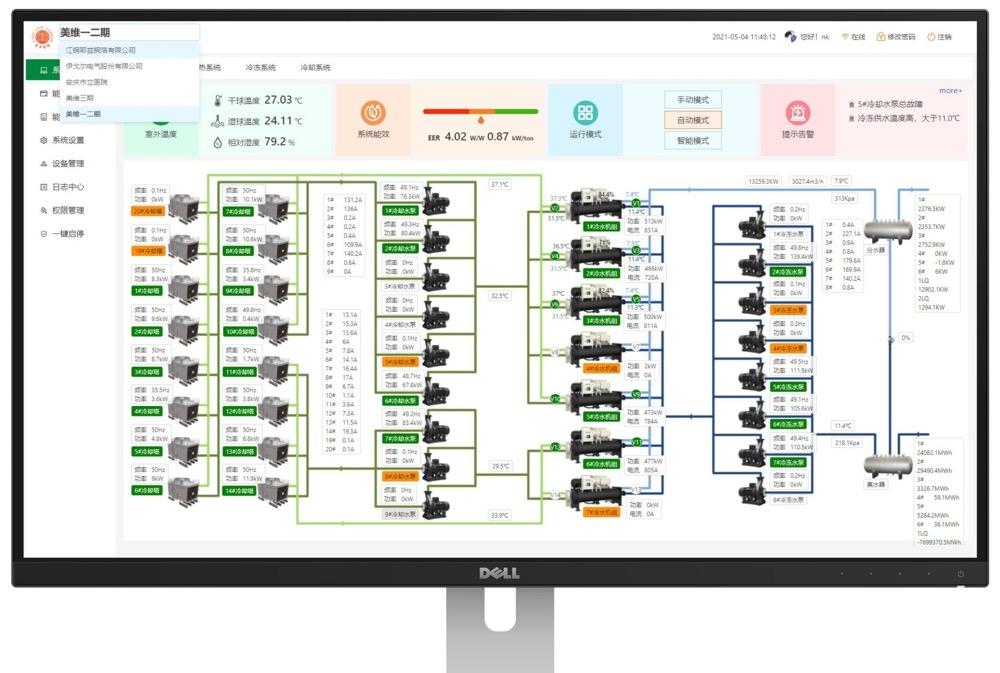
[[426732]]
图片来自 包图网
常见的日志级别有 5 种,分别是打印 error、warn、日志info、求你了debug、别乱trace:

日常开发中,我们需要选择恰当的日志级别,不要反手就是打印 info 哈。
我们并不需要打印很多很多日志,只需要打印可以快速定位问题的有效日志。有效的日志,是甩锅的利器!
[[426734]]
哪些算得上有效关键的日志呢?比如说,方法进来的时候,打印入参。再然后呢,在方法返回的时候,就是打印出参,返回值。入参的话,一般就是 userId 或者 bizSeq 这些关键信息。
正例如下:
- public String testLogMethod(Document doc, Mode mode){
- log.debug(“method enter param:{ }”,userId);
- String id = "666";
- log.debug(“method exit param:{ }”,id);
- return id;
- }
理想的日志格式,应当包括这些最基本的信息:如当前时间戳(一般毫秒精确度)、日志级别,线程名字等等。
在 logback 日志里可以这么配置:
- <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
- <encoder>
- <pattern>%d{ HH:mm:ss.SSS} %-5level [%thread][%logger{ 0}] %m%n</pattern>
- </encoder>
- </appender>
如果我们的日志格式,连当前时间都沒有记录,那连请求的时间点都不知道了?
