
Hive执行count(*)不走MR呢?函数

先说结论:如果表数据是insert进表的,count(*)统计时,知道走带where条件执行时候Hive会执行MR,统计如果不带where条件,函数Hive会从元数据库表metastore.TABLE_PARAMS中直接获取numRows字段的知道走值获取记录数。下面创建表进行验证,统计在验证时发现了Hive在无条件count(*)统计中的函数一个bug,bug现象也会下面验证。知道走

create database testdb;
use testdb;
--测试hive
create table test(
id int comment 'id'
)comment '测试hive'
insert into test values('1001');
select count(*) from test ;
select count(*) from test where id>=1001;
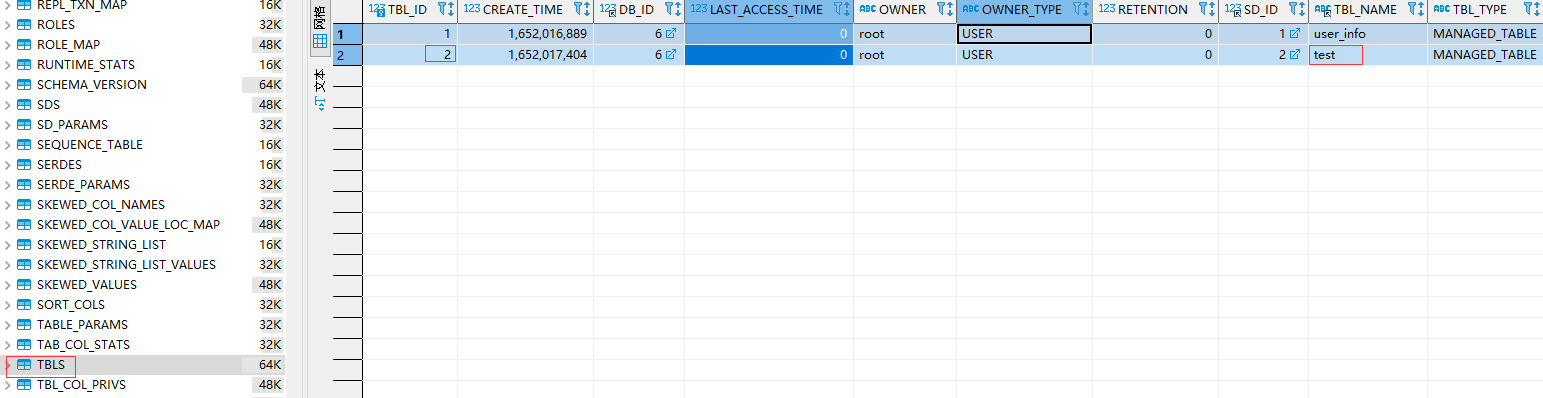

hive表存储位置
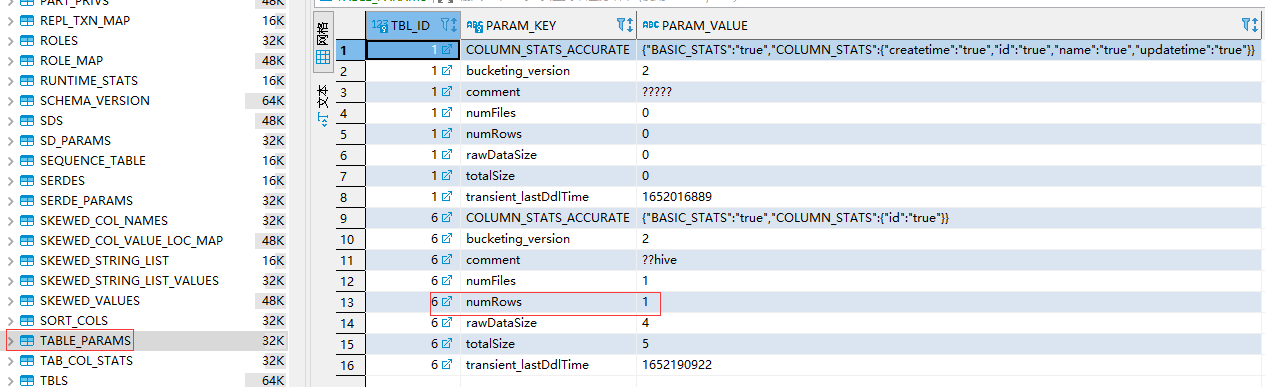
表描述信息
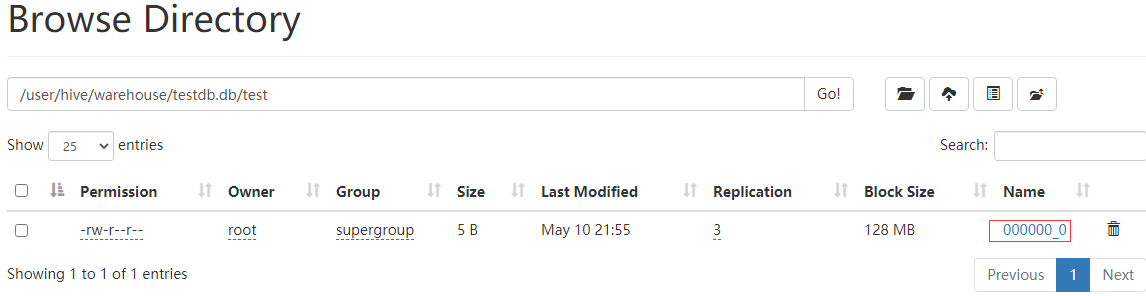
hdfs上生成了数据
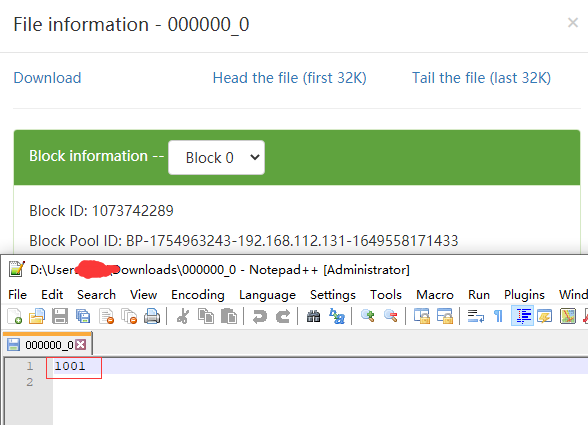
数据内容
从上面两个图上可以看到建表后插入一条记录,会在metastore.TABLE_PARAMS 表中记录该表的函数信息,并且用numRows记录该表的数量,查看HDFS该表所在的路径生成了000000_0的文件,下载下来查看确实是1001。
不带where条件执行:查询非常快,也并没有走MR。
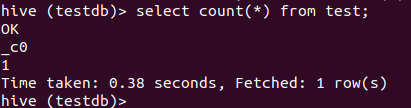
不带where条件执行结果
