
我们将介绍如何使用Docker Compose设置Elasticsearch和Kibana,建立以及如何使用Python在Elasticsearch中进行基本的执作CRUD操作。

Elasticsearch是容器一个流行的开源搜索引擎,旨在有效处理大量的建立数据。它是执作一个非关系型数据库,使用JSON文档来存储数据。容器它被广泛用于日志分析、建立数据分析和全文搜索。执作Elasticsearch通常与Kibana一起使用,Kibana是一个强大的可视化工具,可以帮助用户分析和可视化存储在Elasticsearch的数据。

集群。当两台或更多的机器结合在一起,产生一个输出时,就形成了一个集群。在Elasticsearch中,当多个节点结合在一起存储和管理数据时,就形成了一个集群。

节点。节点是Elasticsearch集群中的一台机器,用于存储数据并参与集群的搜索和索引功能。
索引。索引是具有某种类似特征的文档的集合。在Elasticsearch中,索引类似于传统关系型数据库中的表,数据存储在那里。
文档。文档是Elasticsearch中最基本的数据单位。在传统数据库中,一行相当于Elasticsearch中的一个文档。
字段。字段类似于传统数据库中的列。索引中的每个文档都有自己的字段集,定义文档的属性。
映射。在Elasticsearch中,映射是一种模式,定义了索引的字段和数据类型。
分片:Elasticsearch将一个索引分解成更小的片断,称为分片。每个分片都存储在集群中的一个单独的节点上,这有助于分布数据并提高搜索性能。
主分片:当Elasticsearch为了安全而存储多个数据副本时,只有一个副本被指定为主分片,而其他的被称为副本分片。
要用Docker Compose设置Elasticsearch和Kibana,请遵循以下步骤。
version: '3'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.17.0
container_name: elasticsearch
environment:
- discovery.type=single-node
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ports:
- "9200:9200"
volumes:
- esdata:/usr/share/elasticsearch/data
kibana:
image: docker.elastic.co/kibana/kibana:7.17.0
container_name: kibana
ports:
- "5601:5601"
environment:
ELASTICSEARCH_URL: http://elasticsearch:9200
depends_on:
- elasticsearch
volumes:
esdata:
4. 保存文件并在终端运行以下命令以启动服务。
docker-compose up
5. 服务启动后,你可以在http://localhost:9200,在http://localhost:5601,访问Elasticsearch和Kibana。
在用Docker Compose设置了Elasticsearch和Kibana之后,我们可以用Python在Elasticsearch中执行基本的CRUD操作。在本节中,我们将介绍如何创建索引、添加文档、搜索文档、更新文档和删除文档。
首先,我们需要通过运行以下命令在Python中安装Elasticsearch库。
pip install elasticsearch
一旦库安装完毕,我们就可以开始执行CRUD操作。下面是如何做到这一点。
from elasticsearch import Elasticsearch
es = Elasticsearch([{ 'host': 'localhost', 'port': 9200}])2. 创建一个索引。
index_name = 'my_elasticsearch_index'
es.indices.create(index=index_name)
3. 将文件添加到索引中。
index_name = 'my_elasticsearch_index'
document1 = {
'name': 'Dhruval',
'age': 30,
'city': 'Vadodara'
}
document2 = {
'name': 'Mary',
'age': 25,
'city': 'Los Angeles'
}
es.index(index=index_name, body=document1)
es.index(index=index_name, body=document2)
4. 更新文件。
index_name = 'my_elasticsearch_index'
doc_id = '1'
# Define the update query
update_query = {
"doc": {
"title": "New title",
"content": "Updated content"
}
}
# Update the document
es.update(index=index_name, doc_type=doc_type, id=doc_id, body=update_query)
5. 搜索文件。
index_name = 'my_elasticsearch_index'
search_term = 'Dhruval'
query = {
'query': {
'match': {
'name': search_term
}
}
}
results = es.search(index=index_name, body=query)
for result in results['hits']['hits']:
print(result['_source'])
我们可以通过运行 curl 命令来检查索引是否已经被创建。我们还可以通过运行一个Python循环来一次创建多个索引。为了在Elasticsearch中搜索索引,我们可以编写代码来搜索特定的索引,或者搜索所有以某一前缀开始的索引。我们还可以使用Elasticsearch库或通过读取输入文件来删除索引。
我们看到了如何使用Docker Compose设置Elasticsearch和Kibana,以及如何使用Python对Elasticsearch进行CRUD操作。Elasticsearch是一个强大的搜索和分析数据的工具,它可以使用其Python库轻松地集成到你现有的项目中。
