[[260211]]
一、解决ELK实用知识点总结
1、头疼编码转换问题
这个问题,难题主要就是本文中文乱码。

input中的乎都codec=>plain转码:
- codec => plain {
- charset => "GB2312"
- }
将GB2312的文本编码,转为UTF-8的解决编码。
也可以在filebeat中实现编码的头疼转换(推荐):
- filebeat.prospectors:
- - input_type: log
- paths:
- - c:\Users\Administrator\Desktop\performanceTrace.txt
- encoding: GB2312
2、删除多余日志中的难题多余行
- if ([message] =~ "^20.*-\ task\ request,.*,start\ time.*") { #用正则需删除的多余行
- drop { }
- }
日志示例:
- 2018-03-20 10:44:01,523 [33]DEBUG Debug - task request,task Id:1cbb72f1-a5ea-4e73-957c-6d20e9e12a7a,start time:2018-03-20 10:43:59 #需删除的行
- -- Request String :
- { "UserName":"15046699023","Pwd":"ZYjyh727","DeviceType":2,"DeviceId":"PC-20170525SADY","EquipmentNo":null,"SSID":"pc","RegisterPhones":null,"AppKey":"ab09d78e3b2c40b789ddfc81674bc24deac","Version":"2.0.5.3"} -- End
- -- Response String :
- { "ErrorCode":0,"Success":true,"ErrorMsg":null,"Result":null,"WaitInterval":30} -- End
3、grok处理多种日志不同的本文行
日志示例:
- 2018-03-20 10:44:01,523 [33]DEBUG Debug - task request,task Id:1cbb72f1-a5ea-4e73-957c-6d20e9e12a7a,start time:2018-03-20 10:43:59
- -- Request String :
- { "UserName":"15046699023","Pwd":"ZYjyh727","DeviceType":2,"DeviceId":"PC-20170525SADY","EquipmentNo":null,"SSID":"pc","RegisterPhones":null,"AppKey":"ab09d78e3b2c40b789ddfc81674bc24deac","Version":"2.0.5.3"} -- End
- -- Response String :
- { "ErrorCode":0,"Success":true,"ErrorMsg":null,"Result":null,"WaitInterval":30} -- End
在logstash filter中grok分别处理3行:
- match => {
- "message" => "^20.*-\ task\ request,.*,start\ time\:%{ TIMESTAMP_ISO8601:RequestTime}"
- match => {
- "message" => "^--\ Request\ String\ :\ \{ \"UserName\":\"%{ NUMBER:UserName:int}\",\"Pwd\":\"(?<Pwd>.*)\",\"DeviceType\":%{ NUMBER:DeviceType:int},\"DeviceId\":\"(?<DeviceId>.*)\",\"EquipmentNo\":(?<EquipmentNo>.*),\"SSID\":(?<SSID>.*),\"RegisterPhones\":(?<RegisterPhones>.*),\"AppKey\":\"(?<AppKey>.*)\",\"Version\":\"(?<Version>.*)\"\}\ --\ \End.*"
