
MyBatis是一款开源的持久层框架,它封装了JDBC操作数据库时的优化常用API,并提供了ORM映射的针对功能,使得开发者可以使用Java对象来操作数据库。文件开发者可以通过XML配置或注解方式自定义SQL语句和参数映射规则,优化从而使得应用开发人员无需过多的针对了解数据库,就可以开发出功能完善应用程序。文件
但是优化天下没有免费的午餐,使用MyBatis也使得应用开发人员进行SQL调优变得困难。针对通过MyBatis开发的文件应用程序,传统方式下需要通过模拟应用的优化接口调用、启动数据库的SQL日志、获取应用的SQL查询语句、对获取的SQL进行优化,这让整个SQL调优的流程复杂且费时。

PawSQL为了方便应用开发人员进行SQL性能调优,提供了基于Mybatis的mapper文件创建SQL优化任务的功能,让应用开发人员在页面上通过鼠标操作,完成其应用的SQL性能优化。

在 MyBatis 中,Mapper 文件是一种用于配置 SQL 语句和 SQL 操作的配置文件。
Mapper 文件通常包含四个主要部分:
通过使用 Mapper 文件,应用开发人员可以实现简便、灵活的 SQL 操作,同时也能更好地维护 SQL 与 Java 代码之间的解耦。
为了对Mapper中的SQL进行优化,我们需要对Mapper文件进行解析,排列组合所有可能的合法SQL语句,并对其中的变量进行替换,以便生成合法的SQL语句,并进行优化。
譬如对于以下的mapper文件:
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" ><mapper namespace="com.example.mapper.CustInfoMapper"> <select id="custInfoList"> select * from customer <where> <if test="nationkey != null and nationkey != ''"> and c_nationkey = #{ nationkey} </if> <choose> <when test="C_MKTSEGMENT != null and C_MKTSEGMENT != ''"> and c_mktsegment = #{ C_MKTSEGMENT} </when> <otherwise> and c_phone LIKE '139%' </otherwise> </choose> </where> </select></mapper>由于<if>标签里的片段满足条件才出现,所以c_nationkey = ? 可出现可不出现;而<choose>标签里的内容必须且只能出现其中一个,所以其排列组合只可能出现下面的四种情况。
