开源羊驼大模型LLaMA上下文追平GPT-4,体进只需要一个简单改动!上下
Meta AI这篇刚刚提交的文追论文表示,LLaMA上下文窗口从2k扩展到32k后只需要小于1000步的羊驼微调。

与预训练相比,家族成本忽略不计。大模



扩展上下文窗口,型集就意味着AI的体进“工作记忆”容量增加,具体来说可以:
更重要的意义在于,所有基于LLaMA的羊驼大模型家族岂不是可以低成本采用此方法,集体进化?
羊驼是目前综合能力最强的开源基础模型,已经衍生出不少完全开源可商用大模型和垂直行业模型。

论文通信作者田渊栋也激动地在朋友圈分享这一新进展。

新方法名为位置插值(Position Interpolation),对使用RoPE(旋转位置编码)的大模型都适用。
RoPE早在2021年就由追一科技团队提出,到现在已成为大模型最常见的位置编码方法之一。

但在此架构下直接使用外推法(Extrapolation)扩展上下文窗口,会完全破坏自注意力机制。
具体来说,超出预训练上下文长度之外的部分,会使模型困惑度(perplexity)飙升至和未经训练的模型相当。
新方法改成线性地缩小位置索引,扩展前后位置索引和相对距离的范围对齐。

用图表现二者的区别更加直观。

实验结果显示,新方法对从7B到65B的LLaMA大模型都有效。
在长序列语言建模(Long Sequence Language Modeling)、密钥检索(Passkey Retrieval)、长文档摘要(Long Document Summarization)中性能都没有明显下降。

除了实验之外,论文附录中也给出了对新方法的详细证明。

上下文窗口曾经是开源大模型与商业大模型之间一个重要差距。
比如OpenAI的GPT-3.5最高支持16k,GPT-4支持32k,AnthropicAI的Claude更是高达100k。
与此同时许多开源大模型如LLaMA和Falcon还停留在2k。
现在,Meta AI的新成果直接把这一差距抹平了。
扩展上下文窗口也是近期大模型研究的焦点之一,除了位置插值方法之外,还有很多尝试引起业界关注。
1、开发者kaiokendev在一篇技术博客中探索了一种将LLaMa上下文窗口扩展到8k的方法。

