本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,记住转载请联系出处。大模
GPT-4的型开使用成本,竟然是必备GPT-3.5的50倍之多;
而让大语言模型同时处理25个请求的时间,仅是手册数字处理单个请求的2倍……
这些数据听上去可能有些出乎意料,但都是记住真实的。

它们出自一篇名为《大语言模型(LLM)开发者必须知道的大模数字》的GitHub文章。
文章发布之后仅1天,型开便获得了1200次星标。必备

文章基于真实的手册数字开发经验,介绍了提示工程、记住硬件资源、价格等方面的数据。
就算没有成为开发者的打算,拿来扩充一下知识储备也是极好的。
我们不妨先来看一下文章作者制作的速览图表:

接下来,我们就来详细介绍一下这些数据。
40-90%:在提示词中加入“Be Concise”节约的成本
使用LLM是按照回复的token数量付费的,因此让LLM的回答简明扼要可以节约成本。
在提示词中加入“Be Concise”(答案简明些),可以节约40-90%的成本。
1.3:每个单词的平均token数
LLM是对token进行操作的,token可能包含完整单词或其中的一部分。
如“eating”是由“eat”和后缀“ing”两个token组成。
一篇750词的英文文章中大约含有1000个token。
而对于其他语言,每个词所含的token数量可能更多。
价格数据会存在波动,本节的价格数据主要参考OpenAI,但其他公司数据也相似。
约50倍:GPT-4与GPT-3.5花费的比值
效果上,GPT-4的表现明显好于GPT-3.5,但其成本约为后者的50倍之多。
因此,对于诸如总结这类GPT-3.5也能出色完成的任务,可以考虑不使用更昂贵的GPT-4。
5倍:GPT-3.5-Turbo生成与使用OpenAI embedding的成本比
诸如“美国的首都是哪里”这类可以通过检索得到答案的问题,让LLM生成答案的成本是检索的5倍。
而如果使用GPT-4,成本差异将高达250倍。
10倍:OpenAI embedding与自建embedding的成本比
这一数字为大约数值,实际情况可能随着embedding的规模而变化。
6倍:微调版与基本版OpenAI模型的成本比值
尽管成本较为昂贵,但对基本OpenAI模型的微调是有意义的。
对基本模型进行微调的效益明显高于定制模型。
1倍:自建模型是否进行微调的成本比
由于参数量相同,是否进行微调对自建模型的成本几乎没有影响。
约100万美元:在1.4万亿token上训练130亿参数模型的成本
这一数字是建立在一切工作都十分顺利、没有发生崩溃的前提下计算出的。
Meta的大语言模型LLaMA的论文当中显示,用2048块80GB A100 GPU进行训练LLaMA一共花费了21天。
<0.001:微调与从头开始训练的成本比
这一数据有一些笼统,但微调的成本几乎可以忽略不计。
对一个60亿参数模型进行微调的成本大约是7美元。
即使是最贵的OpenAI模型Davinci,1000个token的微调成本也只有3美分。
相对于对一部莎士比亚全集进行微调也只需要40美元。
如果你要自建模型,了解其GPU消耗十分重要。
本节所列数据仅是推理过程所消耗的资源量,训练和微调过程还需要更多资源。
V100: 16GB, A10G: 24GB, A100: 40/80GB:GPU内存大小
GPU内存大小决定了LLM的参数量上限。
24GB的A10G在亚马逊云服务中的价格为1.5-2美元每小时。
参数量的2倍:LLM的典型GPU内存需求
例如,7B参数量的LLM需要消耗14GB的GPU内存。
这是因为大多数时候,每个参数需要16bit浮点空间。
通常情况下不需要使用超过16bit的精度,8bit则会显著降低结果精准度。
约1GB:嵌入式模型的典型GPU内存需求