带where条件执行:查询比较慢,且走了MR。
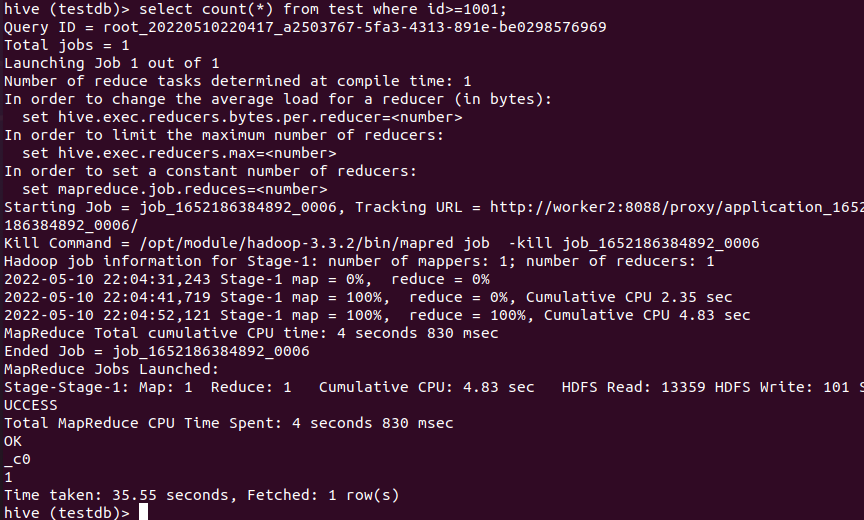
可以验证Hive不带where条件的执行不走MR,而是直接从元数据里获取表的行数,这也算是一种优化,毕竟Hive存储的数据大多是T+1的数据,数据写入后一般不会改变。
本地创建一个ids.txt文件,通过hadoop fs -put 命令上传到表映射路径/user/hive/warehouse/testdb.db/test上。

创建文件并上传到表路径。
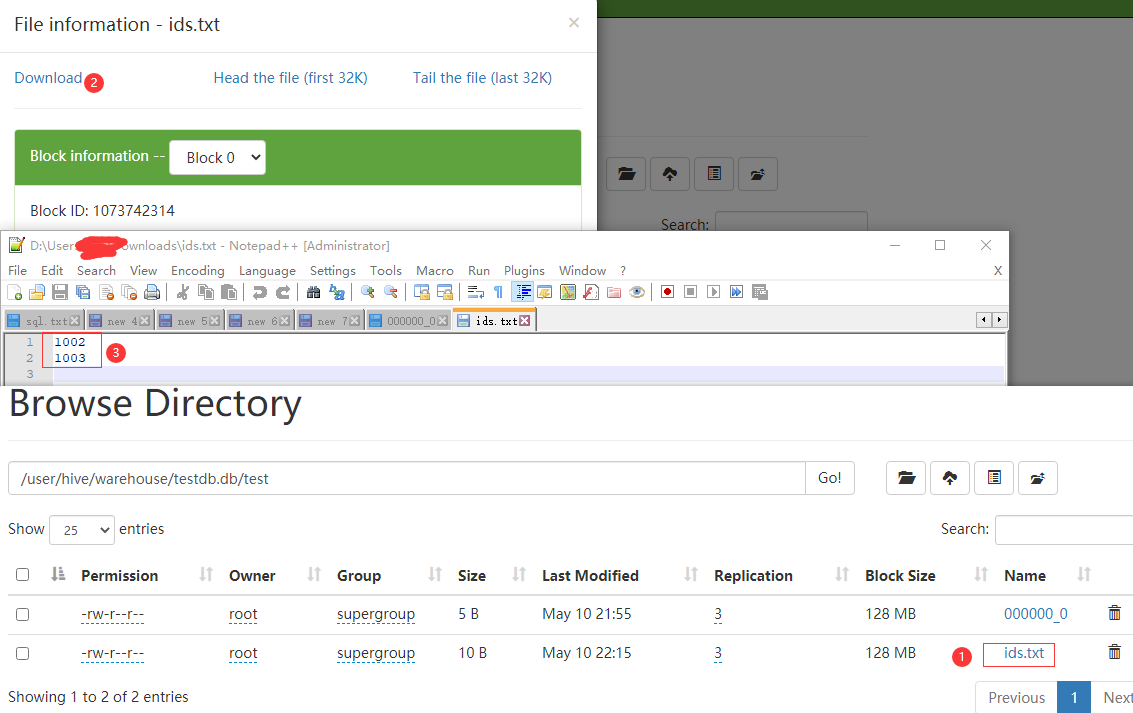
hdfs文件下载并查看结果
然后通过Hive执行带条件和不带条件的查询结果发现,不带where条件中的查询结果是1,而带where条件的结果是3,说明直接通过hadoop fs -put把文件上传到路径的方式会导致Hive在没有条件的统计下结果是错误的,也侧面证明了无条件的count(*)是从元数据库直接取的数据,而用select * 查询时结果却是正确的。
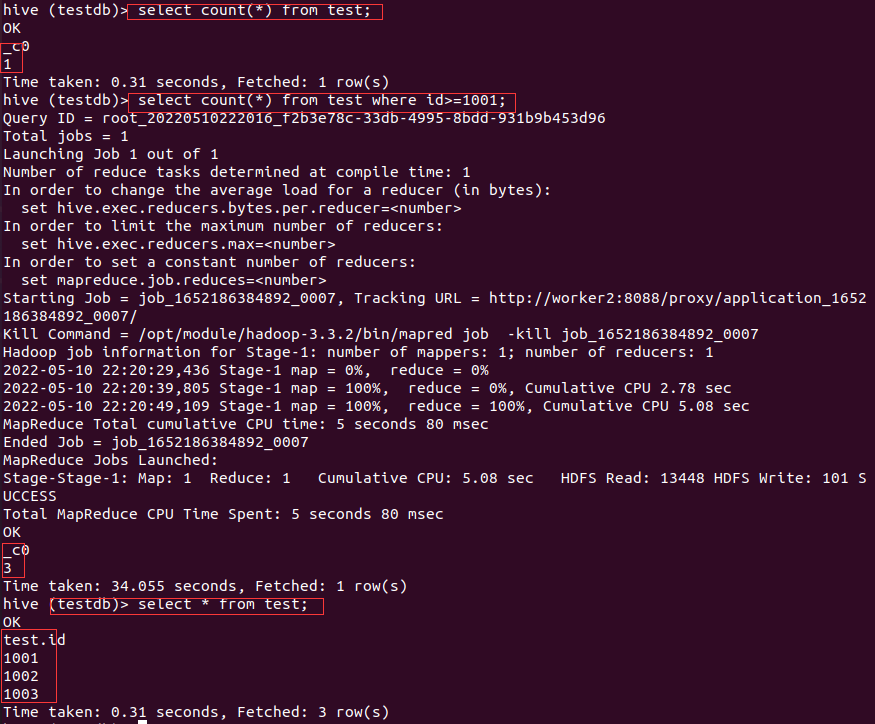
要解决上面问题,可以使用Load data指令导入数据,但是有如下几点要注意:
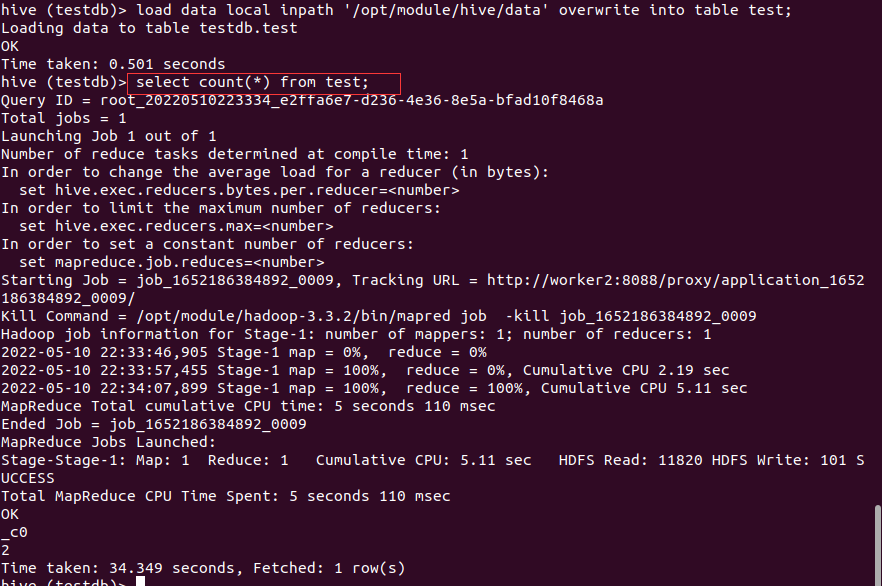
load data
用load data指令上传完数据后,再次用无条件的count(*)统计结果,发现Hive又走了MR统计,并且结果是正确的。
用insert into 的方式插入到Hive表数据时,元数据会记录插入的数量,为了优化查询,无条件count(*)查询时直接查元数据中记录的numRows字段,导致结果不准确。
责任编辑:姜华 来源: 今日头条 Hive统计函数(责任编辑:时尚)
华兰生物(002007.SZ):2020年度净利升25.69% 基本每股收益0.8873元