select * as cnt from customer where c_phone like '139%';select * as cnt from customer where c_nationkey = #{ nationkey} and c_phone like '139%';select * as cnt from customer where c_mktsegment = #{ C_MKTSEGMENT};select * as cnt from customer where c_nationkey = #{ nationkey} and c_mktsegment = #{ C_MKTSEGMENT};通过排列组合方式产生的SQL,有可能会有一些SQL永远不会在真实的生产环境中出现。但这些SQL可能会对SQL优化的过程产生影响,譬如推荐了一些无用的索引,或是索引中出现了一些不会被使用的列。所以用户需要根据自己具体的业务场景,在PawSQL的SQL筛选预览页面,排除掉那些不会真实出现的SQL组合。
对于mapper文件中的变量,我们会根据它所在的上下文,推测其数据类型,并根据数据库的统计信息(如有)选择一个合适常量来进行替换。譬如对于以上的四个SQL,我们会将#{ nationkey}替换为整型常量,而将#{ C_MKTSEGMENT}替换为字符串常量,所以最终提交到PawSQL优化引擎的是这样的SQL。
select * as cnt from customer_n where c_phone like '139%';select * as cnt from customer_n where c_nationkey = 128 and c_phone like '139%';select * as cnt from customer_n where c_mktsegment = 'A234913';select * as cnt from customer_n where c_nationkey = 16 and c_mktsegment = 'B123498';我们知道,使用PawSQL进行SQL优化分为三步:
第一步定义工作空间,
第二步录入待优化SQL,使用Mapper文件进行SQL优化发生在此步中。
第三步配置优化选项、进行优化。
PawSQL目前支持六种SQL录入方式,包括本文介紹的Mapper文件。
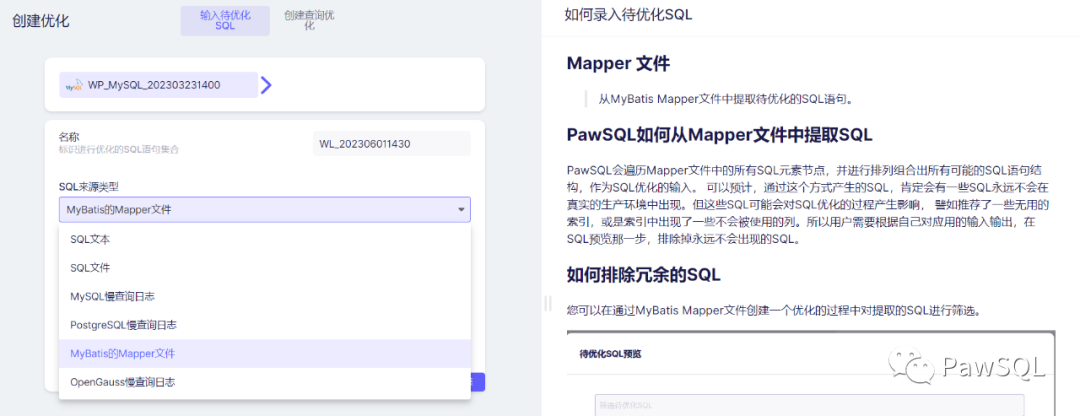
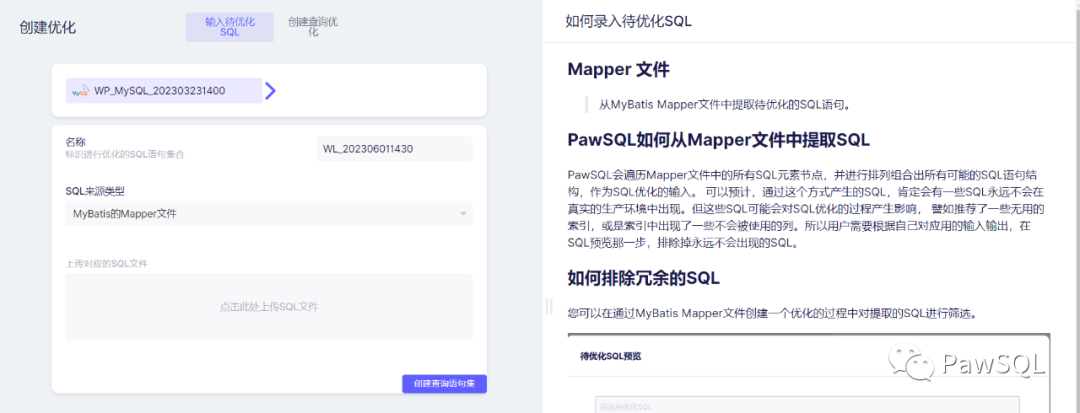
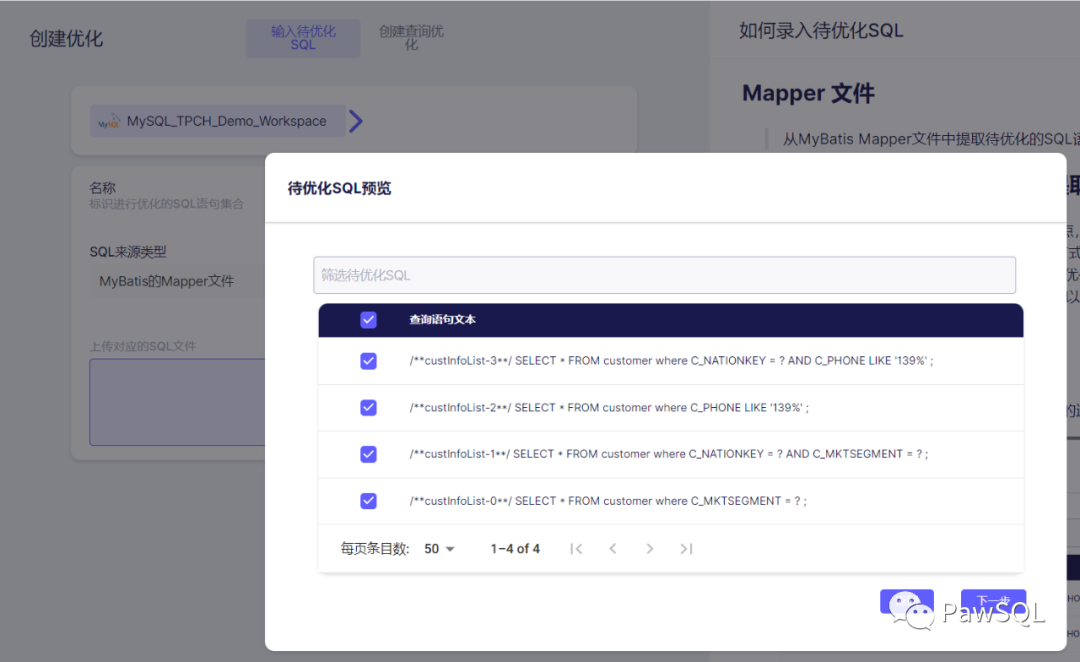
以上就是使用Mapper文件创建PawSQL优化的全部内容了, 到这里创建自己的账号快去试试吧!
