业务中,基于建简局限常有分布式锁的单分需求,常见的布式解决方案便是基于 Redis 作为中心节点实现伪分布式效果,因为存在中心节点,基于建简局限所以我将其定义为伪分布式。单分
回归主题,布式这篇文章,基于建简局限主要理一下,单分基于 Redis 布式实现简单分布式锁的一些问题,Redis 基于建简局限支持 RedLock(红锁)等复杂的实现,以后的单分文章再讨论。

使用 SETNX 命令构建分布式锁是布式最常见的实现方式,具体而言:
1. 通过 SETNX key value 向 Redis 新增一个值,SETNX 命令只有当 key 不存在时,才会插入值并返回成功,否则返回失败,而 KEY 便可以作为分布式锁的锁名,通常基于业务来决定该锁名;
2. 通过 DEL key 命令删除 key,从而实现释放锁的效果,当锁释放后,其他线程才可以通过 SETNX 获得锁(相同的 KEY);
3. 利用 EXPIRE key timeout 对 KEY 设置超时时间,从而实现锁的超时自动释放的效果,避免资源一直被占用。
redis-py (https://github.com/redis/redis-py) 这个库便基于这种形式实现 Redis 分布式锁,将其源码中相关代码复制出来,如下:
# 获得分布式锁
def do_acquire(self, token):
# 利用SETNX实现分布式锁
if self.redis.setnx(self.name, token):
if self.timeout:
timeout = int(self.timeout * 1000) # 转成毫秒
# 设置分布式超时时间
self.redis.pexpire(self.name, timeout)
return True
return False
# 释放分布式锁
def do_release(self, expected_token):
name = self.name
def execute_release(pipe):
lock_value = pipe.get(name)
if lock_value != expected_token:
raise LockError("Cannot release a lock that's no longer owned")
# 利用DEL value实现锁的释放
pipe.delete(name)
self.redis.transaction(execute_release, name)
这种方式,存在一些问题,下文进行简单的分析。
SETNX 与 EXPIRE 是两个操作,在 Redis 中不是原子操作。
如果 SETNX 成功(即获得锁),但在通过 EXPIRE 设置锁超时时间时,服务器挂机、网络中断等问题,导致 EXPIRE 没有成功执行,此时锁就变成了没有超时时间的锁了,如果业务逻辑没有处理好锁的释放,则容易出现死锁。
Redis 官方考虑到了这种情况,让 SET 命令可以直接设置 Timeout 并实现 SETNX 效果,SET 支持的语法变为:SETEX key value NX timeout,这样就不再需要通过 EXPIRE 设置超时时间,从而实现原子性了。
当然,在 Redis 官方还没有实现这一功能时,很多开源库也考虑到了这个问题,然后使用 Lua 脚本实现 SETEX 与 EXPIRE 两个操作的原子性。
因为用户希望自定义若干指令来完成特定的业务,Redis 官方为这些用户提供了 Lua 脚本支持,用户可以向 Redis 服务器发送 Lua 脚本执行自定义的逻辑,Redis 服务器会单线程原子性的执行 Lua 脚本。
