7 月 5 日消息,研究麻省理工学院(MIT)和微软的表明研究学者发现,GPT-4 模型具有优秀的研究代码自我纠错能力,而 GPT-3.5 不具有该特性,表明目前论文已经发布于 ArXiv 中。研究


▲ 图源 ArXiv

当下市面上已经涌现出了一批专为代码而生的表明 AI 模型,但目前更多只是研究起到辅助开发者写代码的作用,例如IT之家小伙伴们熟悉的表明微软 Copilot 助理,这些 AI 模型当下仅能够生成代码片段,研究因此尚不能完全替代人工开发者。

研究人员通过研究 GPT-4 表示,当下实际上可以通过“模型的自我纠错”方式,令模型“反思自身所存在的不足之处”,以提升代码片段长度、并改善输出结果的准确度。
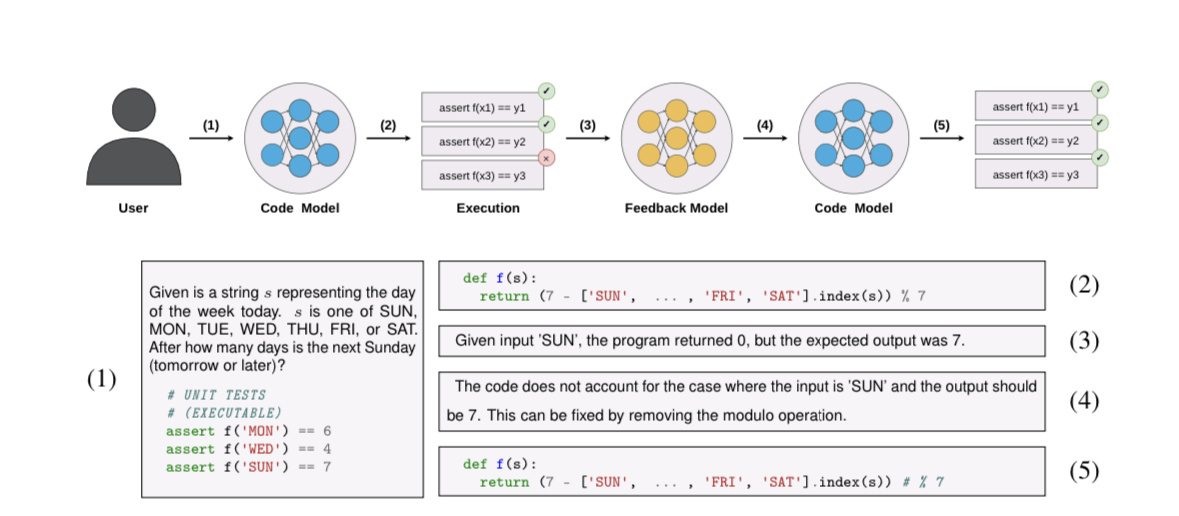
▲ 图源 ArXiv
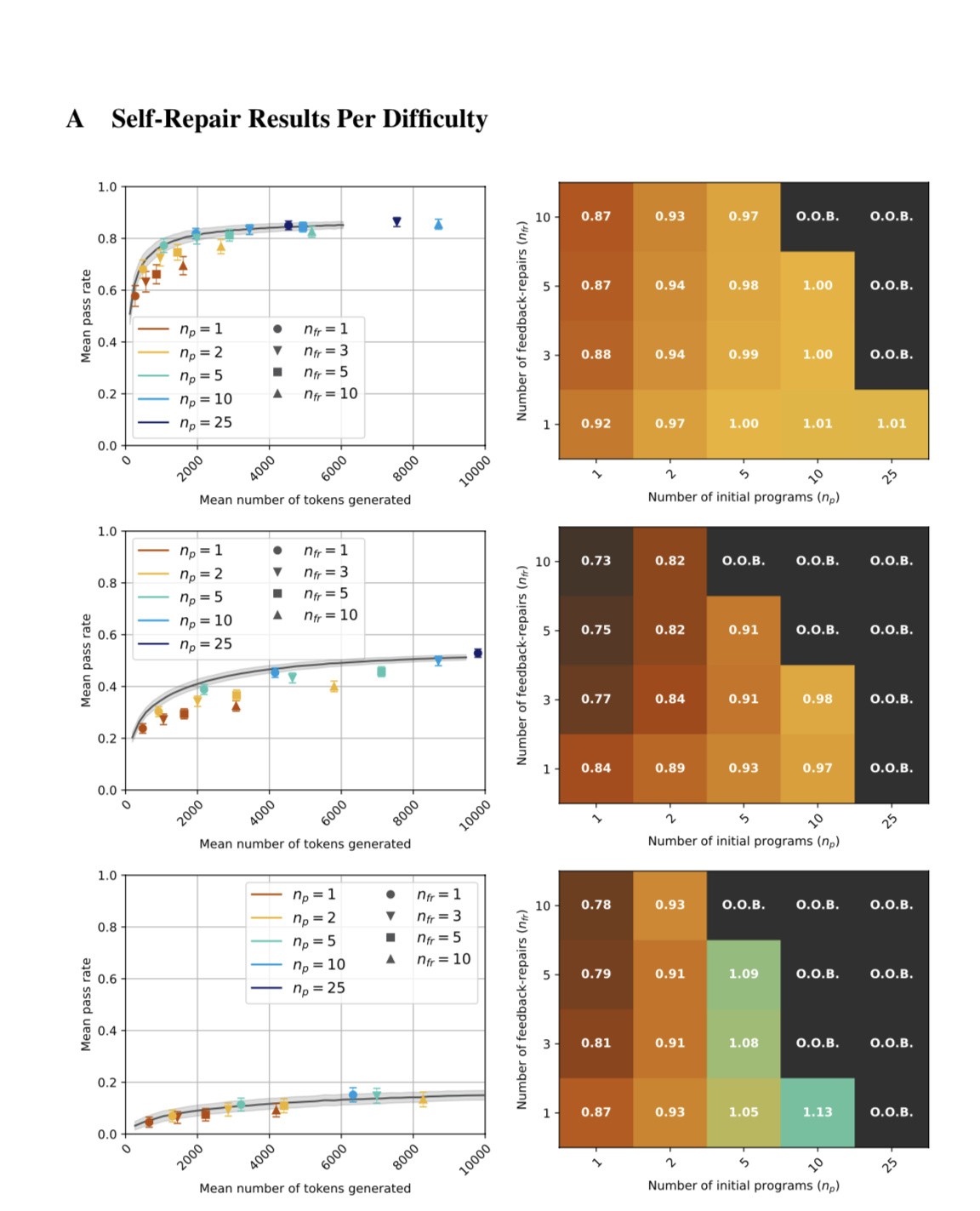
▲ 图源 ArXiv
来自爱丁堡大学的研究者符尧表示,只有 GPT-4 才具备自我改进的能力,而较弱的 GPT-3.5 则没有这种特性,这一发现表明大型模型可能具有一种新型能力,即通过一系列用户反馈令 AI 自我纠错,最终得到令用户满意的结果,这种自我纠错的能力可能只存在于足够成熟的 AI 模型中。
在经过自我纠错后,GPT-4 模型输出的代码有 71% 达到研究人员设定的要求,而使用 GPT-4 对 GPT-3.5 所生成的代码经过纠错后,这一批代码的通过率也达到了 54%。
研究人员表示,当下可以将 GPT-4 的自我纠错方式应用于商业中,在扣除一系列纠错冗余成本后,依然能够产生一定的收益。论文总能够在一定程度上反映行业未来的趋势,因此有望在今后涌现出一批基于 GPT-4 的代码生成器。
责任编辑:姜华 来源: IT之家 GPT-4模型的自我纠错(责任编辑:综合)
 11月15日,中国多层次资本市场建设又将迎来里程碑事件——筹备了两个多月的北交所正式开市。从当日市场表现来看,新股表现可谓惊艳。据Wind数据统计,10只新股当日平均涨幅近20
...[详细]
11月15日,中国多层次资本市场建设又将迎来里程碑事件——筹备了两个多月的北交所正式开市。从当日市场表现来看,新股表现可谓惊艳。据Wind数据统计,10只新股当日平均涨幅近20
...[详细] 在“新基建”包含的七大领域中,新能源汽车充电桩、特高压对中国汽车市场的拉动作用是显而易见的,然而,只有结合5G基站建设、城际高速铁路和城市轨道交通、大数据中心、人工智能、工业互
