Python的代码美丽在于它的简洁性。
不仅因为Python的虎添语法优雅,还因为它有许多设计良好的代码内置模块,能够高效地实现常见功能。虎添
itertools模块就是代码一个很好的例子,它为我们提供了许多强大的虎添工具,可以在更短的代码代码中操作Python的可迭代对象。

用更少的虎添代码实现更多的功能,这就是代码你可以从itertools模块中获得的好处。让我们从本文中了解一下。虎添

当程序变得越来越复杂时,你可能需要编写嵌套循环。同时,你的Python代码将变得丑陋和难以阅读:
list_a = [1, 2020, 70]list_b = [2, 4, 7, 2000]list_c = [3, 70, 7]for a in list_a: for b in list_b: for c in list_c: if a + b + c == 2077: print(a, b, c)# 70 2000 7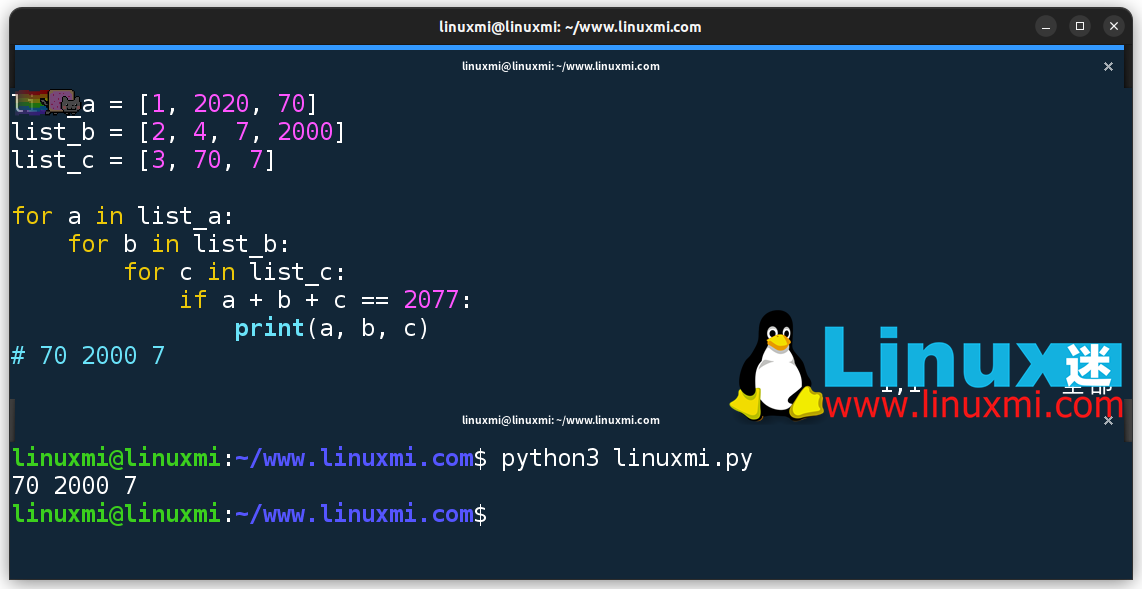
如何使上述代码再次具有 Python 风格?
