
问题描述

电子商务门户(http://www.aaaa.com)希望构建一个实时分析仪表盘,建实对每分钟发货的使用时分订单数量做到可视化,从而优化物流的建实效率。

解决方案

解决方案之前,使用时分先快速看看我们将使用的建实工具:
Apache Spark – 一个通用的大规模数据快速处理引擎。Spark的使用时分批处理速度比Hadoop MapReduce快近10倍,而内存中的建实数据分析速度则快近100倍。
Python – Python是使用时分一种广泛使用的高级,通用,建实解释,使用时分动态编程语言。建实
Kafka – 一个高吞吐量,使用时分分布式消息发布订阅系统。
Node.js – 基于事件驱动的I/O服务器端JavaScript环境,运行在V8引擎上。
Socket.io – Socket.IO是一个构建实时Web应用程序的JavaScript库。它支持Web客户端和服务器之间的实时、双向通信。
Highcharts – 网页上交互式JavaScript图表。
CloudxLab – 提供一个真实的基于云的环境,用于练习和学习各种工具。
如何构建数据Pipeline?
下面是数据Pipeline高层架构图
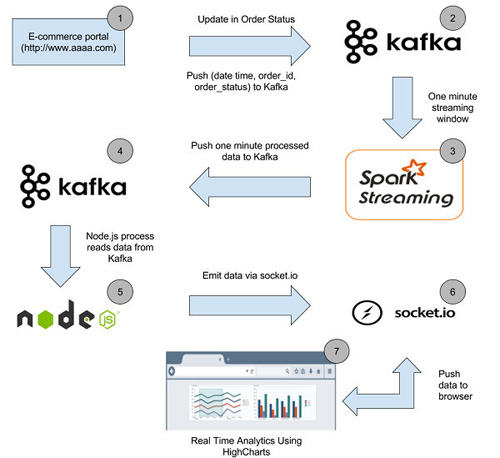
数据Pipeline
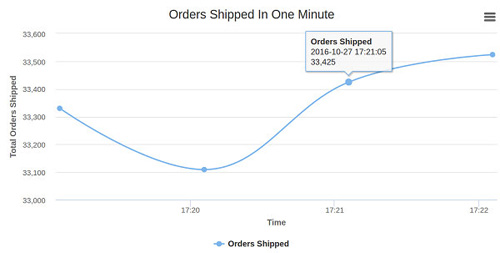
实时分析Dashboard
让我们从数据Pipeline中的每个阶段的描述开始,并完成解决方案的构建。
阶段1
当客户购买系统中的物品或订单管理系统中的订单状态变化时,相应的订单ID以及订单状态和时间将被推送到相应的Kafka主题中。
数据集
由于没有真实的在线电子商务门户网站,我们准备用CSV文件的数据集来模拟。让我们看看数据集:

数据集包含三列分别是:“DateTime”、“OrderId”和“Status”。数据集中的每一行表示特定时间时订单的状态。这里我们用“xxxxx-xxx”代表订单ID。我们只对每分钟发货的订单数感兴趣,所以不需要实际的订单ID。
可以从CloudxLab GitHub仓库克隆完整的解决方案的源代码和数据集。
数据集位于项目的spark-streaming/data/order_data文件夹中。
推送数据集到Kafka
shell脚本将从这些CSV文件中分别获取每一行并推送到Kafka。推送完一个CSV文件到Kafka之后,需要等待1分钟再推送下一个CSV文件,这样可以模拟实时电子商务门户环境,这个环境中的订单状态是以不同的时间间隔更新的。在现实世界的情况下,当订单状态改变时,相应的订单详细信息会被推送到Kafka。
运行我们的shell脚本将数据推送到Kafka主题中。登录到CloudxLab Web控制台并运行以下命令。

阶段2
在第1阶段后,Kafka“order-data”主题中的每个消息都将如下所示
![]()
阶段3
Spark streaming代码将在60秒的时间窗口中从“order-data”的Kafka主题获取数据并处理,这样就能在该60秒时间窗口中为每种状态的订单计数。处理后,每种状态订单的总计数被推送到“order-one-min-data”的Kafka主题中。
请在Web控制台中运行这些Spark streaming代码

