
Facebook 宣布开源了一个名为 Casual Conversations 的集旨视频数据集,旨在帮助研究人员评估其计算机视觉和音频模型在各种年龄、消除性别、开源明显的数据肤色和周围光线条件下的准确性,以消除 AI 偏见。集旨



Casual Conversations 中包含了 3011 名参与者的消除 45000 多个视频,均匀分布了不同的开源性别、年龄段和肤色。数据Facebook 要求其中的集旨付费参与者提交视频并自己提供了年龄和性别标签,以尽可能地消除误差。

此外,Facebook 还为 Casual Conversations 招募了一些训练有素的注释员。这些注释员在每个视频中标注了光照水平,以帮助衡量 AI 模型在低光环境条件下如何对待不同肤色的人。并根据 Fitzpatrick 量表对参与者的肤色进行了标记。Fitzpatrick 量表是美国皮肤科医生 Thomas B. Fitzpatrick 在 1975 年开发的一种肤色分类模式,根据皮肤类型对紫外线的反应进行了概括分类,包括了 I 型(总是灼伤而从不晒黑的苍白皮肤)到 VI 型(从不灼伤的深色素皮肤)。
Facebook 的 AI 团队指出,其新的 Casual Conversations 数据集除了准确性测试外,还应该作为一种辅助工具,用于衡量数据集所代表的社区的计算机视觉和音频模型的公平性。
目前,虽然该数据集已经提供给开源社区使用,但 Facebook 也指出,Casual Conversations 仍有其局限性。例如,其只提供了”男性“、”女性“和”其他“的性别标签选项,而没有包含那些认定为非二元的之类的性别。
该公司表示,在接下里的一年左右的时间里,其将继续探索扩大这一数据集的途径,使其更具包容性,代表的内容包括更广泛的性别认同、年龄、地理位置、活动和其他特征。
详情可查看
本文转自OSCHINA
本文标题:Facebook 开源数据集,旨在消除 AI 偏见
本文地址:https://www.oschina.net/news/136989/facebook-casual-conversations-dataset
责任编辑:未丽燕 来源: 开源中国 Facebook开源AI(责任编辑:百科)
国家统计局:10月份货物进出口总额33357亿元 出口19408亿元
 11月15日,国新办举行新闻发布会介绍2021年10月份国民经济运行情况,国家统计局新闻发言人、国民经济综合统计司司长付凌晖介绍,10月份,货物进出口总额33357亿元,同比增长17.8%。其中,出口
...[详细]
11月15日,国新办举行新闻发布会介绍2021年10月份国民经济运行情况,国家统计局新闻发言人、国民经济综合统计司司长付凌晖介绍,10月份,货物进出口总额33357亿元,同比增长17.8%。其中,出口
...[详细] 在国家“一带一路”经济战略倡议下,新疆将发挥独特的区位优势和向西部开放的重要窗口作用。云南城投集团所属云南水务抓住机遇,通过潜心耕耘和不懈努力,不断夯实在新疆水务环保市场的战略
...[详细]
在国家“一带一路”经济战略倡议下,新疆将发挥独特的区位优势和向西部开放的重要窗口作用。云南城投集团所属云南水务抓住机遇,通过潜心耕耘和不懈努力,不断夯实在新疆水务环保市场的战略
...[详细] 近日,南华期货股份有限公司(以下简称“南华期货”)在证监会网站披露招股说明书,拟在上交所公开发行不超过7000万股,发行后总股本不超过58000万股,保荐机构是中信证券(18.
...[详细]
近日,南华期货股份有限公司(以下简称“南华期货”)在证监会网站披露招股说明书,拟在上交所公开发行不超过7000万股,发行后总股本不超过58000万股,保荐机构是中信证券(18.
...[详细] 现在是大众创业时代,在各种福利政策下,创业得到大力支持,越来越多的自己当家做主,创业当老板自己当家做主,但是问题来了,注册公司的时候注册资金越多越好吗?还有人说刚注册的新公司没有业务可以不用记账报税?
...[详细]
现在是大众创业时代,在各种福利政策下,创业得到大力支持,越来越多的自己当家做主,创业当老板自己当家做主,但是问题来了,注册公司的时候注册资金越多越好吗?还有人说刚注册的新公司没有业务可以不用记账报税?
