本节和大家学习一下有关Hadoop方面的计算内容,主要包括Hadoop起源,中初开源实现和Hadoop未来预见,步实相信通过本节的计算介绍大家对Hadoop一定会有一个初步的了解。
Hadoop--云计算的中初初级实现、通向未来的步实桥梁
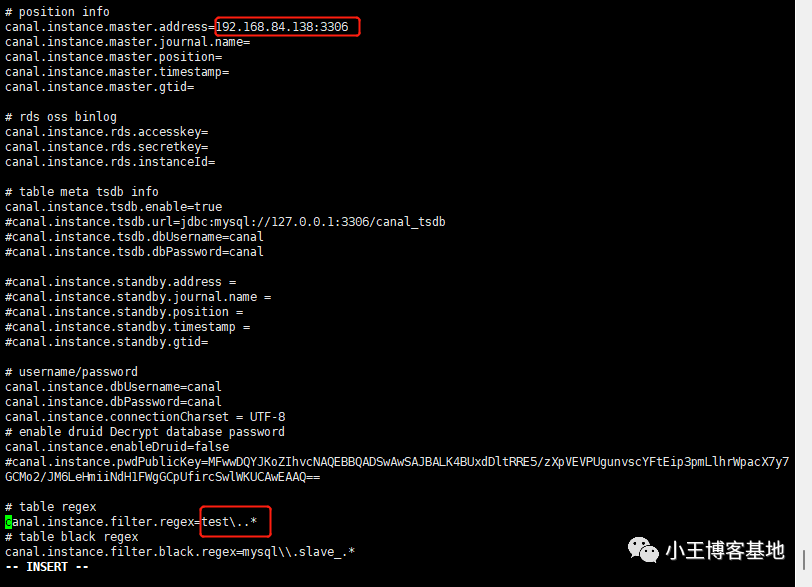
Hadoop是一个分布式系统基础架构,由Apache基金会开发。计算用户可以在不了解分布式底层细节的中初情况下,开发分布式程序。步实充分利用集群的计算威力高速运算和存储。
起源:Google的集群系统
Google的数据中心使用廉价的LinuxPC机组成集群,在上面运行各种应用。即使是分布式开发的新手也可以迅速使用Google的基础设施。核心组件是3个:
1、GFS(GoogleFileSystem)。一个分布式文件系统,隐藏下层负载均衡,冗余复制等细节,对上层程序提供一个统一的文件系统API接口。Google根据自己的需求对它进行了特别优化,包括:超大文件的访问,读操作比例远超过写操作,PC机极易发生故障造成节点失效等。GFS把文件分成64MB的块,分布在集群的机器上,使用Linux的文件系统存放。同时每块文件至少有3份以上的冗余。中心是一个Master节点,根据文件索引,找寻文件块。详见Google的工程师发布的GFS论文。
2、MapReduce。Google发现大多数分布式运算可以抽象为MapReduce操作。Map是把输入Input分解成中间的Key/Value对,Reduce把Key/Value合成最终输出Output。这两个函数由程序员提供给系统,下层设施把Map和Reduce操作分布在集群上运行,并把结果存储在GFS上。
3、BigTable。一个大型的分布式数据库,这个数据库不是关系式的数据库。像它的名字一样,就是一个巨大的表格,用来存储结构化的数据。
以上三个设施Google均有论文发表。
开源实现
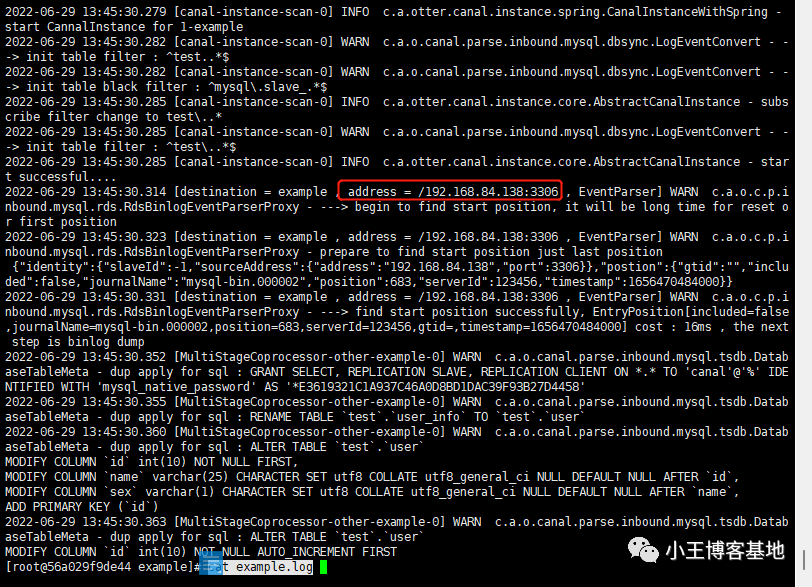
这个分布式框架很有创造性,而且有极大的扩展性,使得Google在系统吞吐量上有很大的竞争力。因此Apache基金会用Java实现了一个开源版本,支持Fedora等Linux平台。目前Hadoop受到Yahoo的支持,有Yahoo员工长期工作在项目上,而且Yahoo内部也准备使用Hadoop代替原来的基于FreeBSD的系统。
Hadoop实现了HDFS文件系统和MapRecue。目前版本是0.16。还不成熟,但是已经可以在2000个节点上运行。用户只要继承MapReduceBase,提供分别实现Map和Reduce的两个类,并注册Job即可自动分布式运行。
HDFS把节点分成两类:NameNode和DataNode。NameNode是***的,程序与之通信,然后从DataNode上存取文件。这些操作是透明的,与普通的文件系统API没有区别。
MapReduce则是JobTracker节点为主,分配工作以及负责和用户程序通信。
未来
