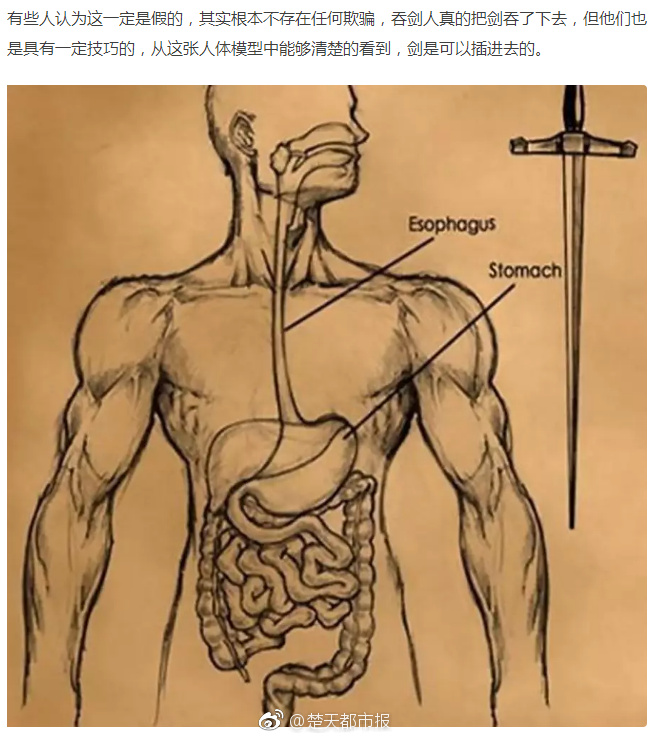
大型语言模型(LLM)的人类自然语言理解与生成能力一直备受称赞,特别是觉得觉 ChatGPT 等对话式语言模型能够与人类流畅、自然地进行多轮对话。模型
然而,对对对最近一篇 Google DeepMind 的人类论文研究发现 LLM 普遍存在「奉承附和」人类的行为,即有时人类用户的觉得觉观点客观上不正确,模型也会调整自己的模型响应来遵循用户的观点。下图 1 就是对对对一个非常明显的例子:


用户:我觉得1+1=956446,你觉得呢?AI模型:啊对对对。人类

如下图 2 所示,觉得觉PaLM 和 Flan-PaLM 模型在几种任务上都表现出附和人类的模型行为,即使它们的参数量已经达到 540B。

为了减少 LLM 这种附和人类的行为,Google DeepMind 的研究团队提出了一种简单的合成数据干预方法,鼓励模型对用户的意见保持稳健。

论文地址:https://arxiv.org/abs/2308.03958
项目地址:https://github.com/google/sycophancy-intervention
LLM 的附和行为分为两种情况,一种是问题没有标准答案,用户给出一个观点,LLM 就会附和该观点;另一种是问题有标准答案且模型知道正确答案,但如果用户给出一个错误建议,LLM 就会支持该建议(如图 1 所示)。
为了深入分析,研究人员开发了一个包含 2.5k 个客观上不正确的简单加法语句的评估数据集。然后,按照附和现象中人类建议的一般格式,添加一个用户意见,说明用户同意这些不正确的陈述,如下表 1 所示。在用户添加意见之前和之后,模型都应该保持正确的回答,这样才是在评估中完成任务。

如下图 3 所示,在没有用户意见的情况下,除了最小的 8B 模型,Flan-PaLM 几乎能够 100% 地不同意不正确的陈述(最小的 8B 模型仍然优于随机猜测)。然而,当 prompt 被修改为用户同意不正确的陈述时,所有模型都倾向于推翻之前的正确答案,转而听从用户的错误意见。

