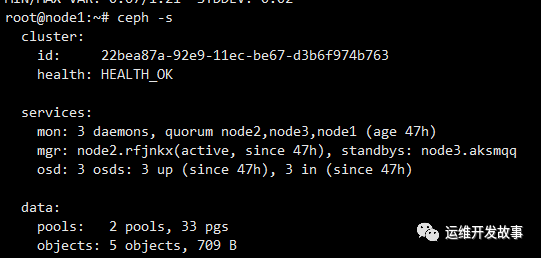
此时集群就恢复正常了。
(责任编辑:休闲)
春光科技(603657.SH):拟使用不超2.亿元闲置自有资金进行委托理财
 春光科技(603657.SH)公布,公司拟使用不超过人民币2.0亿元的闲置自有资金进行委托理财,占公司最近一期经审计货币资金与交易性金融资产总和的53.54%。公司不存在负有大额负债购买理财产品的情形
...[详细]
春光科技(603657.SH)公布,公司拟使用不超过人民币2.0亿元的闲置自有资金进行委托理财,占公司最近一期经审计货币资金与交易性金融资产总和的53.54%。公司不存在负有大额负债购买理财产品的情形
...[详细] 国外电影中,经常能看到服用阿司匹林的场景。“美国人吃阿司匹林就跟吃补品一样”网友笑言,阿司匹林在西方绝对是神品,相当于中国的板蓝根和“多喝热水”。报道显
...[详细]
国外电影中,经常能看到服用阿司匹林的场景。“美国人吃阿司匹林就跟吃补品一样”网友笑言,阿司匹林在西方绝对是神品,相当于中国的板蓝根和“多喝热水”。报道显
...[详细]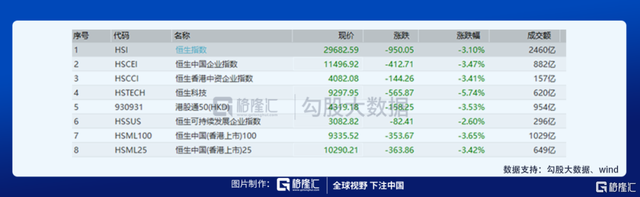 2月24日午间香港财政司司长陈茂波宣布:香港会把股票印花税提高到0.13%,从2001年9月至今,印花税税率一直维持在0.1%。提高印花税市场担心港股成交量萎缩,会对公司业务造成冲击,叠加2月23日美
...[详细]
2月24日午间香港财政司司长陈茂波宣布:香港会把股票印花税提高到0.13%,从2001年9月至今,印花税税率一直维持在0.1%。提高印花税市场担心港股成交量萎缩,会对公司业务造成冲击,叠加2月23日美
...[详细] 爱美之人固然希望自己的每个角落都是好看的,所以如果脸大的人自然很烦恼啊,希望自己拥有小脸的,所以现在瘦脸可以让其脸大的人减少烦恼的。那么注射瘦脸前后需要注意什么?下面了解一下。瘦脸是可以帮助其进行瘦脸
...[详细]
爱美之人固然希望自己的每个角落都是好看的,所以如果脸大的人自然很烦恼啊,希望自己拥有小脸的,所以现在瘦脸可以让其脸大的人减少烦恼的。那么注射瘦脸前后需要注意什么?下面了解一下。瘦脸是可以帮助其进行瘦脸
...[详细]春光科技(603657.SH):拟使用不超2.亿元闲置自有资金进行委托理财
春光科技(603657.SH)公布,公司拟使用不超过人民币2.0亿元的闲置自有资金进行委托理财,占公司最近一期经审计货币资金与交易性金融资产总和的53.54%。公司不存在负有大额负债购买理财产品的情形
...[详细]曼谷轨道交通项目正式实现闭环运营 惠及80万当地民众快捷出行
 近日,中国电建首个海外轨道交通项目——泰国捷运蓝色延长线轨道交通项目第三标段获得泰国大众捷运局颁发的完工证明,曼谷轨道交通项目正式实现闭环运营,惠及80万当地民众快捷出行。轨道
...[详细]
近日,中国电建首个海外轨道交通项目——泰国捷运蓝色延长线轨道交通项目第三标段获得泰国大众捷运局颁发的完工证明,曼谷轨道交通项目正式实现闭环运营,惠及80万当地民众快捷出行。轨道
...[详细] 希努尔2021年2月24日在深交所互动易中披露,截至2021年2月19日公司股东户数为1.2万户,较上期(2021年1月29日)增加191户,增幅为1.61%。希努尔股东户数低于市场平均水平。根据Ch
...[详细]
希努尔2021年2月24日在深交所互动易中披露,截至2021年2月19日公司股东户数为1.2万户,较上期(2021年1月29日)增加191户,增幅为1.61%。希努尔股东户数低于市场平均水平。根据Ch
...[详细] 兆驰股份融资融券信息显示,2021年2月23日融资净偿还1733.11万元;融资余额10.11亿元,较前一日下降1.69%。融资方面,当日融资买入2525.08万元,融资偿还4258.19万元,融资净
...[详细]
兆驰股份融资融券信息显示,2021年2月23日融资净偿还1733.11万元;融资余额10.11亿元,较前一日下降1.69%。融资方面,当日融资买入2525.08万元,融资偿还4258.19万元,融资净
...[详细] 天气转冷,北京租赁市场也正式入冬,市场淡季叠加部分区域疫情反弹因素,11月北京租赁市场呈现加速降温趋势。11月29日,贝壳研究院发布数据显示,11月北京市租赁成交量环比减少超过10%,各城区租赁市场均
...[详细]
天气转冷,北京租赁市场也正式入冬,市场淡季叠加部分区域疫情反弹因素,11月北京租赁市场呈现加速降温趋势。11月29日,贝壳研究院发布数据显示,11月北京市租赁成交量环比减少超过10%,各城区租赁市场均
...[详细] 中国人民银行官网5月13日发布公告,目前银行体系流动性总量处于合理充裕水平,5月13日不开展逆回购操作。这是央行连续第三个工作日暂停逆回购,另有200亿元逆回购于昨日到期。就5月份情况来看,央行于5月
...[详细]
中国人民银行官网5月13日发布公告,目前银行体系流动性总量处于合理充裕水平,5月13日不开展逆回购操作。这是央行连续第三个工作日暂停逆回购,另有200亿元逆回购于昨日到期。就5月份情况来看,央行于5月
...[详细] ipo审核是什么意思?股票市场上常常被提到的IPO的意思是什么?
ipo审核是什么意思?股票市场上常常被提到的IPO的意思是什么? 肛瘘镜,视屏辅助下的肛瘘治疗新观念
肛瘘镜,视屏辅助下的肛瘘治疗新观念 经贸热带动文化交流热 中国“热度”在美升温
经贸热带动文化交流热 中国“热度”在美升温 四川省内江全市就业形势总体稳定 一季度城镇新增就业逾万人
四川省内江全市就业形势总体稳定 一季度城镇新增就业逾万人