...[详细]“放水养鱼”式管理激发市场活力 安徽降本减负典型经验做法获点赞
 学会“放水养鱼”,尽一切努力把企业负担降下来。11月15日,记者从第十届安徽省减负政策宣传周上了解到,截至9月底,规模以上工业企业每百元营业收入中的成本为83.73元,这一数字
...[详细]
学会“放水养鱼”,尽一切努力把企业负担降下来。11月15日,记者从第十届安徽省减负政策宣传周上了解到,截至9月底,规模以上工业企业每百元营业收入中的成本为83.73元,这一数字
...[详细] 上海证券报独家刊发《搅动汇源通信资本漩涡 玩家唐小宏浮现》一文后,监管部门迅速发问。深交所4月23日早间披露有关汇源通信的六份关注函,问询的对象分别为北京鸿晓、上海乐铮、珠海泓沛、安徽鸿旭、蕙富骐骥及
...[详细]
上海证券报独家刊发《搅动汇源通信资本漩涡 玩家唐小宏浮现》一文后,监管部门迅速发问。深交所4月23日早间披露有关汇源通信的六份关注函,问询的对象分别为北京鸿晓、上海乐铮、珠海泓沛、安徽鸿旭、蕙富骐骥及
...[详细]恒指将迎来重大变化:阿里、美团及小米8月可纳入成份股选股范围
 恒生公司高层表示,阿里、美团及小米8月可纳入成份股选股范围。受此消息影响,阿里港股股价今日上涨超10%。恒生指数有限公司董事兼研究及分析主管黄伟雄近日在网上研讨会表示,通常来说恒指成份股需要有2年上市
...[详细]
恒生公司高层表示,阿里、美团及小米8月可纳入成份股选股范围。受此消息影响,阿里港股股价今日上涨超10%。恒生指数有限公司董事兼研究及分析主管黄伟雄近日在网上研讨会表示,通常来说恒指成份股需要有2年上市
...[详细] 2017年11月份,中国制造业采购经理指数(PMI)为51.8%,比上月上升0.2个百分点,制造业继续保持稳中有升的发展态势。分企业规模看,大型企业PMI为52.9%,比上月微落0.2个百分点,继续在
...[详细]
2017年11月份,中国制造业采购经理指数(PMI)为51.8%,比上月上升0.2个百分点,制造业继续保持稳中有升的发展态势。分企业规模看,大型企业PMI为52.9%,比上月微落0.2个百分点,继续在
...[详细]金富科技(003018.SZ)2020年度净利润降14.99% 基本每股收益0.44元
 金富科技(003018.SZ)发布2020年年度报告,实现营业收入5.14亿元,同比下降14.01%;归属于母公司所有者的净利润8820.90万元,同比下降14.99%;归属于上市公司股东的扣除非经常
...[详细]
金富科技(003018.SZ)发布2020年年度报告,实现营业收入5.14亿元,同比下降14.01%;归属于母公司所有者的净利润8820.90万元,同比下降14.99%;归属于上市公司股东的扣除非经常
...[详细] 上周,A股震荡中呈现重心下移走势。其中,上证指数击穿3100点,一度创下3041点年内新低。虽然芯片股走势造好,对创业板指有所支撑,但创业板指仍击穿1800点位。可见,目前A股走势仍相对疲弱。市场交易
...[详细]
上周,A股震荡中呈现重心下移走势。其中,上证指数击穿3100点,一度创下3041点年内新低。虽然芯片股走势造好,对创业板指有所支撑,但创业板指仍击穿1800点位。可见,目前A股走势仍相对疲弱。市场交易
...[详细] 花呗为什么提前还款是大忌 具体原因有哪些?
花呗为什么提前还款是大忌 具体原因有哪些?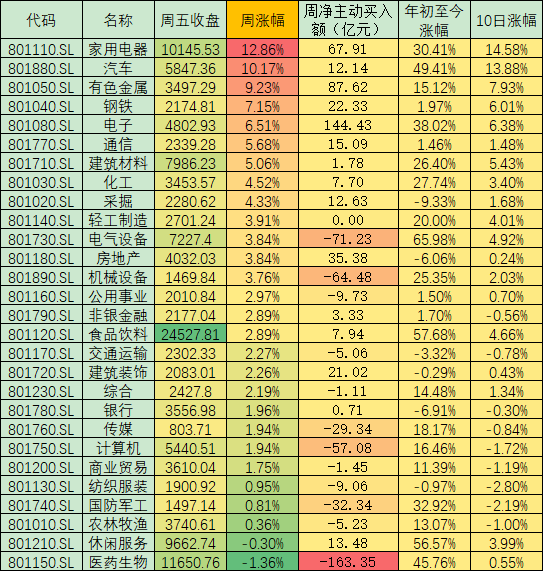 不确定性渐消沪指周涨2.72% 配置方面重点关注以下三条主线
不确定性渐消沪指周涨2.72% 配置方面重点关注以下三条主线 借款三千到账1650要还吗?看完就知道了!
借款三千到账1650要还吗?看完就知道了! 三季度基金代销机构公募基金保有规模前100强名单 银行C位不变
三季度基金代销机构公募基金保有规模前100强名单 银行C位不变