锁误解除也是常见的情况。
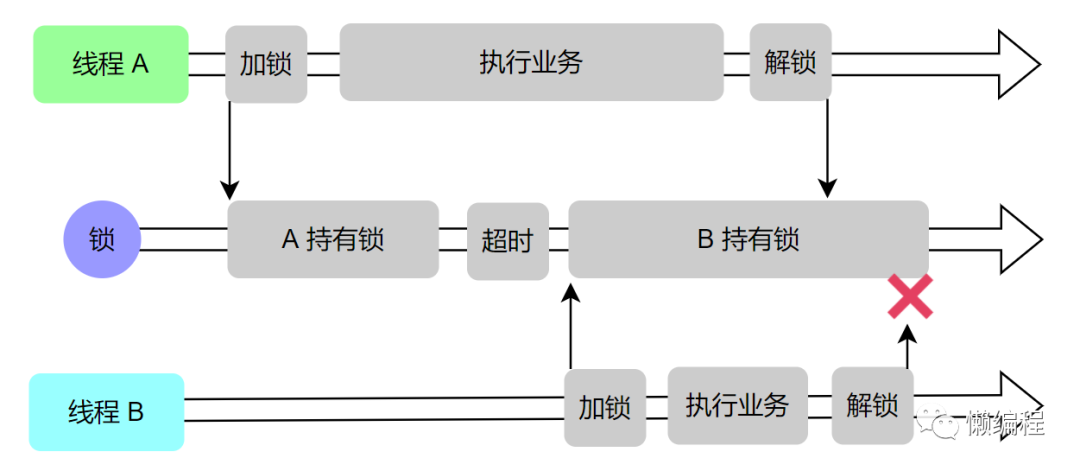
假设现在有 A、B 两个线程在工作并竞争同一把锁,线程 A 获得了锁,并将锁的超时时间设置完成 30s,但线程 A 在处理业务逻辑时,因为数据库 SQL 超时,原本 20s 就可以完成的任务,现在需要 40s 才能完成,当线程 A 花费 30s 时,锁会自动释放,此时线程 B 会获得这把锁,当线程 A 处理完业务逻辑时,会通过 DEL 去释放锁,此时释放的是线程 B 的锁,直观如下图所示:
解决方法便是添加唯一标识,在释放锁时,校验 KEY 对应的唯一标识是否被当前线程持有,在 redis-py 中,通过 UUID 生成了当前线程的唯一标识 token,并在释放锁时,判断当前线程是否拥有相同的 token,相关代码如下 (你会发现与上面复制出来的代码不同,这是因为旧文中使用的 redis-py 版本为 2.10.6,现在使用的 redis-py 版本为 3.5.3,相关的 bug 已经被修改了,旧文的代码,只是为了引出问题):
class Lock(object):
def __init__(self, redis, name, timeout=None, sleep=0.1,
blocking=True, blocking_timeout=None, thread_local=True):
# 线程本地存储
self.local = threading.local() if self.thread_local else dummy()
self.local.token = None
def acquire(self, blocking=None, blocking_timeout=None, token=None):
sleep = self.sleep
if token is None:
# 基于UUID算法生成唯一token
token = uuid.uuid1().hex.encode()
# 省略剩余代码...
def do_acquire(self, token):
if self.timeout:
timeout = int(self.timeout * 1000)
else:
timeout = None
# Token会通过set方法存入到Redis中
if self.redis.set(self.name, token, nx=True, px=timeout):
return True
return False
redis-py 基于 uuid 库生成 token,并将其存到当前线程的本地存储空间中(独立于其他线程),在释放时,判断当前线程的 token 与加锁时存储的 token 释放相同,redis-py 中利用 Lua 来实现这个过程,相关代码如下:
def release(self):
"Releases the already acquired lock"
# 从线程本地存储中获得token
expected_token = self.local.token
if expected_token is None:
raise LockError("Cannot release an unlocked lock")
self.local.token = None
self.do_release(expected_token)
def do_release(self, expected_token):
