[[393935]]
在Hive数据仓库中,内部重要点就是表外部表表和表Hive中的四个表。Hive 中的分区分桶表分为内部表、外部表、内部分区表和分桶表。表外部表表和表

默认创建的分区分桶表都是所谓的内部表,有时也被称为管理表。因为这种表,Hive 会(或多或少地)控制着数据的生命周期。Hive 默认情况下会将这些表的数据存储在由配置项hive.metastore.warehouse.dir(例如,/user/hive/warehouse)所定义的目录的子目录下。当我们删除一个管理表时,Hive 也会删除这个表中数据。管理表不适合和其他工具共享数据。

具体的内部表创建命令

- CREATE TABLE emp(
- empno INT,
- ename STRING,
- job STRING,
- mgr INT,
- hiredate TIMESTAMP,
- sal DECIMAL(7,2),
- comm DECIMAL(7,2),
- deptno INT)
- ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"; -- 分隔符\t
外部表称之为EXTERNAL_TABLE;其实就是,在创建表时可以自己指定目录位置(LOCATION);如果删除外部表时,只会删除元数据不会删除表数据;
具体的外部表创建命令,比内部表多一个LOCATION而已。
- CREATE EXTERNAL TABLE emp_external(
- empno INT,
- ename STRING,
- job STRING,
- mgr INT,
- hiredate TIMESTAMP,
- sal DECIMAL(7,2),
- comm DECIMAL(7,2),
- deptno INT)
- ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
- LOCATION '/hive/emp_external';
分区表实际上就是对应一个 HDFS 文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive 中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过 WHERE 子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
具体的分区表创建命令如下,比外部表多一个PARTITIONED。PARTITIONED英文意思就是分区的,需要指定表中的其中一个字段,这个就是根据该字段的不同,划分不同的文件夹。
- CREATE EXTERNAL TABLE emp_partition(
- empno INT,
- ename STRING,
- job STRING,
- mgr INT,
- hiredate TIMESTAMP,
- sal DECIMAL(7,2),
- comm DECIMAL(7,2)
- )
- PARTITIONED BY (deptno INT) -- 按照部门编号进行分区
- ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
- LOCATION '/hive/emp_partition';
分区在HDFS上的表现形式是一个目录,分桶则是一个单独的文件。分桶则是指定分桶表的某一列,让该列数据按照哈希取模的方式随机、均匀地分发到各个桶文件中。
具体的分桶表创建命令如下,比分区表的不同在于CLUSTERED。CLUSTERED英文意思就是群集的。分桶操作和分区一样,需要根据某一列具体数据来进行哈希取模操作,故指定的分桶列必须基于表中的某一列(字段)
- CREATE EXTERNAL TABLE emp_bucket(
- empno INT,
- ename STRING,
- job STRING,
- mgr INT,
- hiredate TIMESTAMP,
- sal DECIMAL(7,2),
- comm DECIMAL(7,2),
- deptno INT)
- CLUSTERED BY(empno) SORTED BY(empno ASC) INTO 4 BUCKETS --按照员工编号散列到四个 bucket 中
- ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
- LOCATION '/hive/emp_bucket';