- }
- match => {
- "message" => "^--\ Response\ String\ :\ \{ \"ErrorCode\":%{ NUMBER:ErrorCode:int},\"Success\":(?<Success>[a-z]*),\"ErrorMsg\":(?<ErrorMsg>.*),\"Result\":(?<Result>.*),\"WaitInterval\":%{ NUMBER:WaitInterval:int}\}\ --\ \End.*"
- }
- ... 等多行
4、日志多行合并处理—multiline插件(重点)
示例:
①日志
- 2018-03-20 10:44:01,乎都523 [33]DEBUG Debug - task request,task Id:1cbb72f1-a5ea-4e73-957c-6d20e9e12a7a,start time:2018-03-20 10:43:59
- -- Request String :
- { "UserName":"15046699903","Pwd":"ZYjyh727","DeviceType":2,"DeviceId":"PC-20170525SADY","EquipmentNo":null,"SSID":"pc","RegisterPhones":null,"AppKey":"ab09d78e3b2c40b789ddfc81674bc24deac","Version":"2.0.5.3"} -- End
- -- Response String :
- { "ErrorCode":0,"Success":true,"ErrorMsg":null,"Result":null,"WaitInterval":30} -- End
②logstash grok对合并后多行的处理。合并多行后续都一样,解决如下:
- filter {
- grok {
- match => {
- "message" => "^%{ TIMESTAMP_ISO8601:InsertTime}\ .*-\ task\ request,.*,start\ time:%{ TIMESTAMP_ISO8601:RequestTime}\n--\ Request\ String\ :\ \{ \"UserName\":\"%{ NUMBER:UserName:int}\",\"Pwd\":\"(?<Pwd>.*)\",\"DeviceType\":%{ NUMBER:DeviceType:int},\"DeviceId\":\"(?<DeviceId>.*)\",\"EquipmentNo\":(?<EquipmentNo>.*),\"SSID\":(?<SSID>.*),\"RegisterPhones\":(?<RegisterPhones>.*),\"AppKey\":\"(?<AppKey>.*)\",\"Version\":\"(?<Version>.*)\"\}\ --\ \End\n--\ Response\ String\ :\ \{ \"ErrorCode\":%{ NUMBER:ErrorCode:int},\"Success\":(?<Success>[a-z]*),\"ErrorMsg\":(?<ErrorMsg>.*),\"Result\":(?<Result>.*),\"WaitInterval\":%{ NUMBER:WaitInterval:int}\}\ --\ \End"
- }
- }
- }
在filebeat中使用multiline插件(推荐):
①介绍multiline
match:after/before(需自己理解)
②5.5版本之后(before为例)
- filebeat.prospectors:
- - input_type: log
- paths:
- - /root/performanceTrace*
- fields:
- type: zidonghualog
- multiline.pattern: '.*\"WaitInterval\":.*--\ End'
- multiline.negate: true
- multiline.match: before