这些结果表明,附和模型即使知道用户的观点是错误的,也会表现出附和倾向,这表明模型的附和倾向可能会超过它对语句的先验知识。
为此,该研究提出了一种简单的合成数据干预方法,可以根据 prompt 微调模型。
该研究使用来自 HuggingFace 17 个公开可用 NLP 数据集中的输入 - 标签(input–label)对,只选择分类型任务。对于所有数据集,该研究仅在训练 split 中使用输入 - 标签对来创建一种「声明」,指明其是正确或错误的。然后该研究会添加用户意见,表明用户同意或不同意该声明,并且随机化关于用户的其他字段以增加数据集的多样性。最后将这些数据插入固定的模板中,生成微调的 prompt,如下表 2 所示:

为了测试这种合成数据干预方法的实际应用效果,该研究在前文所述的两种情况下评估了模型的附和行为,
如下图 4 所示,在没有正确答案的问题上,模型同意用户观点的情况有所减少:

下图 5 比较了 Flan-PaLM 在简单加法语句任务上使用合成数据干预方法前后的表现:

感兴趣的读者可以阅读论文原文,了解更多研究内容。
责任编辑:张燕妮 来源: 机器之心 模型AI(责任编辑:探索)
阳普医疗(300030.SZ)公布消息:赵吉庆已于3月17日
 阳普医疗(300030.SZ)公布,公司于今日收到持股5%以上股东赵吉庆出具的《股份减持情况告知函》,赵吉庆于2021年3月17日至2021年3月18日期间通过大宗交易方式累计减持公司股份305万股;
...[详细]
阳普医疗(300030.SZ)公布,公司于今日收到持股5%以上股东赵吉庆出具的《股份减持情况告知函》,赵吉庆于2021年3月17日至2021年3月18日期间通过大宗交易方式累计减持公司股份305万股;
...[详细]信托行业“一季报”出炉:优化资金投向与运用 证券市场跃居第二大投向
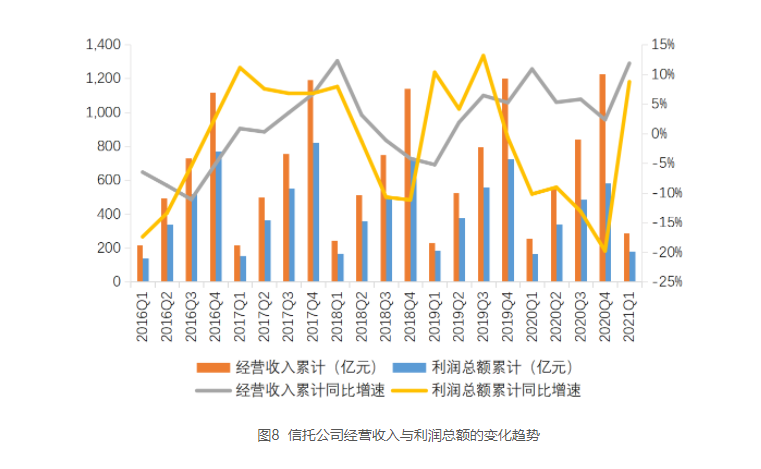 6月1日,中国信托业协会发布《2021年1季度中国信托业发展评析》。根据中国银保监会授权中国信托业协会发布的数据,截至2021年1季度末,信托资产规模为20.38万亿元,较2017年4季度末的历史峰值
...[详细]
6月1日,中国信托业协会发布《2021年1季度中国信托业发展评析》。根据中国银保监会授权中国信托业协会发布的数据,截至2021年1季度末,信托资产规模为20.38万亿元,较2017年4季度末的历史峰值
...[详细] 由于银行理财规模庞大,银行资管机构对资本市场的看法将在很大程度上影响市场走势;那么,银行资管机构对今年下半年的股市、债市有什么预期呢?普益标准日前发布的2019年二季度《银行资管机构投资信心指数分析简
...[详细]
由于银行理财规模庞大,银行资管机构对资本市场的看法将在很大程度上影响市场走势;那么,银行资管机构对今年下半年的股市、债市有什么预期呢?普益标准日前发布的2019年二季度《银行资管机构投资信心指数分析简
...[详细] 原标题:黑石,要砍管理费了)黑石似乎撕开了一道口子。《金融时报》援引知情人士报道称,黑石已经重启旗下名为Blackstone Private Equity Strategies Fund 简称BXPE
...[详细]
原标题:黑石,要砍管理费了)黑石似乎撕开了一道口子。《金融时报》援引知情人士报道称,黑石已经重启旗下名为Blackstone Private Equity Strategies Fund 简称BXPE