嵌入式模型消耗的本地GPU资源是很小的。
甚至可以在一块GPU上同时运行多个嵌入式模型。
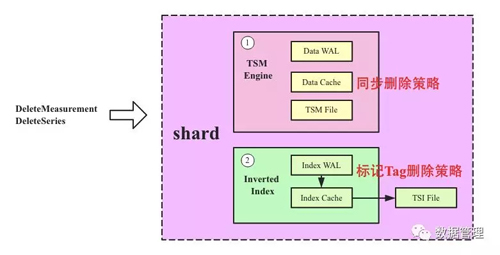
超过10倍:批量处理LLM请求带来的吞吐量改善
在GPU上运行LLM时往往会有较大延迟。
一次请求消耗的时间可能长达5秒,相对于每秒仅能处理0.2个。
但如果同时发送两个请求,消耗的时间约为5.2秒。
而将25个请求捆绑发出的耗时约为10秒,相对于每秒可处理2.5个请求。
约1MB:130亿参数模型输出1个token所需的GPU内存
内存消耗量与生成token数成正比。
512个token(约380个英文单词)需要消耗512MB的空间。
这篇文章的作者来自开源人工智能框架Ray的开发公司Anyscale。
主要贡献者是Google前首席工程师Waleed Kadous。
他也曾担任Uber CTO办公室工程战略负责人。
其中一位华人合作者是Google前员工Huaiwei Sun。
他来自江苏昆山,本科毕业于上海交通大学工业设计专业。
期间,他参加了耶鲁大学summer school并取得了满绩。
此后他取得了佐治亚理工学院硕士学位,研究方向为人机交互。
此外还有其他作者也参与了这篇文章的工作,未来也可能有更多人加入。
参考链接:
[1]https://github.com/ray-project/llm-numbers
[2]https://www.linkedin.com/in/scottsun94/

(责任编辑:综合)
中证金力挺民企债券融资专项计划 完善民营企业债券融资支持机制
 民企债券融资迎来重要支持方案。证监会11日晚称,交易所债券市场推出民营企业债券融资专项支持计划,以稳定和促进民营企业债券融资。中证金正是大名鼎鼎的国家队,成立于2011年10月,2015年市场大幅波动
...[详细]
民企债券融资迎来重要支持方案。证监会11日晚称,交易所债券市场推出民营企业债券融资专项支持计划,以稳定和促进民营企业债券融资。中证金正是大名鼎鼎的国家队,成立于2011年10月,2015年市场大幅波动
...[详细] 进入5月份后,百亿元级证券类私募阵营再度扩容。《证券日报》记者对私募排排网最新数据梳理后发现,继4月份新增5家百亿元级证券类私募后,5月份又新增一家。截至今年5月13日,国内百亿元级证券类私募数量已增
...[详细]
进入5月份后,百亿元级证券类私募阵营再度扩容。《证券日报》记者对私募排排网最新数据梳理后发现,继4月份新增5家百亿元级证券类私募后,5月份又新增一家。截至今年5月13日,国内百亿元级证券类私募数量已增
...[详细]多家头部券商科创板权限开通人数已超10万 券商建议等二级市场申购机会
 记者/周尚伃 见习记者/王思文6月13日,中国资本市场迎来了历史性时刻,历经仅仅220天,科创板正式开板。上海证券交易所理事长黄红元预计,未来两个月内将看到首批企业在科创板上市交易。对各类投资者来说,
...[详细]
记者/周尚伃 见习记者/王思文6月13日,中国资本市场迎来了历史性时刻,历经仅仅220天,科创板正式开板。上海证券交易所理事长黄红元预计,未来两个月内将看到首批企业在科创板上市交易。对各类投资者来说,
...[详细] 我们经常把中股市叫A股,因为对于我们来说接触比较多的就是A股,其实,除了A股之外,我们还有B股。下面小编给大家说说,中国股市中怎么买B股,哪些人才可以买?哪些人可以投资B股B股的正式名称是人民币特种股
...[详细]
我们经常把中股市叫A股,因为对于我们来说接触比较多的就是A股,其实,除了A股之外,我们还有B股。下面小编给大家说说,中国股市中怎么买B股,哪些人才可以买?哪些人可以投资B股B股的正式名称是人民币特种股