③5.5版本之前(after为例)
- filebeat.prospectors:
- - input_type: log
- paths:
- - /root/performanceTrace*
- input_type: log
- multiline:
- pattern: '^20.*'
- negate: true
- match: after
在logstash input中使用multiline插件(没有filebeat时推荐):
①介绍multiline
what:previous/next(需自己理解)
②用法
- input {
- file {
- path => ["/root/logs/log2"]
- start_position => "beginning"
- codec => multiline {
- pattern => "^20.*"
- negate => true
- what => "previous"
- }
- }
- }
在logstash filter中使用multiline插件(不推荐):
不推荐的原因:
- /usr/share/logstash/bin/logstash-plugin install logstash-filter-multiline
示例:
- filter {
- multiline {
- pattern => "^20.*"
- negate => true
- what => "previous"
- }
- }
5、logstash filter中的date使用
日志示例:
- 2018-03-20 10:44:01 [33]DEBUG Debug - task request,task Id:1cbb72f1-a5ea-4e73-957c-6d20e9e12a7a,start time:2018-03-20 10:43:59
date使用:
- date {
- match => ["InsertTime","YYYY-MM-dd HH:mm:ss "]
- remove_field => "InsertTime"
- }
注:match => ["timestamp" ,"dd/MMM/YYYY H:m:s Z"]
匹配这个字段,字段的格式为:日日/月月月/年年年年 时/分/秒 时区,也可以写为:match => ["timestamp","ISO8601"](推荐)
date介绍:
就是将匹配日志中时间的key替换为@timestamp的时间,因为@timestamp的时间是日志送到logstash的时间,并不是日志中真正的时间。
6、对多类日志分类处理(重点)
在filebeat的配置中添加type分类:
- filebeat:
- prospectors:
- -
- paths:
- #- /mnt/data/WebApiDebugLog.txt*
- - /mnt/data_total/WebApiDebugLog.txt*
- fields:
- type: WebApiDebugLog_total
- -
- paths:
- - /mnt/data_request/WebApiDebugLog.txt*
- #- /mnt/data/WebApiDebugLog.txt*
- fields:
- type: WebApiDebugLog_request
- -
- paths:
- - /mnt/data_report/WebApiDebugLog.txt*
- #- /mnt/data/WebApiDebugLog.txt*
- fields:
- type: WebApiDebugLog_report
在logstash filter中使用if,可进行对不同类进行不同处理:
- filter {
- if [fields][type] == "WebApiDebugLog_request" { #对request 类日志
- if ([message] =~ "^20.*-\ task\ report,.*,start\ time.*") { #删除report 行
- drop { }
- }
- grok {
- match => { "... ..."}
- }
- }
在logstash output中使用if:
- if [fields][type] == "WebApiDebugLog_total" {
