
SpaCy是前最一个流行的Python自然语言处理库,它旨在提供快速、受欢高效和易于使用的迎的语API,具有一些内置的语言模型,可以用于处理多种语言的文本数据。本文将深入介绍SpaCy的使用方法,并提供完整的代码示例。文章包含以下内容:

在使用SpaCy之前,需要先安装和加载语言模型。可以使用以下命令安装SpaCy库:

pip install spacy然后,使用以下命令下载和安装英文语言模型(en_core_web_sm):

python -m spacy download en_core_web_sm或者在Python中使用以下代码:
import spacyspacy.cli.download("en_core_web_sm")加载模型的方式如下:
import spacynlp = spacy.load("en_core_web_sm")这将返回一个nlp对象,可以用于对文本进行自然语言处理。
分词是将文本分割成单独的单词或标点符号的过程。在SpaCy中,可以使用nlp对象对文本进行分词,返回一个Doc对象,其中包含分词后的单词和标点符号。
import spacynlp = spacy.load("en_core_web_sm")text = "This is a sample sentence."doc = nlp(text)for token in doc: print(token.text)输出结果如下:
Thisisasamplesentence.在Doc对象中,每个单词和标点符号都表示为一个Token对象,可以使用以下属性获取有关每个单词的信息:
词性标注是将每个单词标记为其词性的过程。在SpaCy中,可以使用pos_属性获取每个单词的词性标注。
import spacynlp = spacy.load("en_core_web_sm")text = "This is a sample sentence."doc = nlp(text)for token in doc: print(token.text, token.pos_)输出结果如下:
This DETis AUXa DETsample ADJsentence NOUN. PUNCT在SpaCy中,每个词性都由一个简短的标记表示,例如“DET”表示限定词,“AUX”表示助动词,“ADJ”表示形容词,“NOUN”表示名词,“PUNCT”表示标点符号等。
命名实体识别是将文本中的命名实体(如人名、地名、组织机构名等)识别出来并分类的过程。在SpaCy中,可以使用ents属性获取文本中的所有命名实体。
import spacynlp = spacy.load("en_core_web_sm")text = "Apple is looking at buying U.K. startup for $1 billion"doc = nlp(text)for ent in doc.ents: print(ent.text, ent.label_)输出结果如下:
Apple ORGU.K. GPE$1 billion MONEY在SpaCy中,每个命名实体都由一个文本和一个标记表示,例如“ORG”表示组织机构名,“GPE”表示地名,“MONEY”表示货币等。
词向量是将每个单词表示为一个向量的过程,通常用于计算单词之间的相似度。在SpaCy中,可以使用vector属性获取每个单词的词向量。
import spacynlp = spacy.load("en_core_web_sm")text = "apple orange banana"doc = nlp(text)for token in doc: print(token.text, token.vector[:5])输出结果如下:
apple [-0.3806592 -0.40239993 -0.37081954 0.2110903 0.26755404]orange [-0.22226666 -0.6683903 -0.36496514 0.13861726 0.4222792 ]banana [-0.14758453 -0.29266724 -0.47932914 0.4107659 0.40180257]在SpaCy中,每个单词都表示为一个300维的向量。可以使用向量计算来计算单词之间的相似度,例如余弦相似度。