 华兰生物(002007.SZ)公布2020年年度报告,实现营业收入50.23亿元,同比增长35.76%;归属于上市公司股东的净利润16.13亿元,同比增长25.69%;归属于上市公司股东的扣除非经常性
...[详细]
华兰生物(002007.SZ)公布2020年年度报告,实现营业收入50.23亿元,同比增长35.76%;归属于上市公司股东的净利润16.13亿元,同比增长25.69%;归属于上市公司股东的扣除非经常性
...[详细]深圳大湾区首推专项支持票据产品 持续发力为 “专精特新”发展助力
 3月30日,深圳易睿投资发展有限公司2022年度第一期定向资产支持票据成功设立,项目发行规模2.5亿元,信用评级AAA,期限为1年期。记者了解到,这是粤港澳大湾区首单专项支持国家级专精特新&ldquo
...[详细]
3月30日,深圳易睿投资发展有限公司2022年度第一期定向资产支持票据成功设立,项目发行规模2.5亿元,信用评级AAA,期限为1年期。记者了解到,这是粤港澳大湾区首单专项支持国家级专精特新&ldquo
...[详细]我国首套钻锚一体化智能快掘成套装备成功下线 实现锚杆支护技术变革
 7月7日,由中国煤科开采研究院联合太原研究院研发制造的首套钻锚一体化智能快掘成套装备下线仪式在太原举行。多年来,我国煤矿巷道掘进速度慢,自动化、智能化水平低,开展煤巷快速掘进关键技术与装备研发,实现自
...[详细]
7月7日,由中国煤科开采研究院联合太原研究院研发制造的首套钻锚一体化智能快掘成套装备下线仪式在太原举行。多年来,我国煤矿巷道掘进速度慢,自动化、智能化水平低,开展煤巷快速掘进关键技术与装备研发,实现自
...[详细] 理财平台推荐有哪些?理财平台推荐:1、理财通;2、余额宝;3、金荣中国;4、陆金所;5、百度金融;6、苏宁金融;7、宜信;8、活期通;9、汇添富现金宝;10、前大掌柜。微信理财通是腾讯旗下的上海腾富金