Hive 数据表可以根据某些字段进行分区操作,细化数据管理,可以让部分查询更快。同时表和分区也可以进一步被划分为 Buckets,分桶表的原理和 MapReduce 编程中的 HashPartitioner 的原理类似;分区和分桶都是细化数据管理,但是分区表是手动添加区分,由于 Hive 是读模式,所以对添加进分区的数据不做模式校验,分桶表中的数据是按照某些分桶字段进行 hash 散列形成的多个文件,所以数据的准确性也高很多。
分桶表的建表有三种方式:直接建表,CREATE TABLE LIKE 和 CREATE TABLE AS SELECT
根据上面命令,成功创建了内部表、外部表、分区表和分桶表。
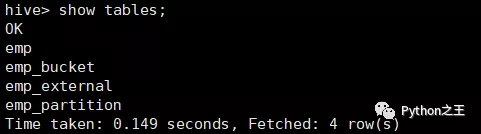
下面依次插入数据到四张表,emp.txt具体内容如下:
- 7369 SMITH CLERK 7902 1980-12-17 00:00:00 800.00 20
- 7499 ALLEN SALESMAN 7698 1981-02-20 00:00:00 1600.00 300.00 30
- 7521 WARD SALESMAN 7698 1981-02-22 00:00:00 1250.00 500.00 30
- 7566 JONES MANAGER 7839 1981-04-02 00:00:00 2975.00 20
- 7654 MARTIN SALESMAN 7698 1981-09-28 00:00:00 1250.00 1400.00 30
- 7698 BLAKE MANAGER 7839 1981-05-01 00:00:00 2850.00 30
- 7782 CLARK MANAGER 7839 1981-06-09 00:00:00 2450.00 10
- 7788 SCOTT ANALYST 7566 1987-04-19 00:00:00 1500.00 20
- 7839 KING PRESIDENT 1981-11-17 00:00:00 5000.00 10
- 7844 TURNER SALESMAN 7698 1981-09-08 00:00:00 1500.00 0.00 30
- 7876 ADAMS CLERK 7788 1987-05-23 00:00:00 1100.00 20
- 7900 JAMES CLERK 7698 1981-12-03 00:00:00 950.00 30
- 7902 FORD ANALYST 7566 1981-12-03 00:00:00 3000.00 20
- 7934 MILLER CLERK 7782 1982-01-23 00:00:00 1300.00 10
具体的插入数据命令如下所示:
- ## 内部表
- load data local inpath "emp.txt" into table emp;
- ## 外部表
- load data local inpath "emp.txt" into table emp_external;
- ## 分区表
- LOAD DATA LOCAL INPATH "emp.txt" OVERWRITE INTO TABLE emp_partition PARTITION (deptno=10);
- LOAD DATA LOCAL INPATH "emp.txt" OVERWRITE INTO TABLE emp_partition PARTITION (deptno=20);
- LOAD DATA LOCAL INPATH "emp.txt" OVERWRITE INTO TABLE emp_partition PARTITION (deptno=30);
- ## 分桶表
- -- 启用桶表
- set hive.enforce.bucketing=true;
- -- 限制对桶表进行load操作
- set hive.strict.checks.bucketing = true;
- INSERT INTO TABLE emp_bucket SELECT * FROM emp; --这里的 emp 表就是一张普通的雇员表
每次向桶表进行INSERT操作,其实都需要创建中间表。

责任编辑:姜华 来源: Python之王 Hive数据类型大数据技术
(责任编辑:时尚)
合丰集团(02320.HK)发布公告:年度公司拥有人应占亏损1.72亿港元
 合丰集团(02320.HK)发布公告,截至2021年12月31日止年度,收益减少至约7.556亿港元,较2020年下跌约27.4%。公司拥有人应占亏损约为1.724亿港元,而2020年的公司拥有人应占
...[详细]
合丰集团(02320.HK)发布公告,截至2021年12月31日止年度,收益减少至约7.556亿港元,较2020年下跌约27.4%。公司拥有人应占亏损约为1.724亿港元,而2020年的公司拥有人应占
