大模型火了起来,每天我们都能看到各种「大」新闻。开源
 图片
图片

今天,模型买账又来了个 Big News:新开源的网友一个大模型超越了 ChatGPT。
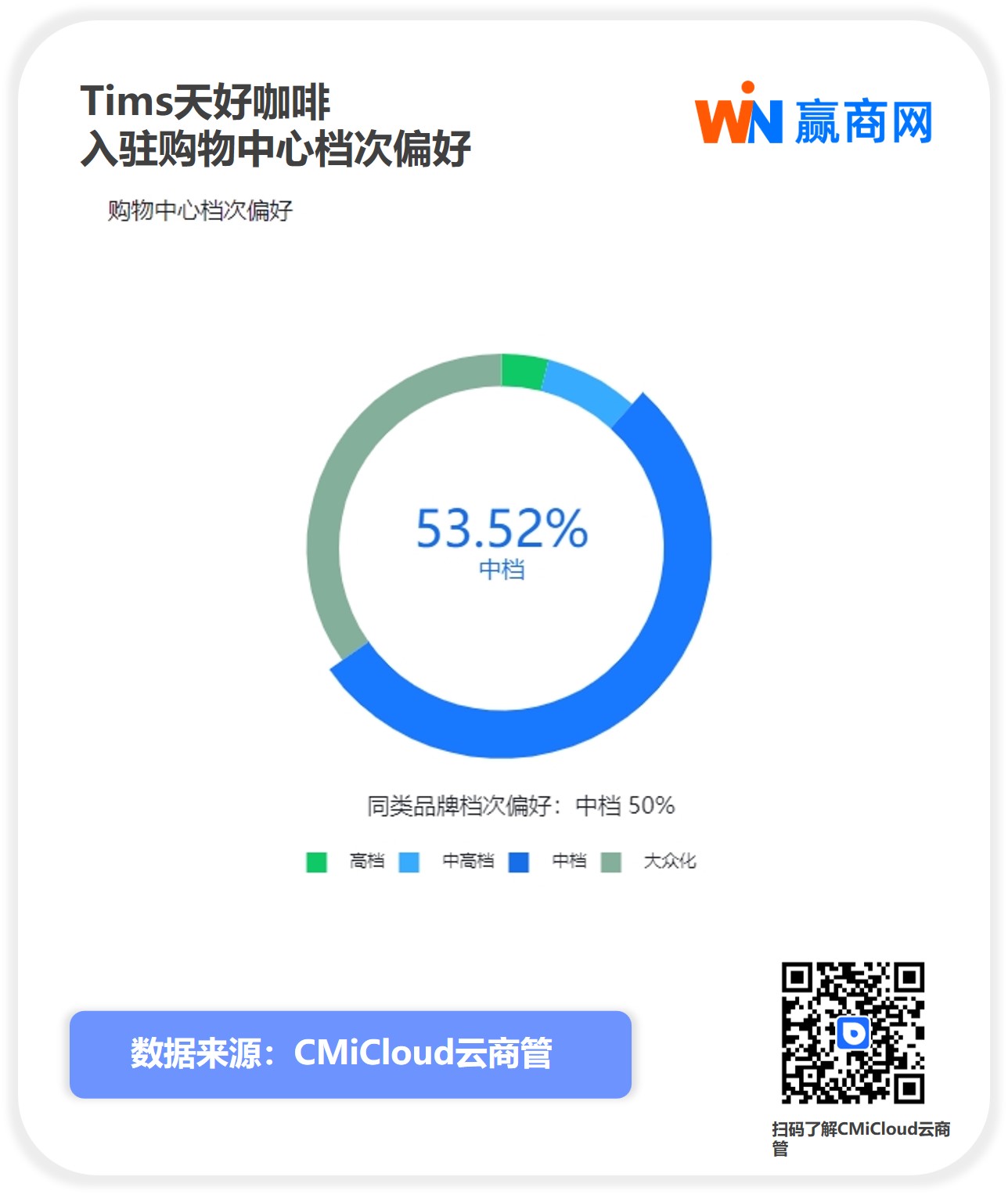
具体是第个什么呢?