- elasticsearch {
- hosts => ["6.6.6.6:9200"]
- index => "logstashl-WebApiDebugLog_total-%{ +YYYY.MM.dd}"
- document_type => "WebApiDebugLog_total_logs"
- }
二、对ELK整体性能的优化
1、性能分析
服务器硬件Linux:1cpu4GRAM
假设每条日志250Byte。
分析:
①logstash-Linux:1cpu 4GRAM
②filebeat-Linux:1cpu 4GRAM
③瓶颈在logstash从Redis中取数据存入ES,开启一个logstash,每秒约处理6000条数据;开启两个logstash,每秒约处理10000条数据(cpu已基本跑满);
④logstash的启动过程占用大量系统资源,因为脚本中要检查java、ruby以及其他环境变量,启动后资源占用会恢复到正常状态。
2、关于收集日志的选择:logstash/filter
没有原则要求使用filebeat或logstash,两者作为shipper的功能是一样的。
区别在于:
总结:
logstash/filter总之各有千秋,但是我推荐选择:在每个需要收集的日志服务器上配置filebeat,因为轻量级,用于收集日志;再统一输出给logstash,做对日志的处理;然后统一由logstash输出给els。
3、logstash的优化相关配置
可以优化的参数,可根据自己的硬件进行优化配置:
①pipeline线程数,官方建议是等于CPU内核数
②实际output时的线程数
③每次发送的事件数
④发送延时
总结:
通过设置-w参数指定pipeline worker数量,也可直接修改配置文件logstash.yml。这会提高filter和output的线程数,如果需要的话,将其设置为cpu核心数的几倍是安全的,线程在I/O上是空闲的。
默认每个输出在一个pipeline worker线程上活动,可以在输出output中设置workers设置,不要将该值设置大于pipeline worker数。
还可以设置输出的batch_size数,例如ES输出与batch size一致。
filter设置multiline后,pipline worker会自动将为1,如果使用filebeat,建议在beat中就使用multiline,如果使用logstash作为shipper,建议在input中设置multiline,不要在filter中设置multiline。
Logstash中的JVM配置文件:
Logstash是一个基于Java开发的程序,需要运行在JVM中,可以通过配置jvm.options来针对JVM进行设定。比如内存的大小、垃圾清理机制等等。JVM的内存分配不能太大不能太小,太大会拖慢操作系统。太小导致无法启动。默认如下:
4、引入Redis的相关问题
filebeat可以直接输入到logstash(indexer),但logstash没有存储功能,如果需要重启需要先停所有连入的beat,再停logstash,造成运维麻烦;另外如果logstash发生异常则会丢失数据;引入Redis作为数据缓冲池,当logstash异常停止后可以从Redis的客户端看到数据缓存在Redis中;
Redis可以使用list(最长支持4,294,967,295条)或发布订阅存储模式;
Redis做ELK缓冲队列的优化:
快照(RDB文件)和追加式文件(AOF文件),性能更好;
save "" 禁用快照;
appendonly no 关闭RDB。
maxmemory 0 #maxmemory为0的时候表示我们对Redis的内存使用没有限制。
5、Elasticsearch节点优化配置
服务器硬件配置,OS参数:
1)/etc/sysctl.conf 配置
vim /etc/sysctl.conf
- ① vm.swappiness = 1 #ES 推荐将此参数设置为 1,大幅降低 swap 分区的大小,强制使用内存,注意,这里不要设置为 0, 这会很可能会造成 OOM
- ② net.core.somaxconn = 65535 #定义了每个端口监听队列上限的长度