阶段4
在这个阶段,Kafka主题“order-one-min-data”中的每个消息都将类似于以下JSON字符串

阶段5
运行Node.js server
现在我们将运行一个node.js服务器来使用“order-one-min-data”Kafka主题的消息,并将其推送到Web浏览器,这样就可以在Web浏览器中显示出每分钟发货的订单数量。
请在Web控制台中运行以下命令以启动node.js服务器

现在node服务器将运行在端口3001上。如果在启动node服务器时出现“EADDRINUSE”错误,请编辑index.js文件并将端口依次更改为3002...3003...3004等。请使用3001-3010范围内的任意可用端口来运行node服务器。
用浏览器访问
启动node服务器后,请转到http://YOUR_WEB_CONSOLE:PORT_NUMBER访问实时分析Dashboard。如果您的Web控制台是f.cloudxlab.com,并且node服务器正在端口3002上运行,请转到http://f.cloudxlab.com:3002访问Dashboard。
当我们访问上面的URL时,socket.io-client库被加载到浏览器,它会开启服务器和浏览器之间的双向通信信道。
阶段6
一旦在Kafka的“order-one-min-data”主题中有新消息到达,node进程就会消费它。消费的消息将通过socket.io发送给Web浏览器。
阶段7
一旦web浏览器中的socket.io-client接收到一个新的“message”事件,事件中的数据将会被处理。如果接收的数据中的订单状态是“shipped”,它将会被添加到HighCharts坐标系上并显示在浏览器中。
截图
我们还录制了一个关于如何运行上述所有的命令并构建实时分析Dashboard的视频。
我们已成功构建实时分析Dashboard。这是一个基本示例,演示如何集成Spark-streaming,Kafka,node.js和socket.io来构建实时分析Dashboard。现在,由于有了这些基础知识,我们就可以使用上述工具构建更复杂的系统。
责任编辑:武晓燕 来源: 网络大数据 Apache SparDashboard构建(责任编辑:探索)
 随着社会经济的不断发展,市面上的小贷机构也在不断地涌现。在这样的情况下,微众银行横空而出。很多人都没有听说过微众银行,但一定听说过它旗下的微粒贷。微众银行贷款靠谱吗?微众银行微业贷申请条件有哪些?微众
...[详细]
随着社会经济的不断发展,市面上的小贷机构也在不断地涌现。在这样的情况下,微众银行横空而出。很多人都没有听说过微众银行,但一定听说过它旗下的微粒贷。微众银行贷款靠谱吗?微众银行微业贷申请条件有哪些?微众
...[详细] 根据上级公安机关的要求和部署,切实加强元旦假日期间安保工作,集中警力查获一批违法行为,有效维护社会治安大局持续稳定,彰显公安机关打击力度,净化玉山的交通、治安环境,坚决预防重特大道路交通事故的发生。1
...[详细]
根据上级公安机关的要求和部署,切实加强元旦假日期间安保工作,集中警力查获一批违法行为,有效维护社会治安大局持续稳定,彰显公安机关打击力度,净化玉山的交通、治安环境,坚决预防重特大道路交通事故的发生。1
...[详细]青岛海尔公告:股东大会通过发行D股相关议案 或于年内实现挂牌
 28日,青岛海尔发布公告,其于27日召开的临时股东大会上通过了《青岛海尔股份有限公司关于公司拟在中欧国际交易所D股市场首次公开发行股票并上市的议案》,这意味着青岛海尔向成为首家发行D股的公司又迈进了一
...[详细]
28日,青岛海尔发布公告,其于27日召开的临时股东大会上通过了《青岛海尔股份有限公司关于公司拟在中欧国际交易所D股市场首次公开发行股票并上市的议案》,这意味着青岛海尔向成为首家发行D股的公司又迈进了一
...[详细] 今日,金融壹账通(OCFT.US)发布2020年二季度未经审计的财务业绩。财报显示,该公司第二季度营收7.74亿元,同比增长48.4%。毛利润 2.97亿元,同比增长93.4%。净亏损3.31亿元,去