...[详细] 继定增方案获证监会核准后,广州农商行确定了内资股定价区间。11月9日,广州农商行发布公告称,非公开发行不超过13.40亿股内资股的发行定价区间为5.48-6.69元。北京商报记者注意到,除内资股外,广
...[详细]
继定增方案获证监会核准后,广州农商行确定了内资股定价区间。11月9日,广州农商行发布公告称,非公开发行不超过13.40亿股内资股的发行定价区间为5.48-6.69元。北京商报记者注意到,除内资股外,广
...[详细]331只破净股逾八成跑赢大盘 部分破净股已受到场内资金的青睐
 “震荡、回落、分化。”已悄然成为描述近日A股市场的高频词。在此期间,沪深两市破净股数量也有所增加。通常来说,破净股数量与行情相关性较强,股市低迷时破净股数量大幅增加,在板块估值
...[详细]
“震荡、回落、分化。”已悄然成为描述近日A股市场的高频词。在此期间,沪深两市破净股数量也有所增加。通常来说,破净股数量与行情相关性较强,股市低迷时破净股数量大幅增加,在板块估值
...[详细] 为化解信托业不良资产风险,推动信托业转型发展,银保监会近日下发《关于推进信托公司与专业机构合作处置风险资产的通知》(以下简称《通知》),支持信托公司与中国信托业保障基金有限责任公司(以下简称&ldqu
...[详细]
为化解信托业不良资产风险,推动信托业转型发展,银保监会近日下发《关于推进信托公司与专业机构合作处置风险资产的通知》(以下简称《通知》),支持信托公司与中国信托业保障基金有限责任公司(以下简称&ldqu
...[详细]国家统计局:2021年4月份规模以上工业增加值增长9.8% 比2019年同期增长14.1%
 据国家统计局网站消息,4月份,规模以上工业增加值同比实际增长9.8%(以下增加值增速均为扣除价格因素的实际增长率),比2019年同期增长14.1%,两年平均增长6.8%。从环比看,4月份,规模以上工业
...[详细]
据国家统计局网站消息,4月份,规模以上工业增加值同比实际增长9.8%(以下增加值增速均为扣除价格因素的实际增长率),比2019年同期增长14.1%,两年平均增长6.8%。从环比看,4月份,规模以上工业
...[详细] 农行银行卡默认开通小额免密免签支付功能,虽然平时消费方便,但也存在安全隐患,那么在农行掌上银行上要怎么关闭小额免密支付功能呢?农行掌上银行怎么关闭小额免密支付?【1】首先在手机上打开并登录农业银行Ap
...[详细]
农行银行卡默认开通小额免密免签支付功能,虽然平时消费方便,但也存在安全隐患,那么在农行掌上银行上要怎么关闭小额免密支付功能呢?农行掌上银行怎么关闭小额免密支付?【1】首先在手机上打开并登录农业银行Ap
...[详细] 近期,玉米、豆粕等期货价格持续在高位盘整。同花顺数据显示,5月14日下午,玉米主力合约2109以2782元/吨报收,5月12日,该合约最高曾上探至2887元/吨,创出该合约2021年新高,近两个交易日
...[详细]
近期,玉米、豆粕等期货价格持续在高位盘整。同花顺数据显示,5月14日下午,玉米主力合约2109以2782元/吨报收,5月12日,该合约最高曾上探至2887元/吨,创出该合约2021年新高,近两个交易日
...[详细] 好消息!全国首个百万千瓦煤电机组节能减排升级与改造示范项目建成投产
好消息!全国首个百万千瓦煤电机组节能减排升级与改造示范项目建成投产 广州开展房地产市场秩序专项联合整治 涉及40余项违法违规行为
广州开展房地产市场秩序专项联合整治 涉及40余项违法违规行为 券商今年以来获准新设26家分公司 呈现三大业务模式
券商今年以来获准新设26家分公司 呈现三大业务模式 港媒:中国已进入“大众旅游”时代 旅游成“刚性需求”
港媒:中国已进入“大众旅游”时代 旅游成“刚性需求”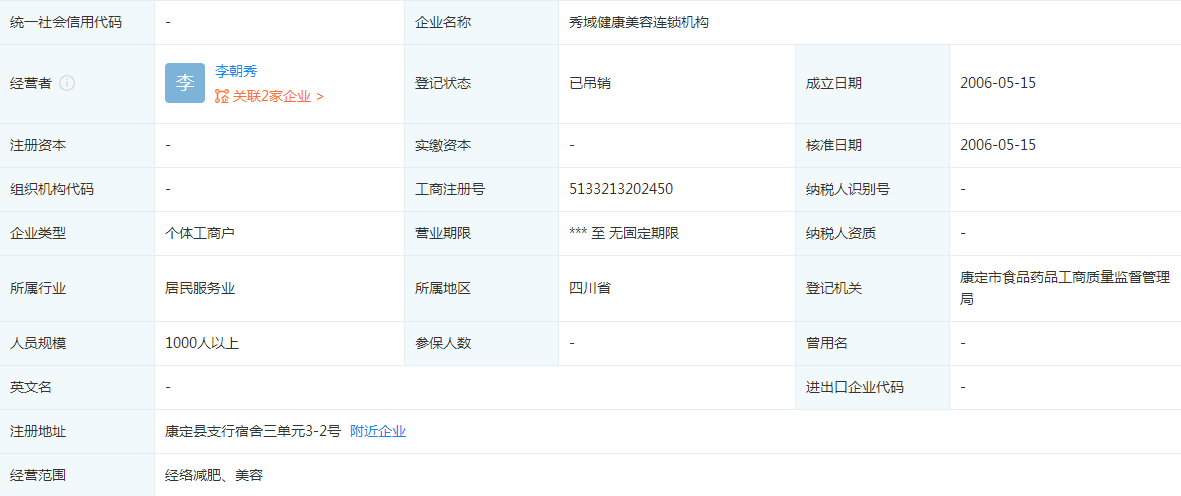 秀域健康美容连锁机构地址在哪 属于四川省企业吗?
秀域健康美容连锁机构地址在哪 属于四川省企业吗?