依存句法分析是将句子中的单词组织成一个依存树的过程,其中每个单词都是一个节点,每个依存关系都是一个边。在SpaCy中,可以使用dep_属性和head属性获取每个单词的依存关系和其父节点。
import spacynlp = spacy.load("en_core_web_sm")text = "This is a sample sentence."doc = nlp(text)for token in doc: print(token.text, token.dep_, token.head.text)输出结果如下:
This nsubj isis ROOT isa det sentencesample amod sentencesentence attr is. punct is在SpaCy中,每个依存关系都由一个简短的标记表示,例如“nsubj”表示主语,“amod”表示形容词修饰符,“attr”表示谓语等。
文本分类是将文本分为不同类别的过程。在SpaCy中,可以使用textcat组件进行文本分类。首先,需要创建一个TextCategorizer对象,然后使用add_label方法添加类别,最后使用train方法训练模型。
import spacyfrom spacy.pipeline.textcat import TextCategorizernlp = spacy.load("en_core_web_sm")textcat = nlp.create_pipe("textcat", config={ "exclusive_classes": True})textcat.add_label("POSITIVE")textcat.add_label("NEGATIVE")nlp.add_pipe(textcat)train_data = [ ("This is a positive sentence.", { "cats": { "POSITIVE": 1, "NEGATIVE": 0}}), ("This is a negative sentence.", { "cats": { "POSITIVE": 0, "NEGATIVE": 1}}),]optimizer = nlp.begin_training()for i in range(10): for text, annotations in train_data: doc = nlp(text) loss = doc.cats optimizer.update(loss, doc)在训练完成后,可以使用以下代码对新的文本进行分类:
doc = nlp("This is a positive sentence.")print(doc.cats)输出结果如下:
{ 'POSITIVE': 0.996676206111908, 'NEGATIVE': 0.0033238078881202936}语义相似度计算是比较两个文本之间的相似程度的过程。在SpaCy中,可以使用similarity方法计算两个文本之间的相似度。
import spacynlp = spacy.load("en_core_web_sm")text1 = "apple orange banana"text2 = "orange banana kiwi"doc1 = nlp(text1)doc2 = nlp(text2)similarity = doc1.similarity(doc2)print(similarity)输出结果如下:
0.6059834960774745在SpaCy中,相似度的范围在0到1之间,其中1表示完全相似,0表示没有相似之处。
SpaCy允许用户根据自己的需求添加自定义组件和扩展功能。可以使用Language.add_pipe方法在管道中添加自定义组件,也可以使用Language.factory方法创建自定义组件。
以下是一个简单的自定义组件,用于将文本中的大写字母转换为小写字母:
import spacyfrom spacy.tokens import Docdef to_lowercase(doc): words = [token.text.lower() for token in doc] return Doc(doc.vocab, words=words)nlp = spacy.load("en_core_web_sm")nlp.add_pipe(to_lowercase, name="to_lowercase", first=True)doc = nlp("This Is A Sample Sentence.")for token in doc: print(token.text)输出结果如下:
thisisasamplesentence.除了自定义组件外,还可以通过扩展SpaCy的Doc、Token和Span等类来添加自定义属性和方法。以下是一个简单的示例,添加了一个名为is_email的自定义属性:
import spacyfrom spacy.tokens import Doc, Tokendef set_is_email(doc): for token in doc: if "@" in token.text: token._.is_email = True return docToken.set_extension("is_email", default=False)Doc.set_extension("is_email", getter=lambda doc: any(token._.is_email for token in doc))nlp = spacy.load("en_core_web_sm")nlp.add_pipe(set_is_email, name="set_is_email", first=True)doc = nlp("My email is example@example.com.")print(doc._.is_email)输出结果为True,表示文本中包含一个电子邮件地址。
本文介绍了SpaCy的常用API,包括安装和加载模型、分词、词性标注、命名实体识别、词向量生成、依存句法分析、文本分类和语义相似度计算。同时还介绍了如何添加自定义组件和扩展。通过这些API,可以轻松地对文本进行自然语言处理,并且可以根据自己的需求添加自定义功能。
责任编辑:姜华 来源: 今日头条 SpaCy自然语言(责任编辑:时尚)
 目前北京市租赁市场处于淡季,叠加部分区域疫情反弹的因素,11月租赁市场呈现加速降温趋势。11月29日,根据贝壳研究院数据,11月北京市租赁成交量环比减少超过10%,各城区租赁市场均保持降温趋势。从租金
...[详细]
目前北京市租赁市场处于淡季,叠加部分区域疫情反弹的因素,11月租赁市场呈现加速降温趋势。11月29日,根据贝壳研究院数据,11月北京市租赁成交量环比减少超过10%,各城区租赁市场均保持降温趋势。从租金
...[详细] 客户体验在物联网的边缘计算作者:骄阳 编译 2018-09-21 14:15:28物联网 边缘计算 今天,数据正在许多不太可能的地方进行处理和使用,这是物联网时代的自然产物。然而,获得连网设备的所有优
...[详细]
客户体验在物联网的边缘计算作者:骄阳 编译 2018-09-21 14:15:28物联网 边缘计算 今天,数据正在许多不太可能的地方进行处理和使用,这是物联网时代的自然产物。然而,获得连网设备的所有优
...[详细] 无线信号故障排查详解作者:佚名 2010-09-27 13:25:39运维 网络运维 对于无线网络的使用,我们都已经很熟悉了,但是对于信号不稳定,信号衰弱等原因我们该如何去解决呢? 本文主要给大家详细
...[详细]
无线信号故障排查详解作者:佚名 2010-09-27 13:25:39运维 网络运维 对于无线网络的使用,我们都已经很熟悉了,但是对于信号不稳定,信号衰弱等原因我们该如何去解决呢? 本文主要给大家详细
...[详细] Oracle临时表的用法总结作者:悠虎 2011-03-16 09:42:27数据库 Oracle Oracle 的临时表创建之后基本不占用表空间,如果你没有指定临时表(包括临时表的索引)存放的表空的
...[详细]