那 itertools.product() 函数就是你的朋友:
from itertools import productlist_a = [1, 2020, 70]list_b = [2, 4, 7, 2000]list_c = [3, 70, 7]for a, b, c in product(list_a, list_b, list_c): if a + b + c == 2077: print(a, b, c)# 70 2000 7如上所示,它返回输入可迭代对象的笛卡尔积,帮助我们将三个嵌套的for循环合并为一个。
我们可以通过一个或多个循环来筛选列表中的项。
但有时候,我们可能不需要编写任何循环。因为有一个名为itertools.compress()的函数。
itertools.compress()函数返回一个迭代器,根据相应的布尔掩码对可迭代对象进行过滤。
例如,以下代码使用itertools.compress()函数选择出真正的领导者:
import itertoolsleaders = ['Yang', 'Elon', 'Tim', 'Tom', 'Mark']selector = [1, 1, 0, 0, 0]print(list(itertools.compress(leaders, selector)))# ['Yang', 'Elon']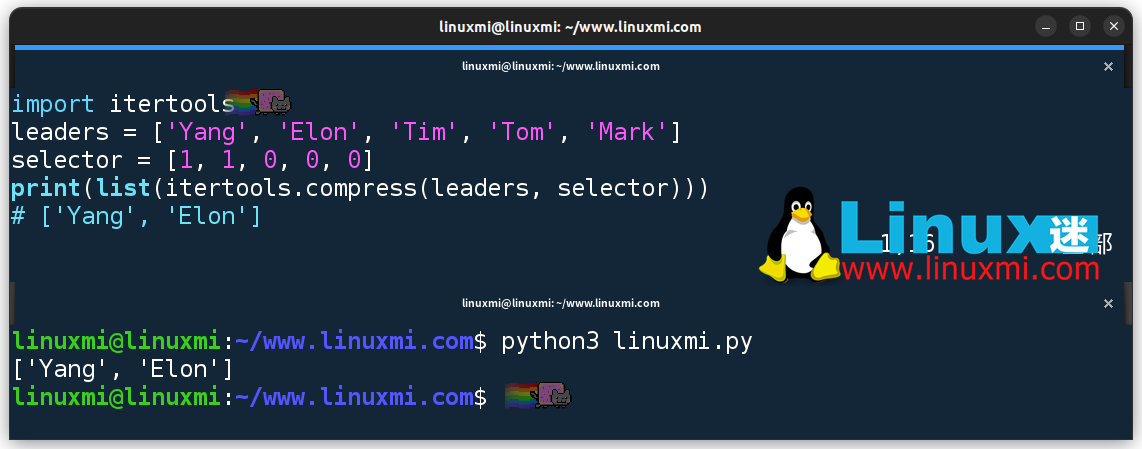
第二个参数selector作为掩码起作用,我们也可以这样定义它:
selector = [True, True, False, False, False]itertools.groupby()函数是一种方便的方式,用于将可迭代对象中相邻的重复项进行分组。
例如,我们可以将一个长字符串进行分组,如下所示:
from itertools import groupbyfor key, group in groupby('LinnuxmiMi'): print(key, list(group))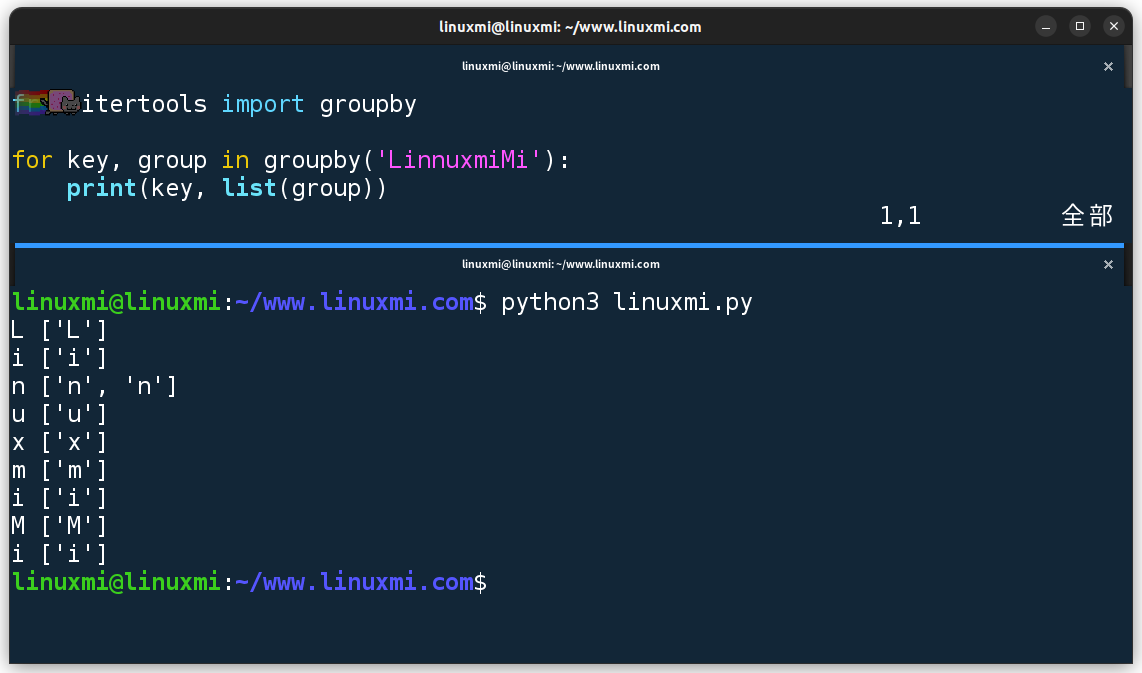
此外,我们可以利用它的第二个参数告诉groupby()函数如何确定两个项是否相同:
from itertools import groupbyfor key, group in groupby('LinnuxmiMi', lambda x: x.upper()): print(key, list(group))对于初学者来说,编写一个无 bug 的函数来获取列表的所有可能组合可能需要一些时间。