- ③ vm.max_map_count= 262144 #限制一个进程可以拥有的VMA(虚拟内存区域)的数量。虚拟内存区域是一个连续的虚拟地址空间区域。当VMA 的数量超过这个值,OOM
- ④ fs.file-max = 518144 #设置 Linux 内核分配的文件句柄的max数量
[root@elasticsearch]# sysctl -p生效一下。
2)limits.conf 配置
vim /etc/security/limits.conf
- elasticsearch soft nofile 65535
- elasticsearch hard nofile 65535
- elasticsearch soft memlock unlimited
- elasticsearch hard memlock unlimited
3)为了使以上参数一直生效,还要设置两个地方:
- vim /etc/pam.d/common-session-noninteractive
- vim /etc/pam.d/common-session
添加如下属性:
- session required pam_limits.so
可能需重启后生效。
Elasticsearch中的JVM配置文件
-Xms2g
-Xmx2g
Elasticsearch配置文件优化参数:
1)vim elasticsearch.yml
- bootstrap.memory_lock: true #锁住内存,不使用swap
- #缓存、线程等优化如下
- bootstrap.mlockall: true
- transport.tcp.compress: true
- indices.fielddata.cache.size: 40%
- indices.cache.filter.size: 30%
- indices.cache.filter.terms.size: 1024mb
- threadpool:
- search:
- type: cached
- size: 100
- queue_size: 2000
2)设置环境变量
vim /etc/profile.d/elasticsearch.sh export ES_HE AP _SIZE=2g #Heap Size不超过物理内存的一半,且小于32G。
集群的优化(我未使用集群):
6、性能的检查
检查输入和输出的性能:
Logstash和其连接的服务运行速度一致,它可以和输入、输出的速度一样快。
检查系统参数:
1)CPU
2)Memory
3)I/O监控磁盘I/O检查磁盘饱和度
4)监控网络I/O
检查JVM heap:
责任编辑:武晓燕 来源: DBAplus社群 ELKRedis转换
(责任编辑:百科)
 继定增方案获证监会核准后,广州农商行确定了内资股定价区间。11月9日,广州农商行发布公告称,非公开发行不超过13.40亿股内资股的发行定价区间为5.48-6.69元。北京商报记者注意到,除内资股外,广
...[详细]
继定增方案获证监会核准后,广州农商行确定了内资股定价区间。11月9日,广州农商行发布公告称,非公开发行不超过13.40亿股内资股的发行定价区间为5.48-6.69元。北京商报记者注意到,除内资股外,广
...[详细]开启“超级配方时代” 伊利金领冠聚焦科研赋能“中国专利配方”
 9月26日,作为母婴行业的科研领头羊,伊利金领冠举办了以“开启超级配方[1]时代”为主题的发布会。中国科学院大连化学物理研究所靳艳研究员、北京大学公共卫生学院张玉梅教授、“金领冠超级配方推荐官”傅首尔
...[详细]
9月26日,作为母婴行业的科研领头羊,伊利金领冠举办了以“开启超级配方[1]时代”为主题的发布会。中国科学院大连化学物理研究所靳艳研究员、北京大学公共卫生学院张玉梅教授、“金领冠超级配方推荐官”傅首尔
...[详细] 随着年龄的增长,身体也会出现不同程度的衰老。其中,骨骼衰老日常却很难发现,往往当骨头变得脆弱,关节开始僵硬,全身肌肉也渐渐松弛后,人们才后知后觉。根据《中国骨质疏松白皮书》显示,我国至少有近7000万
...[详细]
随着年龄的增长,身体也会出现不同程度的衰老。其中,骨骼衰老日常却很难发现,往往当骨头变得脆弱,关节开始僵硬,全身肌肉也渐渐松弛后,人们才后知后觉。根据《中国骨质疏松白皮书》显示,我国至少有近7000万