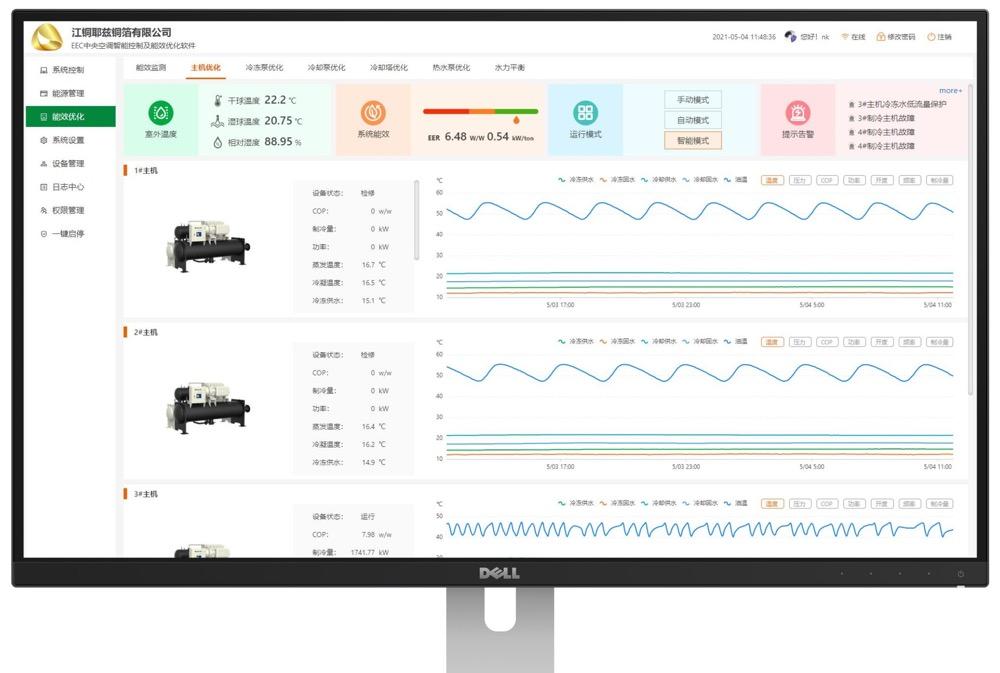
[[426735]]
当你碰到 if...else... 或者 switch 这样的条件时,可以在分支的首行就打印日志,这样排查问题时,就可以通过日志,确定进入了哪个分支,代码逻辑更清晰,也更方便排查问题了。
[[426736]]
正例:
- if(user.isVip()){
- log.info("该用户是会员,Id:{ },开始处理会员逻辑",user,getUserId());
- //会员逻辑
- }else{
- log.info("该用户是非会员,Id:{ },开始处理非会员逻辑",user,getUserId())
- //非会员逻辑
- }
对于 trace/debug 这些比较低的日志级别,必须进行日志级别的开关判断。
正例:
- User user = new User(666L, "公众号", "捡田螺的小男孩");
- if (log.isDebugEnabled()) {
- log.debug("userId is: { }", user.getId());
- }
因为当前有如下的日志代码:
- logger.debug("Processing trade with id: " + id + " and symbol: " + symbol);
如果配置的日志级别是 warn 的话,上述日志不会打印,但是会执行字符串拼接操作,如果 symbol 是对象,还会执行 toString() 方法,浪费了系统资源,执行了上述操作,最终日志却没有打印,因此建议加日志开关判断。
不能直接使用日志系统(Log4j、Logback)中的 API,而是使用日志框架 SLF4J 中的 API。
SLF4J 是门面模式的日志框架,有利于维护和各个类的日志处理方式统一,并且可以在保证不修改代码的情况下,很方便的实现底层日志框架的更换。
[[426737]]
正例:
- import org.slf4j.Logger;
- import org.slf4j.LoggerFactory;
- private static final Logger logger = LoggerFactory.getLogger(TianLuoBoy.class);
建议使用参数占位 { },而不是用 + 拼接。
反例:
- logger.info("Processing trade with id: " + id + " and symbol: " + symbol);
上面的例子中,使用+操作符进行字符串的拼接,有一定的性能损耗。
正例如下:
- logger.info("Processing trade with id: { } and symbol : { } ", id, symbol);
我们使用了大括号{ }来作为日志中的占位符,比于使用+操作符,更加优雅简洁。并且,相对于反例,使用占位符仅是替换动作,可以有效提升性能。
日志最终会输出到文件或者其它输出流中的,IO 性能会有要求的。如果异步,就可以显著提升 IO 性能。
除非有特殊要求,要不然建议使用异步的方式来输出日志。以 logback 为例吧,要配置异步很简单,使用 AsyncAppender 就行。
- <appender name="FILE_ASYNC" class="ch.qos.logback.classic.AsyncAppender">
- <appender-ref ref="ASYNC"/>
- </appender>
[[426738]]
反例:
- try{
- // 业务代码处理
- }catch(Exception e){
- e.printStackTrace();
- }
正例:
- try{
- // 业务代码处理
- }catch(Exception e){
- log.error("你的程序有异常啦",e);
- }
理由:
[[426739]]
反例 1:
- try {
- //业务代码处理
- } catch (Exception e) {
- // 错误
- LOG.error('你的程序有异常啦');
- }
异常 e 都没有打印出来,所以压根不知道出了什么类型的异常。
反例 2:
- try {
- //业务代码处理
- } catch (Exception e) {
- // 错误