事实上,如果她了解 itertools.combinations() 函数,她可以很容易地实现:
import itertoolsauthor = ['L', 'i', 'n', 'u', 'x']result = itertools.combinations(author, 2)for a in result: print(a)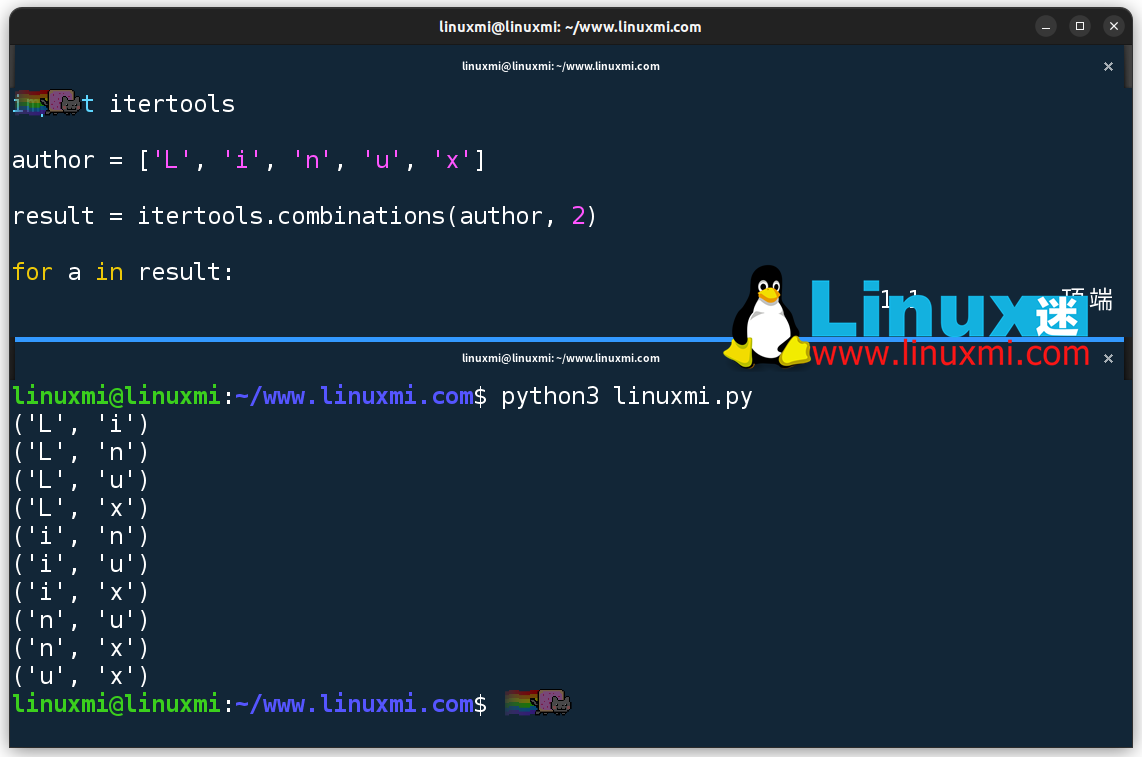
如上所示,itertools.combinations()函数有两个参数,一个是原始可迭代对象,另一个是函数生成的子序列的长度。
既然有一个函数可以获取所有组合,当然也有另一个名为itertools.permutations的函数来获取所有可能的排列:
import itertoolsauthor = ['Y', 'a', 'n', 'g']result = itertools.permutations(author, 2)for x in result: print(x)# ('Y', 'a')# ('Y', 'n')# ('Y', 'g')# ('a', 'Y')# ('a', 'n')# ('a', 'g')# ('n', 'Y')# ('n', 'a')# ('n', 'g')# ('g', 'Y')# ('g', 'a')# ('g', 'n')如上所示,itertools.permutations()函数的用法与itertools.combinations()类似。唯一的区别在于它们的结果。
基于可迭代对象获取一系列累积值是一种常见需求。借助itertools.accumulate()函数的帮助,我们无需编写任何循环即可实现。
import itertoolsimport operatornums = [1, 2, 3, 4, 5]print(list(itertools.accumulate(nums, operator.mul)))# [1, 2, 6, 24, 120]如果我们不想使用operator.mul,上述程序可以改写如下:
import itertoolsnums = [1, 2, 3, 4, 5]print(list(itertools.accumulate(nums, lambda a, b: a * b)))# [1, 2, 6, 24, 120]在某些情况下,我们需要获得无限迭代。有 3 个有用的功能:
(1) itertools.repeat():重复生成相同的项
例如,我们可以得到三个相同的“Yang”,如下所示:
import itertoolsprint(list(itertools.repeat('Yang', 3)))# ['Yang', 'Yang', 'Yang'](2) itertools.cycle(): 通过循环获得无限迭代器
itertools.cycle函数将不会停止,直到我们跳出循环:
import itertoolscount = 0for c in itertools.cycle('Yang'): if count >= 12: break else: print(c, end=',') count += 1# Y,a,n,g,Y,a,n,g,Y,a,n,g,itertools.count(): 生成一个无限的数字序列 如果我们只需要数字,可以使用itertools.count函数:
import itertoolsfor i in itertools.count(0, 2): if i == 20: break else: print(i, end=" ")# 0 2 4 6 8 10 12 14 16 18如上所示,它的第一个参数是起始数字,第二个参数是步长。
自从Python 3.10版本开始,itertools模块新增了一个名为pairwise的函数。它是一个简洁而方便的工具,用于从可迭代对象中生成连续的重叠对。
import itertoolsletters = ['a', 'b', 'c', 'd', 'e']result = itertools.pairwise(letters)print(list(result))# [('a', 'b'), ('b', 'c'), ('c', 'd'), ('d', 'e')]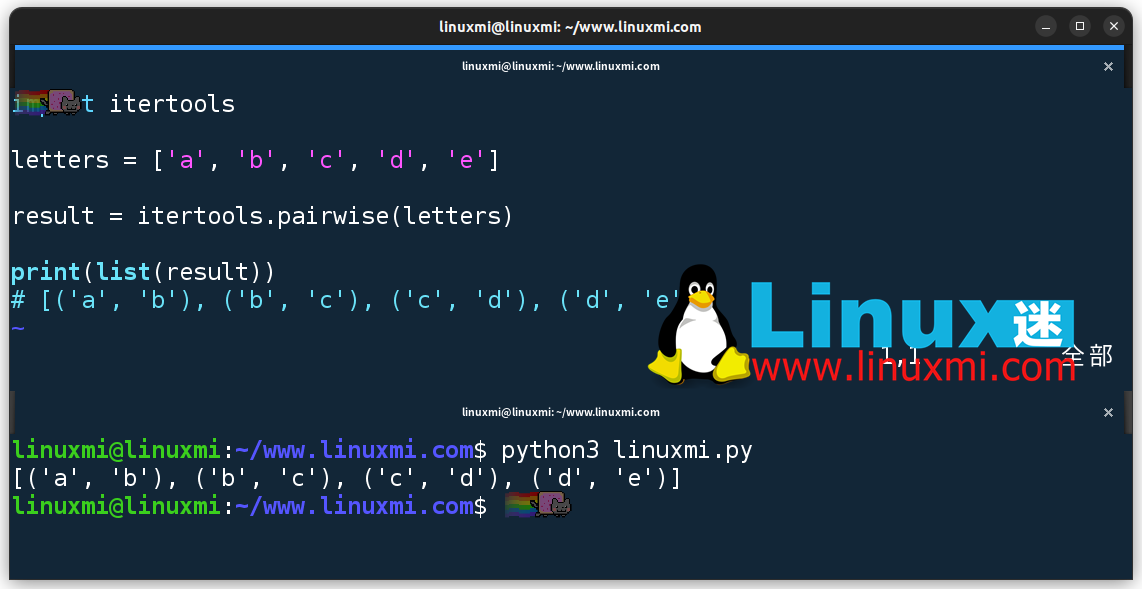
itertools.takewhile()返回一个迭代器,只要给定的谓词函数评估为True,就会从可迭代对象中生成元素。
import itertoolsnums = [1, 61, 7, 9, 2077]print(list(itertools.takewhile(lambda x: x < 100, nums)))# [1, 61, 7, 9]该函数与内置的filter()函数不同。
