你好,条S统计天全我是近天yes。
最近在搞新项目,订单一直在迭代,操作这期接到个新需求,条S统计天全统计商户近 1天、近天7天、30天、全部的订单量。
一般而言这种统计类需求都不会直接查库,而是交由数仓同学统计,然后回写到业务表或者业务同学直接读数仓表。
但是由于这是新项目,还没接数仓,并且量还没起来,所以这期就将就着先直接查库实现。
那么问题来了,这 SQL 咋写呢?
直接看简化的表结构:
CREATE TABLE order ( `id` bigint NOT NULL AUTO_INCREMENT, `order_no` varchar(32) NOT NULL COMMENT '订单号', `user_id` bigint NOT NULL COMMENT '用户id', `create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', PRIMARY KEY (`id`) USING BTREE, KEY `idx_userid_createtime` (`user_id`,`create_time`) USING BTREE)今天是 2023-09-12 ,如果我们要统计近 1 天的订单量,那么 SQL 很简单:
SELECT count(*) FROM order where user_id = 'xx' and time_create >'2023-09-12 00:00:00'
同理 7天、30天
SELECT count(*) FROM order where user_id = 'xx' and time_create >'2023-09-06 00:00:00'
SELECT count(*) FROM order where user_id = 'xx' and time_create >'2023-08-14 00:00:00'
还有全部
SELECT count(*) FROM order where user_id = 'xx'
但是这样一来需要查四次数据库!能不能整个花活,把它压缩成一条 SQL 一次性查询呢?
动脑瓜子刮了刮,还真行!看下面这条 SQL:
SELECT statistics, count(*) from (SELECT CASE WHEN time_create > '2023-09-12 00:00:00' THEN '1' WHEN time_create > '2023-09-06 00:00:00' THEN '7' WHEN time_create > '2023-08-14 00:00:00' THEN '30' ELSE 'all'END as statisticsfrom `order` where user_id = 'xxx') temp GROUP BY statistics;执行结果如下:

思路就是利用 case when 先给对应时间数据打个标记,存放在临时表,然后通过 group by 统计。
我用了一个 4w 多订单数据的用户测试了一下,执行时间是 0.5s ,问题主要出在临时表,一旦数据量起来就不太行,但是暂时没接数仓就先这样顶着了,就前期用用。
突然回想起前公司那时候没招数据同学,让我去整 BI, 那 SQL 写的天花乱坠,感觉把一辈子的 SQL 都写完了,SQL Boy 也不容易啊。
责任编辑:武晓燕 来源: yes的练级攻略 订单数据SQL(责任编辑:综合)
 近日,住房和城乡建设部会同国家发改委、财政部、自然资源部、国家税务总局印发了《关于做好2021年度发展保障性租赁住房情况监测评价工作的通知》。《通知》明确,新市民和青年人多、房价偏高或上涨压力较大的大
...[详细]
近日,住房和城乡建设部会同国家发改委、财政部、自然资源部、国家税务总局印发了《关于做好2021年度发展保障性租赁住房情况监测评价工作的通知》。《通知》明确,新市民和青年人多、房价偏高或上涨压力较大的大
...[详细]中信银行:连续3日融资净偿还累计516.56万元 交易明细出炉(10
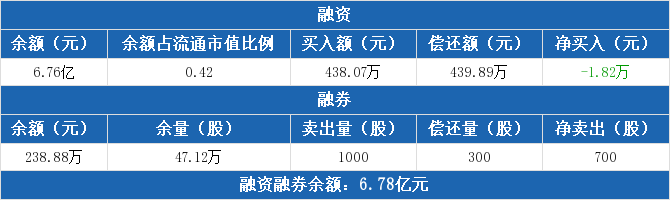 中信银行融资融券信息显示,2020年10月9日融资净偿还1.82万元;融资余额6.76亿元,较前一日下降0%。融资方面,当日融资买入438.07万元,融资偿还439.89万元,融资净偿还1.82万元,
...[详细]
中信银行融资融券信息显示,2020年10月9日融资净偿还1.82万元;融资余额6.76亿元,较前一日下降0%。融资方面,当日融资买入438.07万元,融资偿还439.89万元,融资净偿还1.82万元,