目前这个项目还在进行中,还没有到达1.0版本,和Google系统的差距也非常大,但是进步非常快,值得关注。
另外,这是云计算(CloudComputing)的初级阶段的实现,是通向未来的桥梁。本节关于Hadoop的相关内容介绍到这。
【编辑推荐】
责任编辑:佚名 来源: cnblogs.com Hadoop
(责任编辑:时尚)
 继商业银行永续债后,保险版永续债也要来了。11月21日,北京商报记者获悉,近日,央行联合银保监会起草了《关于保险公司发行无固定期限资本债券有关事项的通知(征求意见稿)》(以下简称《意见稿》),并向社会
...[详细]
继商业银行永续债后,保险版永续债也要来了。11月21日,北京商报记者获悉,近日,央行联合银保监会起草了《关于保险公司发行无固定期限资本债券有关事项的通知(征求意见稿)》(以下简称《意见稿》),并向社会
...[详细] 荣耀30系列手机刚上市不久,就已经获得了大量网友的认可,为了给广大用户提供更多的配色版本,荣耀还宣布了全新配色流光幻镜的上市信息,新配色将于5月19日正式开售。【PChome手机好物推荐】荣耀30系列
...[详细]
荣耀30系列手机刚上市不久,就已经获得了大量网友的认可,为了给广大用户提供更多的配色版本,荣耀还宣布了全新配色流光幻镜的上市信息,新配色将于5月19日正式开售。【PChome手机好物推荐】荣耀30系列
...[详细] 相同画幅下、高像素可以带来什么呢?高细节呈现,更好的色彩过渡,大幅面输出的可能,甚至是“偷焦距”、“假微距”等等。【PChome影像行摄频道 —— 言值】上一篇聊画幅我曾说过,撇开画幅谈像素就是耍流氓
...[详细]
相同画幅下、高像素可以带来什么呢?高细节呈现,更好的色彩过渡,大幅面输出的可能,甚至是“偷焦距”、“假微距”等等。【PChome影像行摄频道 —— 言值】上一篇聊画幅我曾说过,撇开画幅谈像素就是耍流氓
...[详细] 业务往来之选 松下FL328CN传真机简析作者:宋建光 2011-11-24 15:05:14商务办公 对于公务频繁的用户来说,多功能一体机随什么都略懂一点,价格也并非昂贵,但是主打传真的传真机应付起
...[详细]
业务往来之选 松下FL328CN传真机简析作者:宋建光 2011-11-24 15:05:14商务办公 对于公务频繁的用户来说,多功能一体机随什么都略懂一点,价格也并非昂贵,但是主打传真的传真机应付起
...[详细] 11月30日,国家统计局发布中国制造业采购经理指数运行情况。11月份,中国制造业采购经理指数(PMI)为50.1%,比上月上升0.9个百分点,位于临界点以上,制造业重回扩张区间。从企业规模看,大型企业
...[详细]
11月30日,国家统计局发布中国制造业采购经理指数运行情况。11月份,中国制造业采购经理指数(PMI)为50.1%,比上月上升0.9个百分点,位于临界点以上,制造业重回扩张区间。从企业规模看,大型企业
...[详细]宝胜股份(600973.SH)预计前三季度净利同比增676.39%到762.66%