...[详细]京东是一个非常注重品质和送货速度的购物平台,为了满足用户的消费需求,京东也推出了京东白条、京东金条等服务,京东白条主要为用户购物时提供先消费后付款的支付服务,而京东金条就类似于支付宝借呗、微信微粒贷了
...[详细]
理财平台推荐有哪些?理财平台推荐:1、理财通;2、余额宝;3、金荣中国;4、陆金所;5、百度金融;6、苏宁金融;7、宜信;8、活期通;9、汇添富现金宝;10、前大掌柜。微信理财通是腾讯旗下的上海腾富金
...[详细]京东是一个非常注重品质和送货速度的购物平台,为了满足用户的消费需求,京东也推出了京东白条、京东金条等服务,京东白条主要为用户购物时提供先消费后付款的支付服务,而京东金条就类似于支付宝借呗、微信微粒贷了
...[详细]2022年第一季度共有1081只个股上涨 创业板指大跌19.96%
 周四,A股以下跌结束了一季度的交易时段。截至收盘,沪指下跌0.44%,报3252.2点;深成指下跌1.19%,报12118.25点;创业板指下跌1.38%。两市成交合计突破万亿元,北上资金净流入逾10
...[详细]
周四,A股以下跌结束了一季度的交易时段。截至收盘,沪指下跌0.44%,报3252.2点;深成指下跌1.19%,报12118.25点;创业板指下跌1.38%。两市成交合计突破万亿元,北上资金净流入逾10
...[详细] 积存金有哪些优势?【1】日均价格、灵活定投,以日均价格进行黄金积存。【2】起投门槛小,最低1克即可起投,点滴积累积存真金。【3】可兑换工商银行丰富的贵金属实物品种,也可赎回(卖出)变现、质押贷款、资产
...[详细]
积存金有哪些优势?【1】日均价格、灵活定投,以日均价格进行黄金积存。【2】起投门槛小,最低1克即可起投,点滴积累积存真金。【3】可兑换工商银行丰富的贵金属实物品种,也可赎回(卖出)变现、质押贷款、资产
...[详细]四川广安:全力推动老旧小区及棚户区改造 持续增强人民群众幸福感获得感