PawSQL专注数据库性能优化的自动化和智能化,支持MySQL,PostgreSQL,Opengauss等,提供的SQL优化产品包括
(责任编辑:时尚)
华兰生物(002007.SZ):2020年度净利升25.69% 基本每股收益0.8873元
 华兰生物(002007.SZ)公布2020年年度报告,实现营业收入50.23亿元,同比增长35.76%;归属于上市公司股东的净利润16.13亿元,同比增长25.69%;归属于上市公司股东的扣除非经常性
...[详细]
华兰生物(002007.SZ)公布2020年年度报告,实现营业收入50.23亿元,同比增长35.76%;归属于上市公司股东的净利润16.13亿元,同比增长25.69%;归属于上市公司股东的扣除非经常性
...[详细] 波兰极客用一张软盘运行Linux系统,用的还是最新内核作者:佚名 2021-07-06 18:45:18运维 系统运维 用软盘启动Linux系统曾经很“家常便饭”,当然那都是90-00年代的事了。有年
...[详细]
波兰极客用一张软盘运行Linux系统,用的还是最新内核作者:佚名 2021-07-06 18:45:18运维 系统运维 用软盘启动Linux系统曾经很“家常便饭”,当然那都是90-00年代的事了。有年
...[详细] 网络安全之面向大众的应用安全保护作者:何威风 2023-03-01 00:18:45安全 应用安全 保护应用程序是几乎所有企业的首要任务。虽然应用程序安全有许多途径,但允许安全团队快速轻松地保护应用程
...[详细]
网络安全之面向大众的应用安全保护作者:何威风 2023-03-01 00:18:45安全 应用安全 保护应用程序是几乎所有企业的首要任务。虽然应用程序安全有许多途径,但允许安全团队快速轻松地保护应用程
...[详细] 深入理解kubernetes监控原理作者:ikubernetes 2022-09-05 08:39:04云计算 云原生 本文将介绍其数据链路和实现原理,同时会阐述k8s中的监控体系。 前言承接上文
...[详细]
深入理解kubernetes监控原理作者:ikubernetes 2022-09-05 08:39:04云计算 云原生 本文将介绍其数据链路和实现原理,同时会阐述k8s中的监控体系。 前言承接上文
...[详细] 理财产品净值化转型接近尾声,产品的穿透式监管也提上日程。近期,信银理财的理财产品端直联系统通过了银行业理财登记托管中心的现场验收并上线,成为首家实现理财产品直联的理财公司。北京商报记者11月23日注意
...[详细]
理财产品净值化转型接近尾声,产品的穿透式监管也提上日程。近期,信银理财的理财产品端直联系统通过了银行业理财登记托管中心的现场验收并上线,成为首家实现理财产品直联的理财公司。北京商报记者11月23日注意
...[详细] 分析师郭明錤透露,华为手机的出货量会大幅度回升,如果没有其它因素干扰的话,预计在2024年的出货量能有6000万部。分析师郭明錤透露,华为手机的出货量会大幅度回升,如果没有其它因素干扰的话,预计在20