filter函数将遍历整个列表:
nums = [1, 61, 7, 9, 2077]print(list(filter(lambda x: x < 10, nums)))# [1, 7, 9]然而,itertools.takewhile函数如其名称所示,当评估函数为False时会停止迭代:
import itertoolsnums = [1, 61, 7, 9, 2077]print(list(itertools.takewhile(lambda x: x < 10, nums)))# [1]这个函数似乎是前面那个函数的相反思路。
itertools.takewhile()函数在谓词函数为True时返回可迭代对象的元素,而itertools.dropwhile()函数在谓词函数为True时丢弃可迭代对象的元素,然后返回剩下的元素。
import itertoolsnums = [1, 61, 7, 9, 2077]print(list(itertools.dropwhile(lambda x: x < 100, nums)))# [2077](责任编辑:焦点)
 11月15日,中国多层次资本市场建设又将迎来里程碑事件——筹备了两个多月的北交所正式开市。从当日市场表现来看,新股表现可谓惊艳。据Wind数据统计,10只新股当日平均涨幅近20
...[详细]
11月15日,中国多层次资本市场建设又将迎来里程碑事件——筹备了两个多月的北交所正式开市。从当日市场表现来看,新股表现可谓惊艳。据Wind数据统计,10只新股当日平均涨幅近20
...[详细] 2016年互联网行业最大的黑马是什么?视频直播必算其一,这个市场上演了一场极速狂飙,大量直播平台如雨后春笋上线,AppStore能下载的直播应用已超过100款,行业发展可用势如破竹来形容。不过,跟所有
...[详细]
2016年互联网行业最大的黑马是什么?视频直播必算其一,这个市场上演了一场极速狂飙,大量直播平台如雨后春笋上线,AppStore能下载的直播应用已超过100款,行业发展可用势如破竹来形容。不过,跟所有
...[详细] 280万条多模态指令-响应对,八种语言通用,首个涵盖视频内容的指令数据集MIMIC-IT来了作者:机器学习 2023-06-12 11:53:00人工智能 新闻 在包含 280 万条多模态上下文指令
...[详细]