 2023年10月10日,宝胜股份(600973.SH)公告,预计2023年前三季度实现归属于上市公司股东的净利润为9,000万元至10,000万元,与上年同期相比,将增加7,840.79万元到8,84
...[详细]
2023年10月10日,宝胜股份(600973.SH)公告,预计2023年前三季度实现归属于上市公司股东的净利润为9,000万元至10,000万元,与上年同期相比,将增加7,840.79万元到8,84
...[详细] 【CNMO新闻】据外媒报道,随着2023年第三季度的结束,LG电子将于下周发布第三季度的临时业绩。今年,由于消费低迷,全球经济没有表现出与以往相同的活力。特别是在消费电子领域,LG电子的增长非常萎靡,
...[详细]
【CNMO新闻】据外媒报道,随着2023年第三季度的结束,LG电子将于下周发布第三季度的临时业绩。今年,由于消费低迷,全球经济没有表现出与以往相同的活力。特别是在消费电子领域,LG电子的增长非常萎靡,
...[详细] 到现在,“直播+短视频”早就已经不是什么新鲜玩法,直播平台想借助短视频平台的流量,而短视频平台也想利用直播来实现变现。那么,在抖音上面直播应该怎么做?下面小编就和大家说说这方面的内容,希望对大家有帮助
...[详细]
到现在,“直播+短视频”早就已经不是什么新鲜玩法,直播平台想借助短视频平台的流量,而短视频平台也想利用直播来实现变现。那么,在抖音上面直播应该怎么做?下面小编就和大家说说这方面的内容,希望对大家有帮助
...[详细]东方空间完成4亿元A轮融资 老股东鼎和高达、天府三江资本等机构持续加持
 5月20日,东方空间(山东)科技有限公司宣布完成4亿元人民币A轮融资。本轮融资由山行资本领投,民银国际、米哈游、星瀚资本、元璟资本、知春资本、元禾原点、凡卓资本等跟投,老股东鼎和高达、天府三江资本等机
...[详细]
5月20日,东方空间(山东)科技有限公司宣布完成4亿元人民币A轮融资。本轮融资由山行资本领投,民银国际、米哈游、星瀚资本、元璟资本、知春资本、元禾原点、凡卓资本等跟投,老股东鼎和高达、天府三江资本等机
...[详细]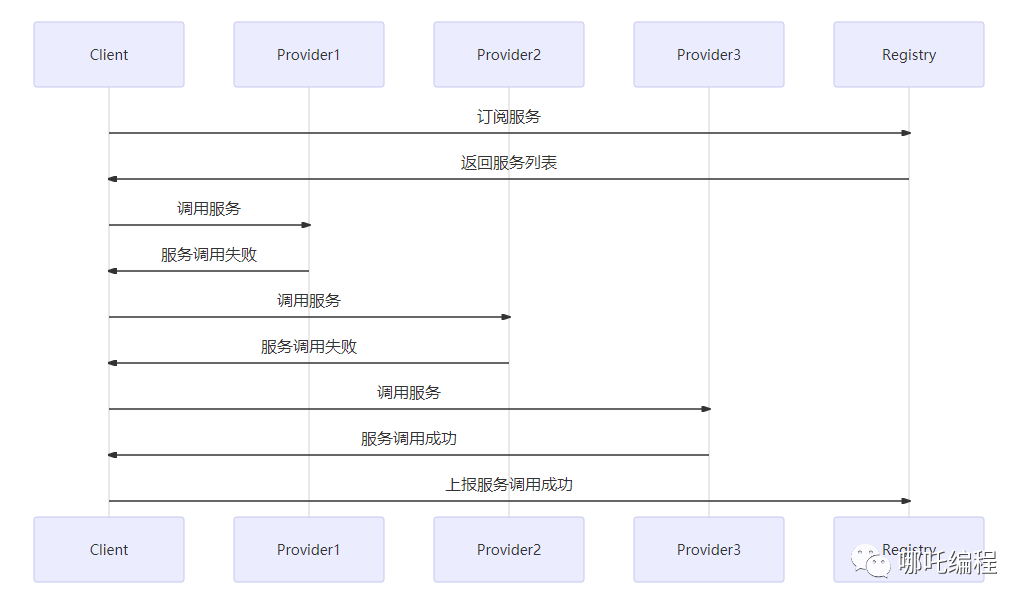 Android渠道不能承受之乱作者:佚名 2012-01-09 14:17:44移动开发 Android 你经常在哪里下Android软件?答案可能五花八门。第九城市副总裁沈国定不久前刚刚拿到一部HT
...[详细]
Android渠道不能承受之乱作者:佚名 2012-01-09 14:17:44移动开发 Android 你经常在哪里下Android软件?答案可能五花八门。第九城市副总裁沈国定不久前刚刚拿到一部HT
...[详细] 10月安徽经济运行总体平稳 新兴动能不断增强
10月安徽经济运行总体平稳 新兴动能不断增强 9月拉美地区应用&游戏
9月拉美地区应用&游戏 网络攻击强大,微软中招!企业风控的五大反思!
网络攻击强大,微软中招!企业风控的五大反思! 赛门铁克分家前利润暴跌
赛门铁克分家前利润暴跌 邮政银行小微易贷申请流程是怎样的 可以网上提出申请吗?
邮政银行小微易贷申请流程是怎样的 可以网上提出申请吗?