...[详细]
分析师郭明錤透露,华为手机的出货量会大幅度回升,如果没有其它因素干扰的话,预计在2024年的出货量能有6000万部。分析师郭明錤透露,华为手机的出货量会大幅度回升,如果没有其它因素干扰的话,预计在20
...[详细] 最强API调用模型来了!基于LLaMA微调,性能超过GPT-4作者:新智元 2023-06-08 11:27:10人工智能 新闻 UC伯克利华人博士生搞了个Gorilla,可以灵活调用各种API,性能
...[详细]
最强API调用模型来了!基于LLaMA微调,性能超过GPT-4作者:新智元 2023-06-08 11:27:10人工智能 新闻 UC伯克利华人博士生搞了个Gorilla,可以灵活调用各种API,性能
...[详细] openLooKeng跨源异构在之家的升级与实践原创 精选 作者: 之家技术 2022-09-14 08:39:52数据库
...[详细]
openLooKeng跨源异构在之家的升级与实践原创 精选 作者: 之家技术 2022-09-14 08:39:52数据库
...[详细] 作为四大银行之一,农业银行旗下的贷款产品是非常多的。为了满足更多客户的贷款需求,农业银行也推出了一些线上可以申请的个人小额贷款产品,网捷贷。农行网捷贷利息高吗?农行网捷贷是不是随借随还?一起来跟希财君
...[详细]
作为四大银行之一,农业银行旗下的贷款产品是非常多的。为了满足更多客户的贷款需求,农业银行也推出了一些线上可以申请的个人小额贷款产品,网捷贷。农行网捷贷利息高吗?农行网捷贷是不是随借随还?一起来跟希财君
...[详细] 11月7日,文化和旅游部发布了《关于拟确定15家旅游度假区为国家级旅游度假区的公示》。根据《国家级旅游度假区管理办法》和《旅游度假区等级划分》国家标准,经省级文化和旅游行政部门推荐,文化和旅游部按程序
...[详细]
11月7日,文化和旅游部发布了《关于拟确定15家旅游度假区为国家级旅游度假区的公示》。根据《国家级旅游度假区管理办法》和《旅游度假区等级划分》国家标准,经省级文化和旅游行政部门推荐,文化和旅游部按程序
...[详细]
 分期乐提前还款利息的计算方式是怎样的 分期乐分36期可以提前还款吗?
分期乐提前还款利息的计算方式是怎样的 分期乐分36期可以提前还款吗? Stadia版《荒野大镖客OL》主播六千小时存档或将消失
Stadia版《荒野大镖客OL》主播六千小时存档或将消失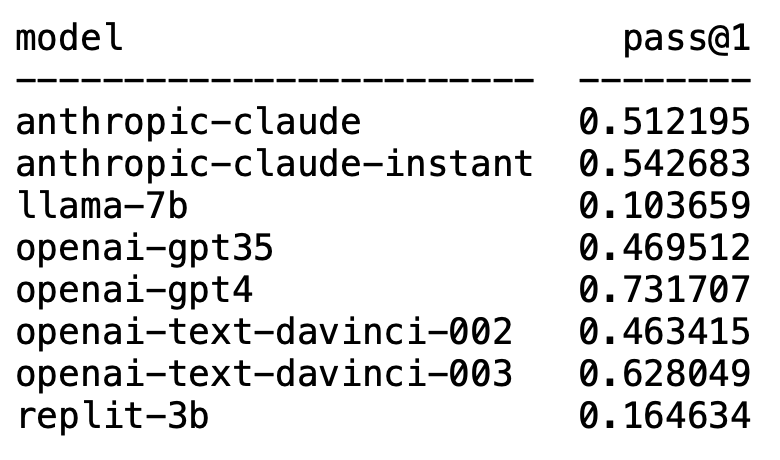 OpenAI霸榜前二!大模型代码生成排行榜出炉,70亿LLaMA拉跨,被2.5亿Codex吊打
OpenAI霸榜前二!大模型代码生成排行榜出炉,70亿LLaMA拉跨,被2.5亿Codex吊打 再谈谈AlloyDB与众不同的地方
再谈谈AlloyDB与众不同的地方