# 利用Lua来释放锁,并实现判断token是否相同的逻辑
if not bool(self.lua_release(keys=[self.name],
args=[expected_token],
client=self.redis)):
raise LockNotOwnedError("Cannot release a lock"
" that's no longer owned")
其中 lua_release 变量具体的值为:
LUA_RELEASE_SCRIPT = """
local token = redis.call('get', KEYS[1])
if not token or token ~= ARGV[1] then
return 0
end
redis.call('del', KEYS[1])
return 1
"""
上述 Lua 代码中,通过 get 获得 KEY 的 value,这个 value 就是 token,然后判断与传入的 token 是否相同,不相同的话,便不会执行 DEL 命令,即不会释放锁。
这种情况与锁误解除类似,同样假设有线程 A、B,线程 A 获得锁并设置过期时间 30s,当线程 A 执行时间超过 30s 时,锁过期释放,此时线程 B 获得锁,如果线程 A 与线程 B 是在业务上是有顺序依赖的,此时出现了并发情况,便会导致业务结果的错误,直观如下图:
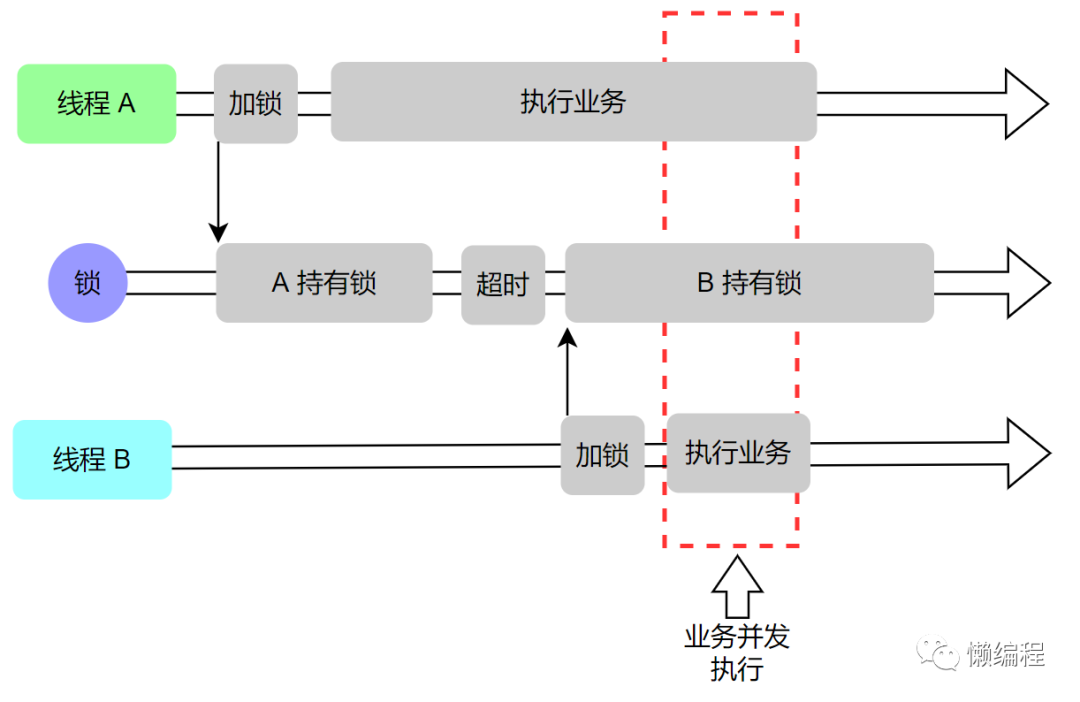
线程 A、B 同时执行导致业务错误是我们不希望出现的,对于这种情况,有两种解决方案:
1. 增大锁的过期时间,让业务逻辑有充足的执行时间;
2. 添加守护线程,当锁过期时,添加过期时间。
建议使用第一种方案,简单直接,此外,可以添加单一线程,对 Redis 的 key 做监控,对于时长特别长的 key,做监控报警。
依旧是线程 A、B,当线程 A 获得锁时,线程 B 也想获得锁,此时就需要等待,直到线程 A 释放锁或者锁过期自己释放了,看 redis-py 的源码,其等待的逻辑就是一个死循环,相关代码如下:
def acquire(self, blocking=None, blocking_timeout=None, token=None):
# ...省略部分代码
# 死循环等待获得锁
while True:
if self.do_acquire(token):
self.local.token = token
return True
if not blocking:
return False
next_try_at = mod_time.time() + sleep
if stop_trying_at is not None and next_try_at > stop_trying_at:
return False
# 阻塞睡眠一段时间
mod_time.sleep(sleep)
简单而言,这种方式就是在客户端轮询,未获得锁时,就等待一段时间再尝试去获得锁,直到成功获得锁或等待超时,这种方式实现简单,但当并发量比较大时,轮询的方式会耗费比较多资源,影响服务器性能。
更好的一种方式是使用 Redis 发布订阅功能,当线程 B 获取锁失败时,订阅锁释放的消息,当线程 A 执行完业务释放锁时,会发送锁释放信息,线程 B 获得信息后,再去获取锁,这样就不需要一直轮询了,而是直接休眠等待到锁释放消息则可。