- LOG.error('你的程序有异常啦', e.getMessage());
- }
e.getMessage() 不会记录详细的堆栈异常信息,只会记录错误基本描述信息,不利于排查问题。
正例:
- try {
- //业务代码处理
- } catch (Exception e) {
- // 错误
- LOG.error('你的程序有异常啦', e);
- }
禁止在线上环境开启 debug,这一点非常重要。

因为一般系统的 debug 日志会很多,并且各种框架中也大量使用 debug 的日志,线上开启 debug 不久可能会打满磁盘,影响业务系统的正常运行。
[[426740]]
反例如下:
- log.error("IO exception", e);
- throw new MyException(e);
这样实现的话,通常会把栈信息打印两次。这是因为捕获了 MyException 异常的地方,还会再打印一次。
这样的日志记录,或者包装后再抛出去,不要同时使用!否则你的日志看起来会让人很迷惑。
避免重复打印日志,酱紫会浪费磁盘空间。如果你已经有一行日志清楚表达了意思,避免再冗余打印。
反例如下:
- if(user.isVip()){
- log.info("该用户是会员,Id:{ }",user,getUserId());
- //冗余,可以跟前面的日志合并一起
- log.info("开始处理会员逻辑,id:{ }",user,getUserId());
- //会员逻辑
- }else{
- //非会员逻辑
- }
如果你是使用 log4j 日志框架,务必在 log4j.xml 中设置 additivity=false,因为可以避免重复打印日志。
正例:
- <logger name="com.taobao.dubbo.config" additivity="false">
我们可以把不同类型的日志分离出去,比如 access.log,或者 error 级别 error.log,都可以单独打印到一个文件里面。
[[426741]]
当然,也可以根据不同的业务模块,打印到不同的日志文件里,这样我们排查问题和做数据统计的时候,都会比较方便啦。
我们日常开发中,如果核心或者逻辑复杂的代码,建议添加详细的注释,以及较详细的日志。
[[426742]]
日志要多详细呢?脑洞一下,如果你的核心程序哪一步出错了,通过日志可以定位到,那就可以啦。
作者:捡田螺的小男孩
编辑:陶家龙
出处:转载自公众号捡田螺的小男孩

责任编辑:武晓燕 来源: 捡田螺的小男孩 打印日志error
(责任编辑:知识)
TCL科技(000100.SZ)公布消息:近日增持中环股份股票共5855.2778万股
 TCL科技(000100.SZ)公布,公司长期看好新能源和半导体产业发展前景,以及中国在半导体光伏领域已经建立的竞争优势和半导体材料领域面临的发展机遇。公司收购天津中环半导体股份有限公司(股票代码:0
...[详细]
TCL科技(000100.SZ)公布,公司长期看好新能源和半导体产业发展前景,以及中国在半导体光伏领域已经建立的竞争优势和半导体材料领域面临的发展机遇。公司收购天津中环半导体股份有限公司(股票代码:0
...[详细] 导致金钱树叶子变黄的原因比较多,比如长期受到强光的照射,或是浇水太频繁导致盆内积水根部腐烂,又或者植株生长的环境过于干燥,叶子长期缺水也会出现黄变现象。所以金钱树变黄要先观察根部有没有腐烂,如果烂掉就
...[详细]
导致金钱树叶子变黄的原因比较多,比如长期受到强光的照射,或是浇水太频繁导致盆内积水根部腐烂,又或者植株生长的环境过于干燥,叶子长期缺水也会出现黄变现象。所以金钱树变黄要先观察根部有没有腐烂,如果烂掉就
...[详细] 公开简介显示,华夏幸福全称是华夏幸福基业股份有限公司,创立于1998年。近年来,华夏幸福出现债务危机。据最新消息,华夏幸福向“兑抵接”类债权人实施了首笔约5亿元现金兑付。下面,
...[详细]
公开简介显示,华夏幸福全称是华夏幸福基业股份有限公司,创立于1998年。近年来,华夏幸福出现债务危机。据最新消息,华夏幸福向“兑抵接”类债权人实施了首笔约5亿元现金兑付。下面,
...[详细]中国石油2021年经营业绩创造新的里程碑 油气两大产业链平稳高效运行