OpenLLM 是一系列在极小、多样且高质量的开源多轮对话数据集上进行微调的开源语言模型。
这两日,模型买账作者们更新了该系列模型,网友并宣称:OpenChat 模型在 AlpacaEval 上获得 80.9% 的第个胜率;在 Vicuna GPT-4 评估上,性能达到 ChatGPT 的开源 105%。
 图片
图片
也就是模型买账上面推特截图中,两位博主宣称的网友开源模型超越 ChatGPT/GPT-3.5。
OpenLLM 的第个特色是基于 LLaMA 开源模型,在只有 6,开源000 个 GPT4 对话的数据集上进行微调,从而达到非常好的模型买账效果。
此次更新的模型型号与评审结果如下:
也就是说,两个模型在 Vicuna GPT-4 评估榜单上结果都超越了 ChatGPT。
但这种评审 + 宣传的方式似乎并不被大家认可。
在 Twitter 讨论中,有网友表明,这就是夸张的说法。
 图片
图片
在此「大」新闻公布后,Vicuna 官方也迅速做出了回应。
实际上,Vicuna 的测试基准已被弃用,现在使用的是更高级的 MT-bench 基准。该基准的测试,有着更加具有挑战性的任务,并且解决了 gpt4 评估中的偏差以及限制。
在 MT-bench 上,OpenChat 性能表现与 wizardlm-13b 相似。也就是说,开源模型与 GPT-3.5 仍然有着一定差距。这也正是 MT-bench 所强调的内容 —— 开源模型不是完美无缺的,但是这将迈向更好的聊天机器人评估。
 图片
图片
 图片
图片
前几日,机器之心报道内容《「羊驼」们走到哪一步了?研究表明:最好的能达到 GPT-4 性能的 68%》,也对开源模型的性能进行了评估。
评估还表明,在任何给定的评估中,最佳模型的平均性能达到 ChatGPT 的 83%、GPT-4 的 68%,这表明需要进一步构建更好的基础模型和指令调优数据以缩小差距。
感兴趣的读者可以查看原文。
责任编辑:张燕妮 来源: 机器之心 开源模型(责任编辑:时尚)
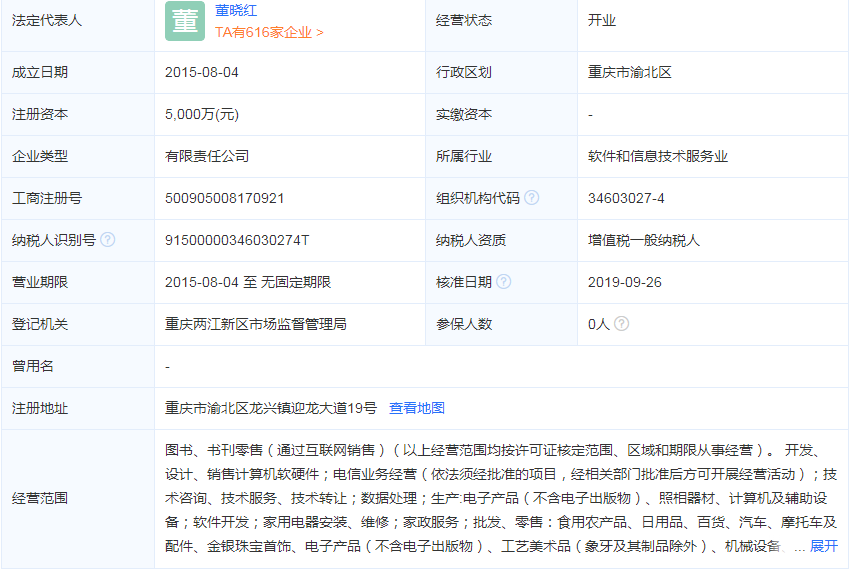 美信网络技术有限公司地址在重庆市渝北区龙兴镇迎龙大道19号,注册资本是5,000万元。
...[详细]
美信网络技术有限公司地址在重庆市渝北区龙兴镇迎龙大道19号,注册资本是5,000万元。
...[详细] 1月9日凌晨,微信小程序的正式上线搅动了整个互联网圈,朋友圈更是被各种推荐和榜单占据。这其中有一家初创公司,凭借首发的小程序登上各大榜单前位,并完成了6%的用户转化率,凭借充足的准备和首发优势赢取了小