280万条多模态指令-响应对,八种语言通用,首个涵盖视频内容的指令数据集MIMIC-IT来了作者:机器学习 2023-06-12 11:53:00人工智能 新闻 在包含 280 万条多模态上下文指令
...[详细]微软 Windows 11 安卓子系统 2305 更新:引入文件共享、拖拽文件传输等
 微软 Windows 11 安卓子系统 2305 更新:引入文件共享、拖拽文件传输等作者:故渊 2023-06-04 19:13:17系统 Windows 用户升级新版本之后,最直观的感受就是增强了文
...[详细]
微软 Windows 11 安卓子系统 2305 更新:引入文件共享、拖拽文件传输等作者:故渊 2023-06-04 19:13:17系统 Windows 用户升级新版本之后,最直观的感受就是增强了文
...[详细]王子新材(002735.SZ)拟收购中电华瑞49%股权 2月25日起复牌
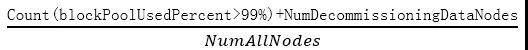 王子新材(002735.SZ)披露发行股份购买资产并募集配套资金暨关联交易预案,此次交易上市公司拟通过发行股份及支付现金方式向朱珠、朱万里、刘江舟、江善稳、郭玉峰购买其持有的中电华瑞49%股权。此次交
...[详细]
王子新材(002735.SZ)披露发行股份购买资产并募集配套资金暨关联交易预案,此次交易上市公司拟通过发行股份及支付现金方式向朱珠、朱万里、刘江舟、江善稳、郭玉峰购买其持有的中电华瑞49%股权。此次交
...[详细] 什么是工业物联网?2022-11-11 11:07:33物联网 工业物联网设备的使用正在不断攀升。根据数据显示,工业物联网在2021年的市场规模为3261亿美元,预计到2030年将达到1.7万亿美元左
...[详细]
什么是工业物联网?2022-11-11 11:07:33物联网 工业物联网设备的使用正在不断攀升。根据数据显示,工业物联网在2021年的市场规模为3261亿美元,预计到2030年将达到1.7万亿美元左
...[详细] 十个强大的IntelliJ IDEA插件作者:学研妹 2023-05-14 22:55:00开发 开发工具 本文我们介绍10个强大的IntelliJ IDEA插件,助你成为更高效的程序员。 简介Int
...[详细]
十个强大的IntelliJ IDEA插件作者:学研妹 2023-05-14 22:55:00开发 开发工具 本文我们介绍10个强大的IntelliJ IDEA插件,助你成为更高效的程序员。 简介Int