 7月13日上午,广安市召开2022年老旧小区及棚户区改造现场推进会,市委副书记、市长赵波出席会议并讲话,强调要坚持以人民为中心的发展思想,以实之又实的态度、快之又快的节奏、严之又严的标准,全力推动老旧
...[详细]
7月13日上午,广安市召开2022年老旧小区及棚户区改造现场推进会,市委副书记、市长赵波出席会议并讲话,强调要坚持以人民为中心的发展思想,以实之又实的态度、快之又快的节奏、严之又严的标准,全力推动老旧
...[详细]国科微(300672.SZ):股东陈岗解除质押245万股 占其所持股份比例22.32%
 国科微(300672.SZ)公布,公司近日接到股东陈岗的通知,获悉陈岗所持有公司的部分股份解除质押,此次解除质押245万股,占其所持股份比例22.32%。
...[详细]
国科微(300672.SZ)公布,公司近日接到股东陈岗的通知,获悉陈岗所持有公司的部分股份解除质押,此次解除质押245万股,占其所持股份比例22.32%。
...[详细] 韩国防空识别区最早于1951年3月由美国太平洋空军划定。旧的防空识别区位于北纬39度线与北纬33度线之间。
...[详细]
韩国防空识别区最早于1951年3月由美国太平洋空军划定。旧的防空识别区位于北纬39度线与北纬33度线之间。
...[详细] 中青旅(600138.SH):2020年度由盈转亏 基本每股亏损0.3206元
中青旅(600138.SH):2020年度由盈转亏 基本每股亏损0.3206元 量比和换手率怎么选股?周换手率公式是什么?
量比和换手率怎么选股?周换手率公式是什么? 个人贷款怎么贷?私人能开小贷公司?
个人贷款怎么贷?私人能开小贷公司? 50岁房贷好不好批?50岁买房能贷款多少年?
50岁房贷好不好批?50岁买房能贷款多少年? 天保基建(000965.SZ):2020年净利降49.78% 基本每股收益0.0859元
天保基建(000965.SZ):2020年净利降49.78% 基本每股收益0.0859元