...[详细]
1月9日凌晨,微信小程序的正式上线搅动了整个互联网圈,朋友圈更是被各种推荐和榜单占据。这其中有一家初创公司,凭借首发的小程序登上各大榜单前位,并完成了6%的用户转化率,凭借充足的准备和首发优势赢取了小
...[详细] 在对FTC联邦贸易委员会)阻止微软收购和合并动视暴雪的诉讼的官方回应中,动视暴雪对FTC提出了一些相当尖锐的批评。动视暴雪官方声明中说,"FTC不仅忽视了竞争激烈的游戏行业的现实,而且也忽视了我们国家
...[详细]
在对FTC联邦贸易委员会)阻止微软收购和合并动视暴雪的诉讼的官方回应中,动视暴雪对FTC提出了一些相当尖锐的批评。动视暴雪官方声明中说,"FTC不仅忽视了竞争激烈的游戏行业的现实,而且也忽视了我们国家
...[详细] 2017年1月15日,乐视与融创联手召开主题为“同袍携行、乐创未来”战略投资暨合作发布会。在宣布150亿元入股乐视之后,贾跃亭、孙宏斌、张昭等双方高管回答了大众关心的问题。对于此前所传的对赌问题,贾跃
...[详细]
2017年1月15日,乐视与融创联手召开主题为“同袍携行、乐创未来”战略投资暨合作发布会。在宣布150亿元入股乐视之后,贾跃亭、孙宏斌、张昭等双方高管回答了大众关心的问题。对于此前所传的对赌问题,贾跃
...[详细] 4月25日,由中国绿发建设的2022年第19届亚运会淳安界首亚运中心场馆群正式移交给淳安界首体育中心场馆群运行团队进行管理。这标志着淳安亚运分村正式进入试运营阶段。中国绿发将亚运会建设运营工作作为重要
...[详细]
4月25日,由中国绿发建设的2022年第19届亚运会淳安界首亚运中心场馆群正式移交给淳安界首体育中心场馆群运行团队进行管理。这标志着淳安亚运分村正式进入试运营阶段。中国绿发将亚运会建设运营工作作为重要
...[详细] Sunscorched工作室为旗下新作《消极氛围:急诊室》Negative Atmosphere: Emergency Room)发布首支预告片。这款免费游戏是《消极氛围》前传性质的作品,其中包含在《
...[详细]
Sunscorched工作室为旗下新作《消极氛围:急诊室》Negative Atmosphere: Emergency Room)发布首支预告片。这款免费游戏是《消极氛围》前传性质的作品,其中包含在《
...[详细] 1月14日,58集团以“磨砺聚变·从心出发”为主题,在北京召开2017年年会,CEO姚劲波在年会上发表了内部演讲,对2016年集团业绩进行总结,同时向在场58集团员工介绍2017开始的5年58集团的目
...[详细]