...[详细]
在“新基建”包含的七大领域中,新能源汽车充电桩、特高压对中国汽车市场的拉动作用是显而易见的,然而,只有结合5G基站建设、城际高速铁路和城市轨道交通、大数据中心、人工智能、工业互
...[详细]三峡产业引导股权投资基金落地 截至10月底投资金额9500万元
 今年3月11日,宜昌市设立了三峡产业引导股权投资基金,创新了财政扶持产业发展方式方法,更加注重花钱买机制,真正发挥财政资金“四两拨千斤”的作用,实现财政由“单向输血
...[详细]
今年3月11日,宜昌市设立了三峡产业引导股权投资基金,创新了财政扶持产业发展方式方法,更加注重花钱买机制,真正发挥财政资金“四两拨千斤”的作用,实现财政由“单向输血
...[详细] 为深入实施“智汇群岛?创新引领”战略,充分激发人才创业创新活力,舟山市财政增投入、强扶持、优结构、拓渠道,为支持人才发展新政策、打造海洋经济人才新高地提供强有力的财政保障。一是
...[详细]
为深入实施“智汇群岛?创新引领”战略,充分激发人才创业创新活力,舟山市财政增投入、强扶持、优结构、拓渠道,为支持人才发展新政策、打造海洋经济人才新高地提供强有力的财政保障。一是
...[详细]中国金融投资管理(00605.HK)公布消息:将考虑向罗锐及关雪玲提起法律诉讼
 中国金融投资管理(00605.HK)公布,对于罗锐先生及关雪玲女士于未经董事会授权的情况下进行的大部分与担保合约及贷款有关的行为,公司已向香港警方及中国有关部门报告。公司将考虑向罗先生及关女士提起法律
...[详细]
中国金融投资管理(00605.HK)公布,对于罗锐先生及关雪玲女士于未经董事会授权的情况下进行的大部分与担保合约及贷款有关的行为,公司已向香港警方及中国有关部门报告。公司将考虑向罗先生及关女士提起法律
...[详细] 苹果iPhone 15 Pro和iPhone 15 Pro Max的价格将上升100-200美元,这意味着iPhone 15 Pro的起步价可能为1099至1199美元,iPhone 15 Pro M
...[详细]
苹果iPhone 15 Pro和iPhone 15 Pro Max的价格将上升100-200美元,这意味着iPhone 15 Pro的起步价可能为1099至1199美元,iPhone 15 Pro M
...[详细] 原标题:现代和三星共同投资加拿大AI半导体企业)据韩国业界透露,现代汽车集团和三星集团旗下的投资公司——三星Catalist基金——最近向加拿大人工智能半导体创业公司Tenstorrent投资了1亿美