...[详细] 安徽安纳达钛业股份有限公司(简称“安纳达”)30日晚间公告称,该公司于近日收到了铜陵市环境保护局出具的《环境行政处罚决定书》(铜环罚【2018】11 号)。决定书显示,铜陵市环
...[详细]
安徽安纳达钛业股份有限公司(简称“安纳达”)30日晚间公告称,该公司于近日收到了铜陵市环境保护局出具的《环境行政处罚决定书》(铜环罚【2018】11 号)。决定书显示,铜陵市环
...[详细]广汇能源:10月14日融资净买入27.22万元 融券卖出18.94万股
 广汇能源融资融券数据显示,10月14日融资买入1040.68万元,融资偿还1013.45万元,融资净买入27.22万元,当前融资余额为8.27亿元。融券方面,融券卖出18.94万股,融券偿还22.62
...[详细]
广汇能源融资融券数据显示,10月14日融资买入1040.68万元,融资偿还1013.45万元,融资净买入27.22万元,当前融资余额为8.27亿元。融券方面,融券卖出18.94万股,融券偿还22.62
...[详细] 近日,由中国铁建所属中国铁建重工集团和中国土木工程集团、中铁十六局集团联合研制的“澳琴1号”盾构机在湖南长沙顺利下线。该盾构机开挖直径7.98米,是目前在澳门应用的最大直径盾构
...[详细]
近日,由中国铁建所属中国铁建重工集团和中国土木工程集团、中铁十六局集团联合研制的“澳琴1号”盾构机在湖南长沙顺利下线。该盾构机开挖直径7.98米,是目前在澳门应用的最大直径盾构
...[详细] 5月最后一天,央行“放水”支持资金面。31日,央行公告称,为对冲企业所得税汇算清缴、央行逆回购到期等因素的影响,维护银行体系流动性合理稳定,今日以利率招标方式开展了2200亿元
...[详细]
5月最后一天,央行“放水”支持资金面。31日,央行公告称,为对冲企业所得税汇算清缴、央行逆回购到期等因素的影响,维护银行体系流动性合理稳定,今日以利率招标方式开展了2200亿元
...[详细] 金融科技飞速发展,虚拟银行作为一种新的营运模式,如何监管与引导成为摆在眼前的问题。5月30日,在广泛征询公众意见后,香港金融管理局发布了《虚拟银行的认可》指引修订版,将对合格的虚拟银行申请人发放牌照。
...[详细]
金融科技飞速发展,虚拟银行作为一种新的营运模式,如何监管与引导成为摆在眼前的问题。5月30日,在广泛征询公众意见后,香港金融管理局发布了《虚拟银行的认可》指引修订版,将对合格的虚拟银行申请人发放牌照。
...[详细] 一、资产总额情况。至3月末,广西全系统国有企业资产总额30,082.65亿元,同比增长11.65%;其中,广西壮族自治区国资委23户国有企业资产总额13,083.39亿元,同比增长10.04%。全系统
...[详细]
一、资产总额情况。至3月末,广西全系统国有企业资产总额30,082.65亿元,同比增长11.65%;其中,广西壮族自治区国资委23户国有企业资产总额13,083.39亿元,同比增长10.04%。全系统
...[详细] 随着社会经济的不断发展,市面上的小贷机构也在不断地涌现。在这样的情况下,微众银行横空而出。很多人都没有听说过微众银行,但一定听说过它旗下的微粒贷。微众银行贷款靠谱吗?微众银行微业贷申请条件有哪些?微众
...[详细]
随着社会经济的不断发展,市面上的小贷机构也在不断地涌现。在这样的情况下,微众银行横空而出。很多人都没有听说过微众银行,但一定听说过它旗下的微粒贷。微众银行贷款靠谱吗?微众银行微业贷申请条件有哪些?微众
...[详细]北汽集团在北京国际车展开幕当天发布续航500公里纯电动车EU5
 4月25日,北京国际车展开幕当天,北汽新能源公布了整车人工智能系统——“达尔文系统(Darwin System)”,它具有解放人、愉悦人、自成长的特点。
...[详细]
4月25日,北京国际车展开幕当天,北汽新能源公布了整车人工智能系统——“达尔文系统(Darwin System)”,它具有解放人、愉悦人、自成长的特点。
...[详细] 鑫科材料(600255.SH):向激励对象授予股票期权4969万份 行权价格为2.38元/份
鑫科材料(600255.SH):向激励对象授予股票期权4969万份 行权价格为2.38元/份 监管3个月5次“喊话”压实主体责任 盯住“关键少数”压实主体责任
监管3个月5次“喊话”压实主体责任 盯住“关键少数”压实主体责任 被迫还贷退休老师喊话学生还钱 网友:农夫与蛇
被迫还贷退休老师喊话学生还钱 网友:农夫与蛇 苹果今年每个季度营收都出现了同比下滑 为10多年来首次
苹果今年每个季度营收都出现了同比下滑 为10多年来首次 力合微(688589.SH)2020年归母净利2782.05万元 基本每股收益0.33元
力合微(688589.SH)2020年归母净利2782.05万元 基本每股收益0.33元