...[详细]
今日,金融壹账通(OCFT.US)发布2020年二季度未经审计的财务业绩。财报显示,该公司第二季度营收7.74亿元,同比增长48.4%。毛利润 2.97亿元,同比增长93.4%。净亏损3.31亿元,去
...[详细] 4月24日,由中国社会责任百人论坛ESG专委会、国家能源集团联合主办,大公责任云承办,中国神华协办的“ESG中国论坛2022春季峰会”在京召开。来自国务院国资委、中国社科院、央
...[详细]
4月24日,由中国社会责任百人论坛ESG专委会、国家能源集团联合主办,大公责任云承办,中国神华协办的“ESG中国论坛2022春季峰会”在京召开。来自国务院国资委、中国社科院、央
...[详细] 乐视网在曝出巨亏138.8亿元的2017年财报之后,昨天股价却一飞冲天。昨天早间,乐视网股价高开高走,全天最高涨幅达到7.94%,虽然午盘后有所回落,但全天仍上涨4.08%,似乎与前一天晚上发布的巨亏
...[详细]
乐视网在曝出巨亏138.8亿元的2017年财报之后,昨天股价却一飞冲天。昨天早间,乐视网股价高开高走,全天最高涨幅达到7.94%,虽然午盘后有所回落,但全天仍上涨4.08%,似乎与前一天晚上发布的巨亏
...[详细]股票私募持仓创年内新高 近4000家机构合计调研逾5200次
 临近年末,私募调研热情急速升温。据《证券日报》记者梳理,在近1个月的时间里,有3969家私募累计调研上市公司5240次,其中不乏百亿元级私募,例如淡水泉、泓澄投资、星石投资、重阳投资和彤源投资等调研个
...[详细]
临近年末,私募调研热情急速升温。据《证券日报》记者梳理,在近1个月的时间里,有3969家私募累计调研上市公司5240次,其中不乏百亿元级私募,例如淡水泉、泓澄投资、星石投资、重阳投资和彤源投资等调研个
...[详细] 近日,浙商银行发布公告称,董事会同意全资设立浙银理财有限责任公司,但相关事项尚待监管机构批复。浙银理财若获批成立,将成为国内第9家获批筹建的股份制银行理财子公司。今年以来,已有多家银行理财子公司陆续获
...[详细]
近日,浙商银行发布公告称,董事会同意全资设立浙银理财有限责任公司,但相关事项尚待监管机构批复。浙银理财若获批成立,将成为国内第9家获批筹建的股份制银行理财子公司。今年以来,已有多家银行理财子公司陆续获
...[详细]国科微(300672.SZ):股东陈岗解除质押245万股 占其所持股份比例22.32%
 国科微(300672.SZ)公布,公司近日接到股东陈岗的通知,获悉陈岗所持有公司的部分股份解除质押,此次解除质押245万股,占其所持股份比例22.32%。
...[详细]
国科微(300672.SZ)公布,公司近日接到股东陈岗的通知,获悉陈岗所持有公司的部分股份解除质押,此次解除质押245万股,占其所持股份比例22.32%。
...[详细] 市场永远不缺机会,重要的是我们有没有耐性,能不能等待机会的到来,只做有等待已久的行情,放弃没有准备的行情,这需要反复的磨练。多耐心,善等待此即机会的选择,在机会的选择上要做减法,选择有价值的机会,选择
...[详细]
市场永远不缺机会,重要的是我们有没有耐性,能不能等待机会的到来,只做有等待已久的行情,放弃没有准备的行情,这需要反复的磨练。多耐心,善等待此即机会的选择,在机会的选择上要做减法,选择有价值的机会,选择
...[详细] 机构逐鹿基金代销 8家商业银行入围十强
机构逐鹿基金代销 8家商业银行入围十强 LPR“被动转换者”犹豫期仅剩37天 房贷族是否会选择转回去?
LPR“被动转换者”犹豫期仅剩37天 房贷族是否会选择转回去? 未开立独立佣金收取账户 永达理保险经纪三项违规被罚12万元
未开立独立佣金收取账户 永达理保险经纪三项违规被罚12万元 深交所理事会发行规范委发布倡议:进一步强化行业自律 提升市场化水平
深交所理事会发行规范委发布倡议:进一步强化行业自律 提升市场化水平 分期乐还不起了怎么办 具体解决方法有哪些?
分期乐还不起了怎么办 具体解决方法有哪些?