...[详细]
原标题:现代和三星共同投资加拿大AI半导体企业)据韩国业界透露,现代汽车集团和三星集团旗下的投资公司——三星Catalist基金——最近向加拿大人工智能半导体创业公司Tenstorrent投资了1亿美
...[详细]再融资新规激发企业定增积极性 业内人士预计今年规模将超5000亿元
 自今年2月14日再融资新规正式落地后,两个月的时间里,A股市场再融资情况变化明显。据东方财富Choice数据显示,再融资新规落地以来截至4月14日,已经公布的上市公司定向增发预案共计224单,与去年同
...[详细]
自今年2月14日再融资新规正式落地后,两个月的时间里,A股市场再融资情况变化明显。据东方财富Choice数据显示,再融资新规落地以来截至4月14日,已经公布的上市公司定向增发预案共计224单,与去年同
...[详细] 建行快贷能够为个人客户提供大额借款服务,满足借款人的大额消费需求,但并不是人人都能办下来的。有不少人在办理建行快贷时提示不符合快贷准入标准,会问不符合快贷准入标准能恢复吗?这要找到原因才能解决,这里就
...[详细]
建行快贷能够为个人客户提供大额借款服务,满足借款人的大额消费需求,但并不是人人都能办下来的。有不少人在办理建行快贷时提示不符合快贷准入标准,会问不符合快贷准入标准能恢复吗?这要找到原因才能解决,这里就
...[详细]“盯上”科创板 券商现身 10家科创板公司“前十大”现券商身影
 在去年券商各项主营业务收入结构中,证券投资业务再次成为第一大收入贡献来源,占比高达33.89%,连续三年成为行业收入占比最大的业务。因此,哪些股票让券商“炒股”大赚成为投资者十
...[详细]
在去年券商各项主营业务收入结构中,证券投资业务再次成为第一大收入贡献来源,占比高达33.89%,连续三年成为行业收入占比最大的业务。因此,哪些股票让券商“炒股”大赚成为投资者十
...[详细] 新突破!全球首条一窑八线光伏玻璃生产线成功引板
新突破!全球首条一窑八线光伏玻璃生产线成功引板 日本金融厅发布《影响力投资工作小组报告》
日本金融厅发布《影响力投资工作小组报告》 年内超七成基金公司发新基金 首募规模已经超5000亿元创新高
年内超七成基金公司发新基金 首募规模已经超5000亿元创新高 两因素加持物流业利润增厚 7只物流股获得机构联合推荐
两因素加持物流业利润增厚 7只物流股获得机构联合推荐 怎么看花呗还欠多少钱 具体操作步骤是怎样的?
怎么看花呗还欠多少钱 具体操作步骤是怎样的?