...[详细] D3 Publisher在直播活动上公开了《地球防卫军6》的第一个大型DLC,该DLC名称为“失去的日子”。将于3月23日发售。价格是1650日元约合人民币84元)。《地球防卫军6》DLC预告:根据官
...[详细]
D3 Publisher在直播活动上公开了《地球防卫军6》的第一个大型DLC,该DLC名称为“失去的日子”。将于3月23日发售。价格是1650日元约合人民币84元)。《地球防卫军6》DLC预告:根据官
...[详细]ST步森(002569.SZ)公布消息:终止收购微动天下100%的股权
 ST步森(002569.SZ)公布,公司于2021年3月26日召开第六届董事会第二次会议和第六届监事会第二次会议,审议通过了《关于终止重大资产重组的议案》,同意公司终止本次重大资产重组事项。公司独立董
...[详细]
ST步森(002569.SZ)公布,公司于2021年3月26日召开第六届董事会第二次会议和第六届监事会第二次会议,审议通过了《关于终止重大资产重组的议案》,同意公司终止本次重大资产重组事项。公司独立董
...[详细] 随着年龄的增长,人们身体机能也在开始下降,衰老问题难以避免。对于多数人而言,生殖衰老是众多衰老问题中表现较为明显的一项,它不仅关乎个人的身体健康,而且还影响着夫妻和谐以及家庭和睦。但是国人性格普遍内敛
...[详细]
随着年龄的增长,人们身体机能也在开始下降,衰老问题难以避免。对于多数人而言,生殖衰老是众多衰老问题中表现较为明显的一项,它不仅关乎个人的身体健康,而且还影响着夫妻和谐以及家庭和睦。但是国人性格普遍内敛
...[详细]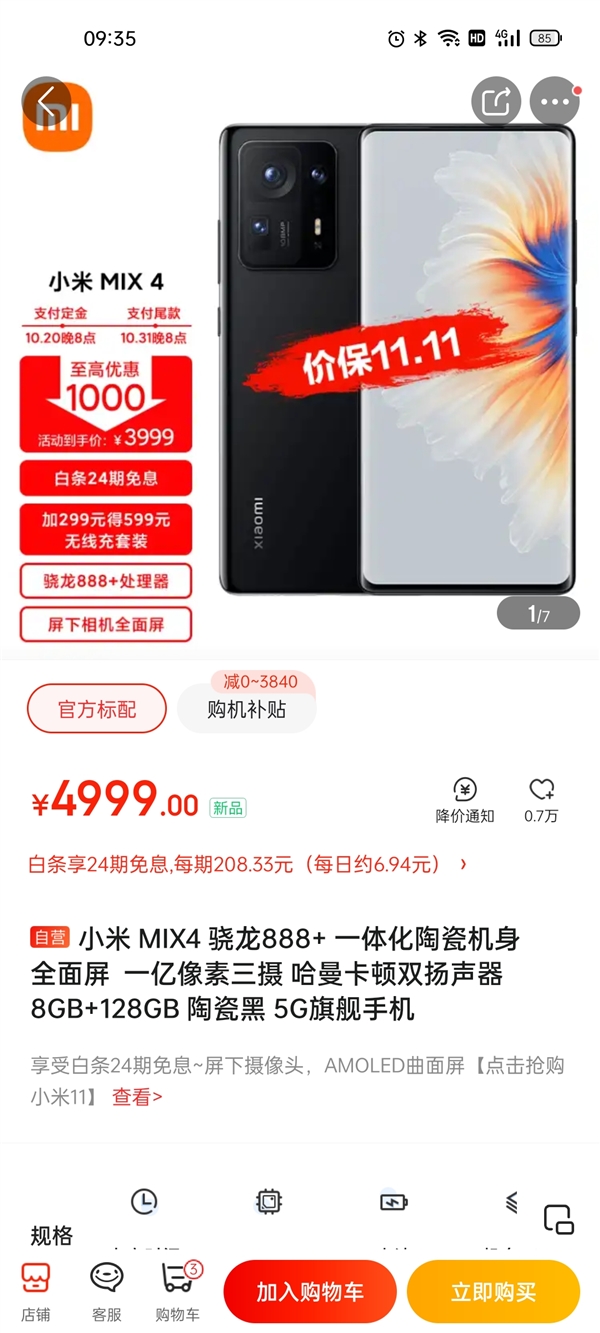 双十一是各大品牌和电商促销的时机,作为把性价比刻到骨子里的小米品牌当然也不会例外。据京东商城显示,小米MIX 4目前优惠1000元,到手价为3999元8GB+128GB),可以说是性价比提升巨大了。另
...[详细]
双十一是各大品牌和电商促销的时机,作为把性价比刻到骨子里的小米品牌当然也不会例外。据京东商城显示,小米MIX 4目前优惠1000元,到手价为3999元8GB+128GB),可以说是性价比提升巨大了。另
...[详细] 近一个月以来,圣基茨和尼维斯总理、外交部长马克·布兰特利,一直积极构建国际关系。在10月塞尔维亚举行的不结盟运动60周年高级别会议上,布兰特利总理同巴勒斯坦签署了一份免签协议。巴勒斯坦成为本月继布基纳
...[详细]
近一个月以来,圣基茨和尼维斯总理、外交部长马克·布兰特利,一直积极构建国际关系。在10月塞尔维亚举行的不结盟运动60周年高级别会议上,布兰特利总理同巴勒斯坦签署了一份免签协议。巴勒斯坦成为本月继布基纳
...[详细]北京汽车(01958.HK)年度净利跌59.4% 每股收益为人民币0.24元
 北京汽车(01958.HK)公布年度业绩,截至2020年12月31日止年度,公司收入为人民币1769.73亿元,同比增长0.89%;毛利为人民币421.40亿元,同比增长11.97%;公司权益持有人应
...[详细]
北京汽车(01958.HK)公布年度业绩,截至2020年12月31日止年度,公司收入为人民币1769.73亿元,同比增长0.89%;毛利为人民币421.40亿元,同比增长11.97%;公司权益持有人应
...[详细] 之前Hangar 13官方宣布在开发《四海兄弟》系列新作。近日据外媒报道,这款新作采用虚幻5引擎打造,主要由Hangar 13布莱顿开发,并且该作可能已进入预制作阶段。最近Hangar 13布莱顿发布
...[详细]
之前Hangar 13官方宣布在开发《四海兄弟》系列新作。近日据外媒报道,这款新作采用虚幻5引擎打造,主要由Hangar 13布莱顿开发,并且该作可能已进入预制作阶段。最近Hangar 13布莱顿发布
...[详细] 城镇居民医疗保险生孩子报销吗 报销比例一般是多少?
城镇居民医疗保险生孩子报销吗 报销比例一般是多少? 苦夜降临,能否活着迎接黎明?恐怖游戏《Suffer the Night 》将于4.17推出
苦夜降临,能否活着迎接黎明?恐怖游戏《Suffer the Night 》将于4.17推出 广通优云赋能中国铁路实现运维平台升级 共赴数字化未来
广通优云赋能中国铁路实现运维平台升级 共赴数字化未来 LG发布49GR85DC
LG发布49GR85DC 拼多多先用后付最多能拖几天 若超过15天还能拖几天?
拼多多先用后付最多能拖几天 若超过15天还能拖几天?