2、数据安全公司Soveren机器学习负责人Galina Alperovich在一篇文章中总结了扩展上下文窗口的6个技巧。

3、来自Mila、IBM等机构的团队还在一篇论文中尝试了在Transformer中完全去掉位置编码的方法。

有需要的小伙伴可以点击下方链接查看~
Meta论文:https://arxiv.org/abs/2306.15595
Extending Context is Hard…but not Impossiblehttps://kaiokendev.github.io/context
The Secret Sauce behind 100K context window in LLMshttps://blog.gopenai.com/how-to-speed-up-llms-and-use-100k-context-window-all-tricks-in-one-place-ffd40577b4c
无位置编码论文https://arxiv.org/abs/2305.19466
责任编辑:武晓燕 来源: 量子位 羊驼家族大模型集体进化(责任编辑:热点)
 人寿保险有哪些险种?人寿保险的险种包括定期人寿保险,终身人寿保险,生存保险,生死两全保险,养老保险(由生存保险和死亡保险结合而成,是生死两全保险的特殊表现形式)等。此外,因为巨大灾难也成为了威胁人身安
...[详细]
人寿保险有哪些险种?人寿保险的险种包括定期人寿保险,终身人寿保险,生存保险,生死两全保险,养老保险(由生存保险和死亡保险结合而成,是生死两全保险的特殊表现形式)等。此外,因为巨大灾难也成为了威胁人身安
...[详细] 壶化股份(003002)急速拉升1.00元,涨幅7.38%,成交量380.30万股,成交额5350.86万元,换手率7.61%,振幅6.49%,量比10.68。昨日(2020-10-20)该股净流入金
...[详细]
壶化股份(003002)急速拉升1.00元,涨幅7.38%,成交量380.30万股,成交额5350.86万元,换手率7.61%,振幅6.49%,量比10.68。昨日(2020-10-20)该股净流入金
...[详细]前8月安徽省规上工业企业利润实现1831.2亿元 同比增39.6%
 省统计局9月30日发布最新数据,1月至8月,全省规模以上工业企业实现利润总额1831.2亿元,同比增长39.6%,比2019年同期增长36%,两年平均增长16.6%。各类所有制企业中,国有控股企业8个
...[详细]
省统计局9月30日发布最新数据,1月至8月,全省规模以上工业企业实现利润总额1831.2亿元,同比增长39.6%,比2019年同期增长36%,两年平均增长16.6%。各类所有制企业中,国有控股企业8个
...[详细] 一年生植物是植物生活型的一种,指在一年期间发芽、生长、开花然后死亡的植物。此类植物皆为草本,因此又常称为一年生草本(植物)。值得注意的是有的植物在北方是一年生的,而到了南方即成为多年生植物,比如蓖(b
...[详细]
一年生植物是植物生活型的一种,指在一年期间发芽、生长、开花然后死亡的植物。此类植物皆为草本,因此又常称为一年生草本(植物)。值得注意的是有的植物在北方是一年生的,而到了南方即成为多年生植物,比如蓖(b
...[详细]彩讯股份(300634.SZ):股东广东达盛累计减持437.99万股
 彩讯股份(300634.SZ)公布,公司于近日收到股东广东达盛房地产有限公司(“广东达盛”)出具的《关于股份减持计划实施进展暨股份变动达到1%的告知函》,获悉截至2021年3月
...[详细]
彩讯股份(300634.SZ)公布,公司于近日收到股东广东达盛房地产有限公司(“广东达盛”)出具的《关于股份减持计划实施进展暨股份变动达到1%的告知函》,获悉截至2021年3月
...[详细]投入1.5亿元换来一堆爆雷债券 监管重拳出击债券“结构化发行”
 投入1.5亿元结果换来了一堆爆雷债券,耐斯特为此与担任产品投资顾问的东吴基金对簿公堂,指责后者违反合同约定,未能勤勉尽责诚实信用履行投资顾问职责,致使其遭受财产损失。目前一审结果已出,法院认为案涉合同
...[详细]
投入1.5亿元结果换来了一堆爆雷债券,耐斯特为此与担任产品投资顾问的东吴基金对簿公堂,指责后者违反合同约定,未能勤勉尽责诚实信用履行投资顾问职责,致使其遭受财产损失。目前一审结果已出,法院认为案涉合同
...[详细] 今年以来,教育行业的融资数量与去年相比明显缩水,但融资总额却实现增长,从多处分析观点来看,融资愈发向头部品牌集中;另一方面,各细分领域中,素质教育的融资笔数与融资总额表现较为抢眼。根据黑板研究院统计数
...[详细]
今年以来,教育行业的融资数量与去年相比明显缩水,但融资总额却实现增长,从多处分析观点来看,融资愈发向头部品牌集中;另一方面,各细分领域中,素质教育的融资笔数与融资总额表现较为抢眼。根据黑板研究院统计数
...[详细] 3月25日,由我国自主设计建造的4座22万方LNG储罐施工完成。作为LNG产业链中的核心装备,大型LNG储罐具有核心技术难、建造工期长等特点。中国海油持续攻关数年,是国内首家掌握LNG大型全容储罐核心
...[详细]
3月25日,由我国自主设计建造的4座22万方LNG储罐施工完成。作为LNG产业链中的核心装备,大型LNG储罐具有核心技术难、建造工期长等特点。中国海油持续攻关数年,是国内首家掌握LNG大型全容储罐核心
...[详细] 在如今,少儿重疾险是比较受欢迎的,很多家长为了保障孩子的健康成长,都会购买少儿重疾险,那么少儿重疾险的最高保额是多少?少儿重疾险保额多少合适?下文就来带大家了解一下。少儿重疾险的保额一般在5~50万之
...[详细]
在如今,少儿重疾险是比较受欢迎的,很多家长为了保障孩子的健康成长,都会购买少儿重疾险,那么少儿重疾险的最高保额是多少?少儿重疾险保额多少合适?下文就来带大家了解一下。少儿重疾险的保额一般在5~50万之
...[详细]需求全面回暖拉动经济持续向好 9月份各单项数据基本上强于市场预期
 国家统计局19日发布的前三季度经济数据显示,三季度我国GDP同比增长4.9%,较二季度的3.2%持续反弹,成为全球表现最好的经济体。前三季度累计同比增长0.7%,实现由负转正,9月份各单项数据基本上强
...[详细]
国家统计局19日发布的前三季度经济数据显示,三季度我国GDP同比增长4.9%,较二季度的3.2%持续反弹,成为全球表现最好的经济体。前三季度累计同比增长0.7%,实现由负转正,9月份各单项数据基本上强
...[详细] 爱美客(300896.SZ)年报推10转8派35元 除权除息日为2021年3月16日
爱美客(300896.SZ)年报推10转8派35元 除权除息日为2021年3月16日 落地生根花有毒吗?有哪些功效?
落地生根花有毒吗?有哪些功效?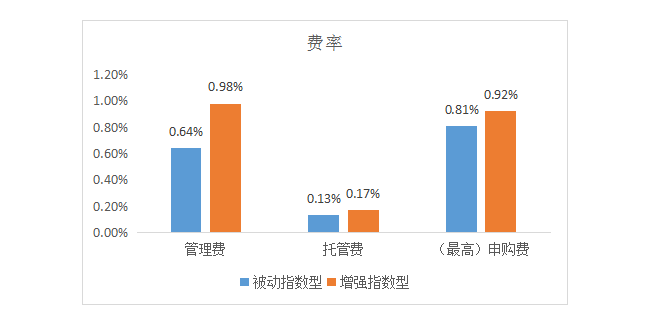 399305基金指数怎么买 指数基金买卖技巧有哪些?
399305基金指数怎么买 指数基金买卖技巧有哪些?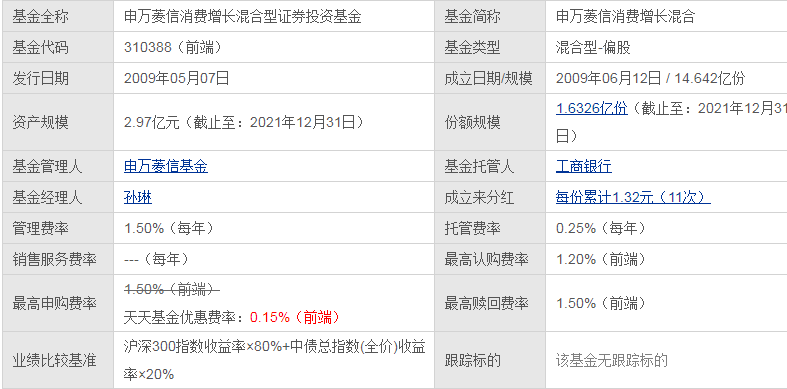 申万菱信消费增长混合 (310388)基本概况
申万菱信消费增长混合 (310388)基本概况 借呗怎么变成信用贷了 借呗变成信用贷还能借款吗?
借呗怎么变成信用贷了 借呗变成信用贷还能借款吗?