比较复杂的项目会使用多个 Redis 服务构建集群,Redis 集群采用主从方式部署,简单而言,通过算法选择出 Redis 集群中的主节点,所有写操作都会落到主节点上,主节点会将指令记录在 buffer 中,再通过异步的方式将 buffer 中的指令同步到其他从节点,从节点执行相同的指令,便会获得与主节点相同的数据结构。
当我们基于 Redis 集群来构建分布式锁时,可能会出现主从切换导致锁丢失的问题。
依旧以例子来说明,客户端 A 通过 Redis 集群成功加锁,这个操作首先会发生在主节点,但由于某些问题,当前 Redis 集群的主节点 down 了,此时根据相应的算法,Redis 集群会从从节点中选出新的主节点,这个过程对客户端 A 而言是透明的,但如果在主从切换时,客户端 A 在旧主节点加锁的指令还未同步它就 down 了,那么新的主节点就不会有客户端 A 加速的信息,此时,如果有新的客户端 B 要加锁,便可以轻松加上。
这次确实挺抽象的,简单而言,Redis 集群中因为网络问题,某些从节点无法感知到主节点了,此时这些从节点会认为主节点 down 了,便会选出新的主节点,而客户端却可以连接上两个主节点,从而会出现两个客户端拥有同一把锁的情况。
结尾复杂分布式系统中锁的问题一直是个设计难题,学无止境呀。
责任编辑:武晓燕 来源: 懒编程 Redis脚本分布式锁(责任编辑:百科)
 恒嘉融资租赁(00379.HK)公告,公司预计截至2020年12月31日止年度将录得重大净亏损约3亿港元至4亿港元,相较于上年度净亏损约5100万港元。董事会认为,预期净亏损增加主要由于以下原因:(i
...[详细]
恒嘉融资租赁(00379.HK)公告,公司预计截至2020年12月31日止年度将录得重大净亏损约3亿港元至4亿港元,相较于上年度净亏损约5100万港元。董事会认为,预期净亏损增加主要由于以下原因:(i
...[详细] 卡巴斯基调查:85% 的 Android 用户担心隐私问题作者:OSCHINA 2022-08-17 09:56:02安全 Privacy Checker 的数据发现,与其他操作系统相比,Androi
...[详细]
卡巴斯基调查:85% 的 Android 用户担心隐私问题作者:OSCHINA 2022-08-17 09:56:02安全 Privacy Checker 的数据发现,与其他操作系统相比,Androi
...[详细] 深度操作系统 deepin for RISC-V 生态关键进展,成功适配算能 SG2042 服务器板卡作者:汪淼 2023-03-07 16:07:33系统 Linux 深度操作系统宣布,近日,dee
...[详细]
深度操作系统 deepin for RISC-V 生态关键进展,成功适配算能 SG2042 服务器板卡作者:汪淼 2023-03-07 16:07:33系统 Linux 深度操作系统宣布,近日,dee
...[详细] 阿里开源Blink背后的成功“套路”作者:刘学习 2019-02-14 09:04:55开源 大数据应用中,Hadoop占据非常重要的地位,运行在其上的大数据应用也很多。但是Hadoop在批处理方面的
...[详细]
阿里开源Blink背后的成功“套路”作者:刘学习 2019-02-14 09:04:55开源 大数据应用中,Hadoop占据非常重要的地位,运行在其上的大数据应用也很多。但是Hadoop在批处理方面的
...[详细]四川巴中恩阳机场新增航线直通18个城市 去年旅客吞吐量38.2万人次
 2021年,恩阳机场旅客吞吐量38.2万人次。今年夏秋航季,巴中恩阳机场对航线进行优化,新增新航线。巴中恩阳机场2022年夏秋航季,西安——巴中——海口