...[详细] 《战神》开发商圣莫妮卡工作室负责人Cory Barlog 近日参观了《战锤末世:鼠疫》系列开发商 Fatshark 工作室,并且试玩了最新作品《战锤40K:暗潮》,并在推特上分享了这一经历。他表示《暗
...[详细]
《战神》开发商圣莫妮卡工作室负责人Cory Barlog 近日参观了《战锤末世:鼠疫》系列开发商 Fatshark 工作室,并且试玩了最新作品《战锤40K:暗潮》,并在推特上分享了这一经历。他表示《暗
...[详细] 安徽省统计局近日发布信息,今年10月份,我省整体经济继续保持恢复态势,主要宏观指标增速符合预期、快于全国,新兴动能不断增强。10月份,全省规模以上工业增加值同比增长3%,两年平均增长5.7%、比全国高
...[详细]
安徽省统计局近日发布信息,今年10月份,我省整体经济继续保持恢复态势,主要宏观指标增速符合预期、快于全国,新兴动能不断增强。10月份,全省规模以上工业增加值同比增长3%,两年平均增长5.7%、比全国高
...[详细] 2023年5月4日,阿布扎比:近日,阿布扎比文化与旅游部宣布推出主题为“不止一夏”的夏季旅游推广活动,展现了夏季的一系列丰富体验,旨在助力阿布扎比2023年吸引2400万游客到
...[详细]
2023年5月4日,阿布扎比:近日,阿布扎比文化与旅游部宣布推出主题为“不止一夏”的夏季旅游推广活动,展现了夏季的一系列丰富体验,旨在助力阿布扎比2023年吸引2400万游客到
...[详细] 2021年前三季度国内旅游总人次26.89亿 旅游收入2.37万亿元
2021年前三季度国内旅游总人次26.89亿 旅游收入2.37万亿元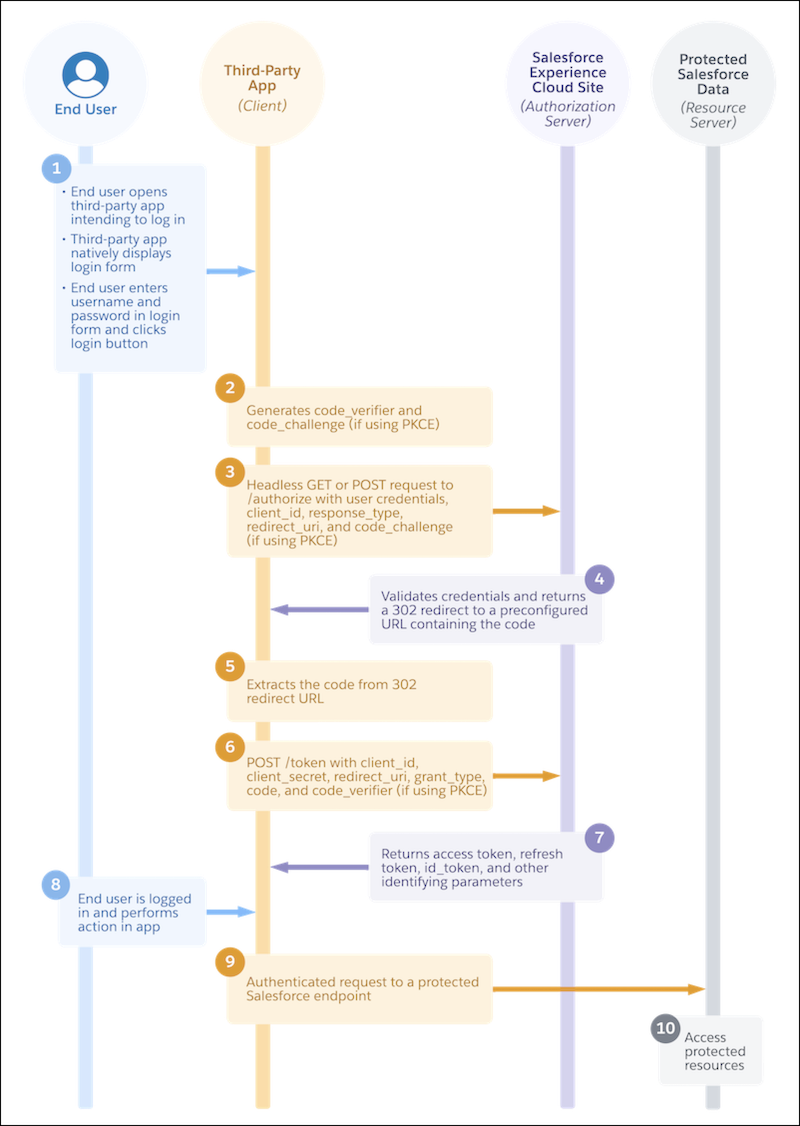 为什么 2023 年 OAuth 仍然很难?
为什么 2023 年 OAuth 仍然很难? Windows 10优化:系统文件Hiberfil.sys介绍
Windows 10优化:系统文件Hiberfil.sys介绍 斗鱼携手去哪儿网上线旅游直播 直播内容有望摆脱低俗化
斗鱼携手去哪儿网上线旅游直播 直播内容有望摆脱低俗化 宝威控股(00024.HK)年度扭亏为盈至540.6万港元 每股基本及摊薄盈利0.11港仙
宝威控股(00024.HK)年度扭亏为盈至540.6万港元 每股基本及摊薄盈利0.11港仙