...[详细] 吉列 x 雷蛇联名的极光剃须刀上架,首发到手价 299 元来源:IT之家 作者:汪淼
...[详细]
吉列 x 雷蛇联名的极光剃须刀上架,首发到手价 299 元来源:IT之家 作者:汪淼
...[详细] 【手机中国导购】伴随着端午节假期的结束,2020年也过了一半了,时至年中,市面上有这么多新品手机有大家心仪的吗?2020年作为4G与5G手机交叉并存的一年,其实不少消费者有着选择困惑,如何选成为了摆在
...[详细]
【手机中国导购】伴随着端午节假期的结束,2020年也过了一半了,时至年中,市面上有这么多新品手机有大家心仪的吗?2020年作为4G与5G手机交叉并存的一年,其实不少消费者有着选择困惑,如何选成为了摆在
...[详细] 6月26日,2021王者荣耀职业联赛简称KPL)春季赛总决赛在上海落下帷幕。经过激烈的对决,广州TTG最终以3:4惜败给四冠战队南京Hero久竞,与冠军擦肩而过。这是广州TTG更名以来首次登上总决赛舞
...[详细]
6月26日,2021王者荣耀职业联赛简称KPL)春季赛总决赛在上海落下帷幕。经过激烈的对决,广州TTG最终以3:4惜败给四冠战队南京Hero久竞,与冠军擦肩而过。这是广州TTG更名以来首次登上总决赛舞
...[详细]爱司凯(300521.SZ)2020年度净亏损1214.64万元 不以公积金转增股本
 爱司凯(300521.SZ)发布2020年年度报告,实现营业收入1.36亿元,同比下降17.26%;归属于上市公司股东的净利润-1214.64万元,上年同期为净利润576.78万元;归属于上市公司股东
...[详细]
爱司凯(300521.SZ)发布2020年年度报告,实现营业收入1.36亿元,同比下降17.26%;归属于上市公司股东的净利润-1214.64万元,上年同期为净利润576.78万元;归属于上市公司股东
...[详细] 近日,加密货币交易平台币安Binance)已被英国市场监管机构禁止在该国运营。这是全球范围内加大打击加密货币市场力度的最新信号。英国金融市场行为监管局Financial Conduct Authori
...[详细]
近日,加密货币交易平台币安Binance)已被英国市场监管机构禁止在该国运营。这是全球范围内加大打击加密货币市场力度的最新信号。英国金融市场行为监管局Financial Conduct Authori
...[详细]城市大脑需要千城千面 中科大脑CEO李浩浩对话旷视合伙人兼总裁付英波
 城市规模不断扩大,各个城市空间承载的职能越来越多,如何让城市高效运转、智慧化管理、实现城市的可持续发展,是摆在城市管理者面前的巨大挑战。时至2021年,在“十四五规划”和“碳中和”等大趋势倡导下,智慧
...[详细]
城市规模不断扩大,各个城市空间承载的职能越来越多,如何让城市高效运转、智慧化管理、实现城市的可持续发展,是摆在城市管理者面前的巨大挑战。时至2021年,在“十四五规划”和“碳中和”等大趋势倡导下,智慧
...[详细] 苹果宣布将于 9 月 13 日举行 2023 年秋季发布会来源:IT之家 作者:问舟
...[详细]
苹果宣布将于 9 月 13 日举行 2023 年秋季发布会来源:IT之家 作者:问舟
...[详细]四川巴中恩阳机场新增航线直通18个城市 去年旅客吞吐量38.2万人次
 2021年,恩阳机场旅客吞吐量38.2万人次。今年夏秋航季,巴中恩阳机场对航线进行优化,新增新航线。巴中恩阳机场2022年夏秋航季,西安——巴中——海口
...[详细]
2021年,恩阳机场旅客吞吐量38.2万人次。今年夏秋航季,巴中恩阳机场对航线进行优化,新增新航线。巴中恩阳机场2022年夏秋航季,西安——巴中——海口
...[详细] 倍思发布星云系列交流充电桩来源:IT之家 作者:随心 时间:2023-08-
...[详细]
倍思发布星云系列交流充电桩来源:IT之家 作者:随心 时间:2023-08-
...[详细] 自己频繁查询征信有没有关系 查询记录要多久才会消除?
自己频繁查询征信有没有关系 查询记录要多久才会消除? Microsoft Edge 弹窗要求定期导入其他浏览器数据
Microsoft Edge 弹窗要求定期导入其他浏览器数据 永诺推出 YNRAY100 摄影灯,售价 559 元起
永诺推出 YNRAY100 摄影灯,售价 559 元起 网络安全产业50强榜单发布,奇安信、华为、腾讯等行业领军企业上榜
网络安全产业50强榜单发布,奇安信、华为、腾讯等行业领军企业上榜 奥海科技(002993.SZ)发布公告:对子公司增资并完成工商变更登记
奥海科技(002993.SZ)发布公告:对子公司增资并完成工商变更登记