Oracle临时表的用法总结作者:悠虎 2011-03-16 09:42:27数据库 Oracle Oracle 的临时表创建之后基本不占用表空间,如果你没有指定临时表(包括临时表的索引)存放的表空的
...[详细]云南省国资委印发《关于加快推进绿色国资建设的实施意见》 推进示范引领
 为推动国资国企坚定不移走生态优先、绿色发展之路,以绿色国资建设助力国资国企高质量发展,云南省国资委印发《关于加快推进绿色国资建设的实施意见》(以下简称《意见》)。《意见》强调,全云南国资国企要全面践行
...[详细]
为推动国资国企坚定不移走生态优先、绿色发展之路,以绿色国资建设助力国资国企高质量发展,云南省国资委印发《关于加快推进绿色国资建设的实施意见》(以下简称《意见》)。《意见》强调,全云南国资国企要全面践行
...[详细] 如何更新 openSUSE Linux 系统作者:Abhishek Prakash 2021-03-13 12:17:59系统 Linux 随着我对 openSUSE 的不断探索,我不断发现 SUSE
...[详细]
如何更新 openSUSE Linux 系统作者:Abhishek Prakash 2021-03-13 12:17:59系统 Linux 随着我对 openSUSE 的不断探索,我不断发现 SUSE
...[详细]SatSure获得1500万美元A轮融资,Promus Ventures领投
 艾媒咨询9月26日消息,SatSure宣布已完成1500万美元A轮融资。据了解,本轮融资由Baring Private Equity PartnersBPEP),India和Promus Ventur
...[详细]
艾媒咨询9月26日消息,SatSure宣布已完成1500万美元A轮融资。据了解,本轮融资由Baring Private Equity PartnersBPEP),India和Promus Ventur
...[详细] 【CNMO新闻】提起茶颜悦色,相信大家都非常熟悉。作为长沙的网红店,它不仅获得了本地市民的青睐,更吸引了众多慕名而来的外地游客,俘获了无数消费者的芳心。不得不说,茶颜悦色凭借着口味、服务、宣传等在市场
...[详细]
【CNMO新闻】提起茶颜悦色,相信大家都非常熟悉。作为长沙的网红店,它不仅获得了本地市民的青睐,更吸引了众多慕名而来的外地游客,俘获了无数消费者的芳心。不得不说,茶颜悦色凭借着口味、服务、宣传等在市场
...[详细] 京东是一个非常注重品质和送货速度的购物平台,为了满足用户的消费需求,京东也推出了京东白条、京东金条等服务,京东白条主要为用户购物时提供先消费后付款的支付服务,而京东金条就类似于支付宝借呗、微信微粒贷了
...[详细]
京东是一个非常注重品质和送货速度的购物平台,为了满足用户的消费需求,京东也推出了京东白条、京东金条等服务,京东白条主要为用户购物时提供先消费后付款的支付服务,而京东金条就类似于支付宝借呗、微信微粒贷了
...[详细]德恩精工(300780.SZ):2023年9月26日因涨幅达到15%而异动上榜
 德恩精工(300780.SZ):2023年9月26日交易异动上榜,异动类型为涨幅达到15%,异动上榜前五卖出金额合计为67.801524百万元,异动上榜前五买入金额合计为58.383915百万元。以上
...[详细]
德恩精工(300780.SZ):2023年9月26日交易异动上榜,异动类型为涨幅达到15%,异动上榜前五卖出金额合计为67.801524百万元,异动上榜前五买入金额合计为58.383915百万元。以上
...[详细] 新能源板块成为反弹急先锋 板块调整已相对充分
新能源板块成为反弹急先锋 板块调整已相对充分 DDoS租用服务提供商vDOS的运营者被判六个月社区服务
DDoS租用服务提供商vDOS的运营者被判六个月社区服务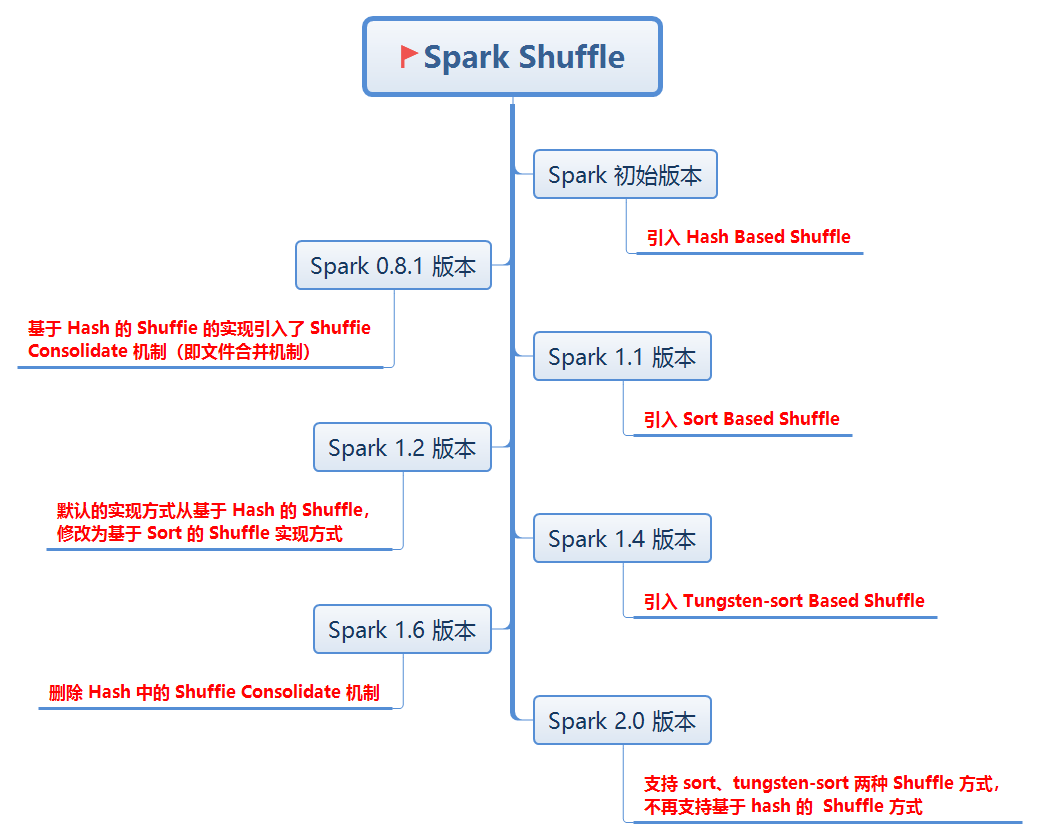 Spark的两种核心Shuffle详解
Spark的两种核心Shuffle详解 脸书已被美国年轻人抛弃?比TikTok更受欢迎的竟是它 -
脸书已被美国年轻人抛弃?比TikTok更受欢迎的竟是它 - 鹰君(00041.HK)授出499万份购股期权 惟须待承受人接纳方可作实
鹰君(00041.HK)授出499万份购股期权 惟须待承受人接纳方可作实
