[[321167]]
经常听到这样的进行事情,某个程序员在后台执行个Sql语句,排序然后把线上服务都拖垮了。用性有些人会认为,Sql的执行性能是DBA的事情,但是随着互联网的发展,对开发的要求也越来越高,特别是一些小团队,巴不得人人都是全栈工程师。今天我们来聊一聊Mysql中的排序,Order By。


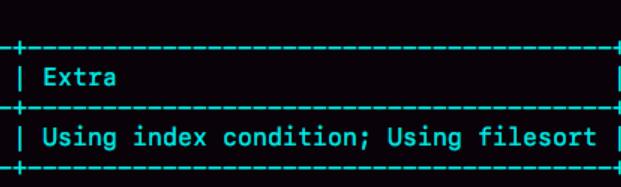

在我们执行Mysql的Explain语句的时候,经常会看到这样的一个Using filesort。那么,Mysql的排序是在内存里面进行的,还是在磁盘里面进行的呢?假如我们是Mysql的设计者,我们会怎么做呢?首先,在内存里面来进行排序的速度,肯定是远远大于在磁盘中的。但是内存的资源毕竟有限,假如我们扫描到足够多的行,这个时候可能数据的大小已经超过内存,想在内存中进行排序是很困难的,这个时候我们只能够使用磁盘来进行排序了。
没错,Mysql也是这么设计的,Mysql有一个配置项,sort_buffer_size,如果我们Select到的数据量小于这个数,那么就会将数据在内存中进行排序,否则,Mysql就会把数据拆成很多个临时文件,每个临时文件的大小都会小于sort_buffer_size。也就是说,如果sort_buffer_size越小,拆分的临时文件就会越多,这也是为什么我们选来当存储的机器内存也要尽量大的原因。Mysql排序了多个临时文件之后,最后在做一次归并排序,就可以将所有记录排完了。
相信大家下面这样的话,如果你的数据库的列数比较多,那么尽量地不要使用Select * 而是需要什么字段就只取什么字段,在数据库的排序中尤为如此。假如我们的数据列数特别多,满足条件的行数也多,这个时候,Mysql就不得不用更极端的排序算法进行排序,每一行数据,都只取主键id跟排序的字段。然后进行排序,最后,再取要满足条件的结果回表查询其他字段,然后返回结果。相对于原有上面的方案,这种Rowid的排序方式多了一次回表,所以查询效率大打折扣。
那么,我们有什么办法可以进行排序的优化呢?我们都知道,Innodb的索引实际上是一颗多叉排序树,那么假如我们能够在已有的排序树上取得结果,岂不美哉?!所以,如果我们要查询已经要排序的字段全都在已有的索引上,并且满足最左前缀原则,那么,我们就可以减少一次回表,从而大大提升效率。那么,如果判断你的Sql语句满足了这种优化呢?如果你的语句中含有OrderBy,但是Explain的结果却只有UseIndex,说明命中了索引覆盖。
当然,并不是所有的查询都要命中索引覆盖的,前面我们也提到了,维护索引是由代价的,还是需要具体问题具体分析。
责任编辑:华轩 来源: 今日头条 MySQLSQL数据库(责任编辑:热点)
皇朝家居(01198.HK)发布公告:年度归母净利同比下降89.2%
 皇朝家居(01198.HK)发布公告,截至2021年12月31日止年度,实现收入15.27亿港元,同比增长5.75%;母公司拥有人应占溢利7689.7万港元,同比下降89.2%;基本每股盈利2.999
...[详细]
皇朝家居(01198.HK)发布公告,截至2021年12月31日止年度,实现收入15.27亿港元,同比增长5.75%;母公司拥有人应占溢利7689.7万港元,同比下降89.2%;基本每股盈利2.999
...[详细] 【CNMO新闻】近日,中国执行信息公开网显示,恒大恒驰新能源汽车研究院上海)有限公司新增两则被执行人信息,执行标的合计4214万余元,涉及施工合同纠纷案件等。CNMO获悉,执行法院为上海市松江区人民法
...[详细]
【CNMO新闻】近日,中国执行信息公开网显示,恒大恒驰新能源汽车研究院上海)有限公司新增两则被执行人信息,执行标的合计4214万余元,涉及施工合同纠纷案件等。CNMO获悉,执行法院为上海市松江区人民法
...[详细] 雷锋网消息,微软10月14日宣布关闭领英中国服务。10月14日晚间,领英官方微博回应称关闭服务为不实消息”。据了解,微软领英中国总裁陆坚在关闭服务之前发布了“致领英中国会员的一封信”。信中提到,自20
...[详细]
雷锋网消息,微软10月14日宣布关闭领英中国服务。10月14日晚间,领英官方微博回应称关闭服务为不实消息”。据了解,微软领英中国总裁陆坚在关闭服务之前发布了“致领英中国会员的一封信”。信中提到,自20
...[详细]HDC2021盘点:开发者三年翻十倍,华为HMS如何快速“星火燎原”