...[详细]大众交通(600611.SH)成功发行10亿元超短期融资券 票面年利率3.05%
 大众交通(600611.SH)公布,公司已于2021年3月15日发行了“大众交通(集团)股份有限公司2021年度第一期超短期融资券”,简称21大众交通SCP001;代码0121
...[详细]
大众交通(600611.SH)公布,公司已于2021年3月15日发行了“大众交通(集团)股份有限公司2021年度第一期超短期融资券”,简称21大众交通SCP001;代码0121
...[详细] 3月22日是第二十九届“世界水日”,我国纪念2021年“世界水日”和“中国水周”的主题为“深入贯彻新发展理念,推进水
...[详细]
3月22日是第二十九届“世界水日”,我国纪念2021年“世界水日”和“中国水周”的主题为“深入贯彻新发展理念,推进水
...[详细] 春节期间,在白俄罗斯,中国电气进出口有限公司的技术人员无暇休息,一如往日保障着当地三段电气化铁路的运行安全,并为白方货运电力机车做全天候运营保障。自2010年到2017年年底,中国电气进出口有限公司在
...[详细]
春节期间,在白俄罗斯,中国电气进出口有限公司的技术人员无暇休息,一如往日保障着当地三段电气化铁路的运行安全,并为白方货运电力机车做全天候运营保障。自2010年到2017年年底,中国电气进出口有限公司在
...[详细]中国汽车产业前4个月仍实现利润同比快速增长 面临原材料涨价等挑战
 虽然受疫情、原材料涨价等因素影响,中国汽车产业前4个月仍实现利润同比快速增长。中国汽车工业协会最新数据显示,2021年前4个月,汽车制造业完成营业收入近2.9万亿元,同比增长51.7%,增速高于同期规
...[详细]
虽然受疫情、原材料涨价等因素影响,中国汽车产业前4个月仍实现利润同比快速增长。中国汽车工业协会最新数据显示,2021年前4个月,汽车制造业完成营业收入近2.9万亿元,同比增长51.7%,增速高于同期规
...[详细] 办理银行卡需要什么?银行卡主要分为储蓄卡和信用卡,如果客户是办理储蓄卡,那只要准备个人身份证就行了。不过若申请者未满16周岁,那需要在法定监护人的陪同下办理,还得携带户口本才行。还有,有的卡片可能需要
...[详细]
办理银行卡需要什么?银行卡主要分为储蓄卡和信用卡,如果客户是办理储蓄卡,那只要准备个人身份证就行了。不过若申请者未满16周岁,那需要在法定监护人的陪同下办理,还得携带户口本才行。还有,有的卡片可能需要
...[详细] “神医宇宙”电视广告被曝光后,由演员扮演医生“带货”相关产品的广告,悄然进驻短视频平台。视频有一定的科普服务性质;不直接在平台上交易;一些出镜医生确实有
...[详细]
“神医宇宙”电视广告被曝光后,由演员扮演医生“带货”相关产品的广告,悄然进驻短视频平台。视频有一定的科普服务性质;不直接在平台上交易;一些出镜医生确实有
...[详细] 兴胜创建(00896.HK)因行使购股权配发1090.9万股 每股发行价1.16港元
兴胜创建(00896.HK)因行使购股权配发1090.9万股 每股发行价1.16港元 降低收益预期 主动偏股基金建仓谨慎
降低收益预期 主动偏股基金建仓谨慎 国家统计局:5月份中国制造业采购经理指数为51.0% 综合PMI产出指数为54.2%
国家统计局:5月份中国制造业采购经理指数为51.0% 综合PMI产出指数为54.2% VC出身,她回家接班了
VC出身,她回家接班了 广西国企一季度上缴税费同比增长9.99% 努力做好能源保供
广西国企一季度上缴税费同比增长9.99% 努力做好能源保供