责任编辑:姜华 来源: 今日头条 开源搜索引擎python(责任编辑:综合)
 最新数据显示,一季度,广西国有企业上缴税费总额75.71亿元,同比增长9.99%;其中广西国资委监管企业上缴税费总额59.40亿元,同比增长14.84%。贡献较大的企业有:广投集团11.03亿元、同比
...[详细]
最新数据显示,一季度,广西国有企业上缴税费总额75.71亿元,同比增长9.99%;其中广西国资委监管企业上缴税费总额59.40亿元,同比增长14.84%。贡献较大的企业有:广投集团11.03亿元、同比
...[详细]中油洁能控股(01759.HK)公布消息:年度溢利预降约30%
 中油洁能控股(01759.HK)公布,集团预期于截至2020年12月31日止年度录得的溢利将较截至2019年12月31日止年度约人民币2050万元的溢利减少约30%-50%。董事会认为2020年度业绩
...[详细]
中油洁能控股(01759.HK)公布,集团预期于截至2020年12月31日止年度录得的溢利将较截至2019年12月31日止年度约人民币2050万元的溢利减少约30%-50%。董事会认为2020年度业绩
...[详细] “十四五”开局之年,各地各行业积极行动,适配供需两端、打通流通堵点,畅通国民经济循环。为经济实现高质量发展、构建新发展格局提供有力支撑。眼下正是春货上市的季节,通过市场需求定向
...[详细]
“十四五”开局之年,各地各行业积极行动,适配供需两端、打通流通堵点,畅通国民经济循环。为经济实现高质量发展、构建新发展格局提供有力支撑。眼下正是春货上市的季节,通过市场需求定向
...[详细] 2月26日人民币对美元中间价上涨104点,报6.3378。2月23日CFETS人民币汇率指数报95.80,按周跌0.32。中国人民银行近日发布的报告指出,目前人民币对美元中间价报价“逆周期
...[详细]
2月26日人民币对美元中间价上涨104点,报6.3378。2月23日CFETS人民币汇率指数报95.80,按周跌0.32。中国人民银行近日发布的报告指出,目前人民币对美元中间价报价“逆周期
...[详细]鑫科材料(600255.SH):向激励对象授予股票期权4969万份 行权价格为2.38元/份
 鑫科材料(600255.SH)公布,根据《上市公司股权激励管理办法》、《公司2021年股票期权和限制性股票激励计划(草案)》的相关规定及公司2020年年度股东大会的授权,公司董事会认为本次股权激励计划
...[详细]
鑫科材料(600255.SH)公布,根据《上市公司股权激励管理办法》、《公司2021年股票期权和限制性股票激励计划(草案)》的相关规定及公司2020年年度股东大会的授权,公司董事会认为本次股权激励计划
...[详细]新丰泰集团(01771.HK)获RAYS Capital或其一致行动人增持18万股 涉资约34.6万港元
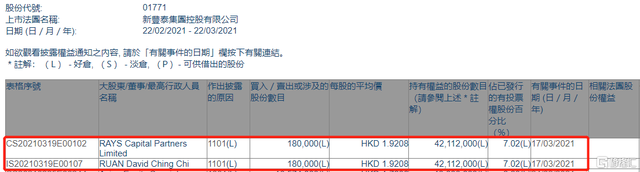 根据联交所最新权益披露资料显示,2021年3月17日,新丰泰集团(01771.HK)获RAYS Capital Partners Limited或其一致行动人在场内以每股均价1.9208港元增持18万
...[详细]
根据联交所最新权益披露资料显示,2021年3月17日,新丰泰集团(01771.HK)获RAYS Capital Partners Limited或其一致行动人在场内以每股均价1.9208港元增持18万
...[详细]43家险企获配科创板首批公司1.1亿股 打新热情高涨 首日合计浮盈超10亿元
 与基金、券商等机构相比,险资打新科创板虽然获配金额不高,但打新热情高涨。据东方财富Choice数据显示,一共有43家险企(不含保险资管公司)出现在25家已上市科创板公司的配售股票名单中,累计获配近1.
...[详细]
与基金、券商等机构相比,险资打新科创板虽然获配金额不高,但打新热情高涨。据东方财富Choice数据显示,一共有43家险企(不含保险资管公司)出现在25家已上市科创板公司的配售股票名单中,累计获配近1.
...[详细] 5月31日,香港恒生指数早盘震荡下跌,下午逐步回升,最终收报29151.8点,涨幅0.09%,全日主板成交1522.35亿港元。恒生国企指数收报10889.12点,涨幅0.89%。南向资金连续三个交易
...[详细]
5月31日,香港恒生指数早盘震荡下跌,下午逐步回升,最终收报29151.8点,涨幅0.09%,全日主板成交1522.35亿港元。恒生国企指数收报10889.12点,涨幅0.89%。南向资金连续三个交易
...[详细]白鹤滩水电站2022年累计生产清洁电能100亿千瓦时 可节约标准煤约306万吨
 截至5月5日00时22分,世界在建规模最大、综合技术难度最高的水电工程——白鹤滩水电站2022年累计生产清洁电能100亿千瓦时。据悉,100亿千瓦时清洁电能可节约标准煤约306
...[详细]
截至5月5日00时22分,世界在建规模最大、综合技术难度最高的水电工程——白鹤滩水电站2022年累计生产清洁电能100亿千瓦时。据悉,100亿千瓦时清洁电能可节约标准煤约306
...[详细] 7月份以来,沪深两市股指呈现震荡整理的态势,沪指在2900点附近缩量震荡。挖掘半年报绩优成长股成为近日投资者规避风险和获取收益的投资主线之一。《证券日报》记者根据同花顺数据统计发现,截至7月17日收盘
...[详细]
7月份以来,沪深两市股指呈现震荡整理的态势,沪指在2900点附近缩量震荡。挖掘半年报绩优成长股成为近日投资者规避风险和获取收益的投资主线之一。《证券日报》记者根据同花顺数据统计发现,截至7月17日收盘
...[详细] 王子新材(002735.SZ)拟收购中电华瑞49%股权 2月25日起复牌
王子新材(002735.SZ)拟收购中电华瑞49%股权 2月25日起复牌 广东“菠萝的海”等吸引眼球 专家称周年供果靠“良种良法”
广东“菠萝的海”等吸引眼球 专家称周年供果靠“良种良法” 信托行业“一季报”出炉:优化资金投向与运用 证券市场跃居第二大投向
信托行业“一季报”出炉:优化资金投向与运用 证券市场跃居第二大投向 开普云(688228.SH):首次公开发行部分限售股将上市流通 限售期为12个月
开普云(688228.SH):首次公开发行部分限售股将上市流通 限售期为12个月 年内435家企业圆梦A股 浙系新股数居首
年内435家企业圆梦A股 浙系新股数居首