 在上周的华为开发者大会2021HDC)上,华为正式宣布HMS开发者数量突破510万,相比2018年的56万,三年增长近十倍!华为如何做到一步步打动开发者,让HMS成为开发者在Android和iOS之外
...[详细]
在上周的华为开发者大会2021HDC)上,华为正式宣布HMS开发者数量突破510万,相比2018年的56万,三年增长近十倍!华为如何做到一步步打动开发者,让HMS成为开发者在Android和iOS之外
...[详细]鹰君(00041.HK)授出499万份购股期权 惟须待承受人接纳方可作实
 鹰君(00041.HK)宣布,于2021年3月18日,根据公司购股期权计划,按行使价每股28.45港元,授出499万份购股期权,惟须待承受人接纳方可作实。已授出的499万份购股期权中,169.2万份购
...[详细]
鹰君(00041.HK)宣布,于2021年3月18日,根据公司购股期权计划,按行使价每股28.45港元,授出499万份购股期权,惟须待承受人接纳方可作实。已授出的499万份购股期权中,169.2万份购
...[详细]最高省500?24期免息?618期间一加9 Pro福利拉满 -
 【手机中国行情】618想买手机?想买的还是旗舰机?还有分期免息的要求?嘿,还真巧了,一加9 Pro完全符合以上要求。在618期间,一加9 Pro最高立省500元,8GB+128GB版本立减200元,到
...[详细]
【手机中国行情】618想买手机?想买的还是旗舰机?还有分期免息的要求?嘿,还真巧了,一加9 Pro完全符合以上要求。在618期间,一加9 Pro最高立省500元,8GB+128GB版本立减200元,到
...[详细]对标ChatGPT!百度“文心一言”终于来了 还能写《三体》! -
 【CNMO新闻】此前,OpenAI旗下的ChatGPT引发了全球范围内关于人工智能的热潮,科幻爱好者们担心人类自此打开了潘多拉魔盒,而科技公司们则看到了其中蕴含的庞大可能和机遇。目前,国内的科技公司中
...[详细]
【CNMO新闻】此前,OpenAI旗下的ChatGPT引发了全球范围内关于人工智能的热潮,科幻爱好者们担心人类自此打开了潘多拉魔盒,而科技公司们则看到了其中蕴含的庞大可能和机遇。目前,国内的科技公司中
...[详细]最高降价1500元!荣耀晒出618购物攻略 这些产品香疯了 -
 【手机中国新闻】目前,2023年的618大促活动即将在5月31日晚间全面开启。而5月30日晚间,手机中国注意到,荣耀官方账号晒出了一份比较完整的“荣耀618嗨购大攻略”。据其中的信息,此次荣耀旗下的产
...[详细]
【手机中国新闻】目前,2023年的618大促活动即将在5月31日晚间全面开启。而5月30日晚间,手机中国注意到,荣耀官方账号晒出了一份比较完整的“荣耀618嗨购大攻略”。据其中的信息,此次荣耀旗下的产
...[详细]嘉里物流(00636.HK)因购股权获行使发行8万股 每股发行价10.2港元
 嘉里物流(00636.HK)公告,于2021年3月9日,因公司附属公司的董事行使购股权而发行8万股,每股发行价10.2港元。
...[详细]
嘉里物流(00636.HK)公告,于2021年3月9日,因公司附属公司的董事行使购股权而发行8万股,每股发行价10.2港元。
...[详细] 【智车派新闻】美国时间当地8月30日,智车派注意到,美国国家公路交通安全管理局披露,福特汽车公司宣布将召回部分配备单后轮和10.5英寸后车轴的2023款Super Duty F250和F350车型,涉
...[详细]
【智车派新闻】美国时间当地8月30日,智车派注意到,美国国家公路交通安全管理局披露,福特汽车公司宣布将召回部分配备单后轮和10.5英寸后车轴的2023款Super Duty F250和F350车型,涉
...[详细] 闲鱼多久自动确认收货 收货后可以退款退货吗?
闲鱼多久自动确认收货 收货后可以退款退货吗? 国产宝马X5在本届成都车展正式上市 售61.5万元起 -
国产宝马X5在本届成都车展正式上市 售61.5万元起 - 比亚迪海豹欧洲上市 起售价约35万元几乎为国内两倍 -
比亚迪海豹欧洲上市 起售价约35万元几乎为国内两倍 - 三星S23 Ultra新版本曝光 改用Exynos 2300处理器? -
三星S23 Ultra新版本曝光 改用Exynos 2300处理器? - 神火股份:3月23日融资净偿还37.10万元 当前融资余额为6.29亿元
神火股份:3月23日融资净偿还37.10万元 当前融资余额为6.29亿元