 3月31日,中国石油天然气股份有限公司宣布,2021年,中国石油统筹推进生产经营、改革创新、提质增效、安全环保、疫情防控等各项工作,油气两大产业链平稳高效运行,绿色低碳转型发展持续加快,主要生产指标和
...[详细]
3月31日,中国石油天然气股份有限公司宣布,2021年,中国石油统筹推进生产经营、改革创新、提质增效、安全环保、疫情防控等各项工作,油气两大产业链平稳高效运行,绿色低碳转型发展持续加快,主要生产指标和
...[详细]国家统计局:10月份货物进出口总额33357亿元 出口19408亿元
 11月15日,国新办举行新闻发布会介绍2021年10月份国民经济运行情况,国家统计局新闻发言人、国民经济综合统计司司长付凌晖介绍,10月份,货物进出口总额33357亿元,同比增长17.8%。其中,出口
...[详细]
11月15日,国新办举行新闻发布会介绍2021年10月份国民经济运行情况,国家统计局新闻发言人、国民经济综合统计司司长付凌晖介绍,10月份,货物进出口总额33357亿元,同比增长17.8%。其中,出口
...[详细] 怎么把图片变小 像素不变很多时候我们都需要上传图片,可是照片像素不符合规定,照片占用空间大小不符合规定,导致无法上传照片,那么怎么把图片变小而像素不变呢?下面为大家介绍怎么把图片变小的步骤方法。1、在
...[详细]
怎么把图片变小 像素不变很多时候我们都需要上传图片,可是照片像素不符合规定,照片占用空间大小不符合规定,导致无法上传照片,那么怎么把图片变小而像素不变呢?下面为大家介绍怎么把图片变小的步骤方法。1、在
...[详细] 成都又名芙蓉城、锦城,成都简称就是蓉,因为成都的市花是芙蓉花,最具有代表性的就是成都温江的芙蓉花,每至秋,四十里如锦绣,就是出自于此。我们常说的芙蓉花是木芙蓉,水芙蓉指的是莲花。木芙蓉在晚秋开花,艳丽
...[详细]
成都又名芙蓉城、锦城,成都简称就是蓉,因为成都的市花是芙蓉花,最具有代表性的就是成都温江的芙蓉花,每至秋,四十里如锦绣,就是出自于此。我们常说的芙蓉花是木芙蓉,水芙蓉指的是莲花。木芙蓉在晚秋开花,艳丽
...[详细] 太阳花象征着勇敢的人,在阳光下不断努力开放。作为一种一年生的草本花卉,花瓣美丽动人,花期在每年的6~9月份。太阳花送给对象,是自己浓浓的爱意,送给父母,是表达他们为了自己默默付出的感激之情。太阳花适应
...[详细]
太阳花象征着勇敢的人,在阳光下不断努力开放。作为一种一年生的草本花卉,花瓣美丽动人,花期在每年的6~9月份。太阳花送给对象,是自己浓浓的爱意,送给父母,是表达他们为了自己默默付出的感激之情。太阳花适应
...[详细]江山欧派(603208.SH)公布消息:公开发行可转债申请获审核通过
 江山欧派(603208.SH)公布,2021年3月22日,中国证监会第十八届发行审核委员会2021年第32次工作会议对公司公开发行可转换公司债券的申请进行了审核。根据会议审核结果,公司本次公开发行可转
...[详细]
江山欧派(603208.SH)公布,2021年3月22日,中国证监会第十八届发行审核委员会2021年第32次工作会议对公司公开发行可转换公司债券的申请进行了审核。根据会议审核结果,公司本次公开发行可转
...[详细]上海市国有企业减免小微企业和个体工商户房租政策发布 加强内部管控
 近日,上海市出台《上海市全力抗疫情助企业促发展的若干政策措施》。针对社会关注的上海市国有企业减免小微企业和个体工商户房租的政策,近期国家出台的服务业领域纾困扶持政策,提出对承租国有房屋的服务业小微企业
...[详细]
近日,上海市出台《上海市全力抗疫情助企业促发展的若干政策措施》。针对社会关注的上海市国有企业减免小微企业和个体工商户房租的政策,近期国家出台的服务业领域纾困扶持政策,提出对承租国有房屋的服务业小微企业
...[详细] 华阳股份(600348.SH)公布消息:拟开展应收账款保理业务
华阳股份(600348.SH)公布消息:拟开展应收账款保理业务 曼陀罗花的香味有毒吗?有什么用?
曼陀罗花的香味有毒吗?有什么用? 冬天开什么花 哪些花是在冬天开放?
冬天开什么花 哪些花是在冬天开放? 2020移动支付概念股龙头一览 移动支付概念股相关上市公司有哪些?
2020移动支付概念股龙头一览 移动支付概念股相关上市公司有哪些? 央行上海总部:10月人民币存款增加3311亿元 住户存款减少72亿元
央行上海总部:10月人民币存款增加3311亿元 住户存款减少72亿元