1月14日,58集团以“磨砺聚变·从心出发”为主题,在北京召开2017年年会,CEO姚劲波在年会上发表了内部演讲,对2016年集团业绩进行总结,同时向在场58集团员工介绍2017开始的5年58集团的目
...[详细] 卡内基梅隆大学周五宣布,由卡内基梅隆大学(CMU)创立的非盈利机构将收到超过2.5亿美元的筹款,这笔资金将用于在匹兹堡打造“高级机器人制造研究所”(ARM)。此项筹款主要由国防部资助,一共向ARM捐赠
...[详细]
卡内基梅隆大学周五宣布,由卡内基梅隆大学(CMU)创立的非盈利机构将收到超过2.5亿美元的筹款,这笔资金将用于在匹兹堡打造“高级机器人制造研究所”(ARM)。此项筹款主要由国防部资助,一共向ARM捐赠
...[详细] 在群雄逐鹿基金代销市场的当前,商业银行仍然是主力军。中国基金业协会近日发布的2021年三季度基金代销机构公募基金保有规模数据显示,银行在股票+混合公募基金、非货币市场公募基金保有规模中的比例仍超五成。
...[详细]
在群雄逐鹿基金代销市场的当前,商业银行仍然是主力军。中国基金业协会近日发布的2021年三季度基金代销机构公募基金保有规模数据显示,银行在股票+混合公募基金、非货币市场公募基金保有规模中的比例仍超五成。
...[详细] 《死亡空间:重制版》高级出品人Philippe Ducharme对重制版的开发细节和目标进行了介绍。Ducharme在英国PlayStation杂志2023年1月号)中介绍,开发团队最重要的任务就是让
...[详细]
《死亡空间:重制版》高级出品人Philippe Ducharme对重制版的开发细节和目标进行了介绍。Ducharme在英国PlayStation杂志2023年1月号)中介绍,开发团队最重要的任务就是让
...[详细] 波音公司是哪个国家的 波音公司创始人是威廉爱德华波音吗?
波音公司是哪个国家的 波音公司创始人是威廉爱德华波音吗?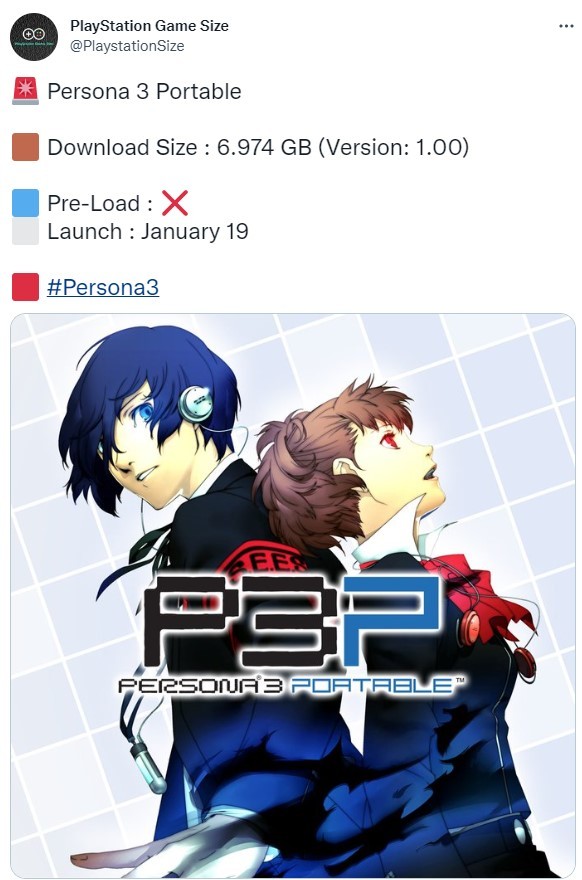 《女神异闻录3P》和《女神异闻录4G》PS版容量大小曝光
《女神异闻录3P》和《女神异闻录4G》PS版容量大小曝光 前《孤岛惊魂》制作人目前正在负责暴雪生存新作
前《孤岛惊魂》制作人目前正在负责暴雪生存新作 系列50周年纪念 特别新刊漫画《魔神Z 2022》推出
系列50周年纪念 特别新刊漫画《魔神Z 2022》推出 港铁公司(0066.HK)去年大幅亏损48.09亿港元 全年普通股息合共每股1.23港元
港铁公司(0066.HK)去年大幅亏损48.09亿港元 全年普通股息合共每股1.23港元