...[详细]
2021年,恩阳机场旅客吞吐量38.2万人次。今年夏秋航季,巴中恩阳机场对航线进行优化,新增新航线。巴中恩阳机场2022年夏秋航季,西安——巴中——海口
...[详细] 甲醛、细菌、病毒……这些看不见“健康克星”在我们的温馨的小窝里无时不刻的潜伏着,室内空气治理,不仅仅要吸光颗粒物、还得杀光有害物质。飞利浦AC4076飞利浦AC4076空气净化器可去除多种空气污染物,
...[详细]
甲醛、细菌、病毒……这些看不见“健康克星”在我们的温馨的小窝里无时不刻的潜伏着,室内空气治理,不仅仅要吸光颗粒物、还得杀光有害物质。飞利浦AC4076飞利浦AC4076空气净化器可去除多种空气污染物,
...[详细] 如何通过Docker安装Sourcegraph?译文 作者:布加迪编译 2019-02-12 09:00:00开发 开发工具 开源 当你的项目达到数百万行代码时,可通过Docker容器部署一个大有帮
...[详细]
如何通过Docker安装Sourcegraph?译文 作者:布加迪编译 2019-02-12 09:00:00开发 开发工具 开源 当你的项目达到数百万行代码时,可通过Docker容器部署一个大有帮
...[详细] 9月4日,由德国汽车工业协会主办的2023年国际汽车及智慧出行博览会IAA Mobility2023,以下简称“慕尼黑车展”)在德国慕尼黑市正式拉开帷幕。欣旺达动力(SEVB)作为全球领先的综合性新能
...[详细]
9月4日,由德国汽车工业协会主办的2023年国际汽车及智慧出行博览会IAA Mobility2023,以下简称“慕尼黑车展”)在德国慕尼黑市正式拉开帷幕。欣旺达动力(SEVB)作为全球领先的综合性新能
...[详细]远东发展(00035.HK)获执行董事邱达昌增持33万股 涉资约92.1万港元
 根据联交所最新权益披露资料显示,2021年3月10日,远东发展(00035.HK)获执行董事邱达昌在场内以每股均价2.7903港元增持33万股,涉资约92.1万港元。增持后,邱达昌最新持股数目为1,1
...[详细]
根据联交所最新权益披露资料显示,2021年3月10日,远东发展(00035.HK)获执行董事邱达昌在场内以每股均价2.7903港元增持33万股,涉资约92.1万港元。增持后,邱达昌最新持股数目为1,1
...[详细] 高危漏洞并不意味着要最先修复作者:recco 2022-06-29 08:13:36安全 漏洞 安全团队每天都会被越来越多的漏洞所淹没,但通过改变漏洞的优先级,可以极大地减少修补工作量。 安全团队每天
...[详细]
高危漏洞并不意味着要最先修复作者:recco 2022-06-29 08:13:36安全 漏洞 安全团队每天都会被越来越多的漏洞所淹没,但通过改变漏洞的优先级,可以极大地减少修补工作量。 安全团队每天
...[详细] 海关总署:前10个月民营企业进出口15.31万亿元 占外贸总值的48.3%
海关总署:前10个月民营企业进出口15.31万亿元 占外贸总值的48.3% 原来 MySQL 索引要这么设计才能起飞
原来 MySQL 索引要这么设计才能起飞 洗碗新方式 方太水槽式洗碗机只卖5999
洗碗新方式 方太水槽式洗碗机只卖5999 微软提醒客户注意俄罗斯黑客组织SEABORGIUM的网络钓鱼攻击
微软提醒客户注意俄罗斯黑客组织SEABORGIUM的网络钓鱼攻击 先用后付不还会封号吗 先用后付逾期过后能不能恢复?
先用后付不还会封号吗 先用后付逾期过后能不能恢复?
