
为缓解海量数据访问的性能瓶颈,提高系统高并发能力,项目接入分布式数据库中间件ShardingSphere;突然有一天,开始出现一些莫名其妙的的问题:项目启动缓慢、有时启动失败、甚者项目发布失败等等。

"什么代码都没改,就是在开发库刷了分表结构,怎么项目启动不起来了......"

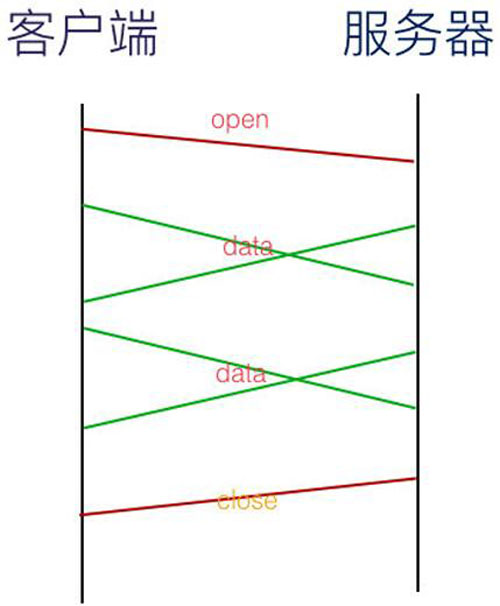
仔细分析项目启动日志,发现SchemaMetaDataLoader类第70行,在Loading 1800 tables' meta data 时,耗时689s......

1800张表正好是我们数据库中的所有表......
2023-06-26 09:15:35,372 INFO (ShardingMetaDataLoader.java:131)- Loading 1 logic tables' meta data.
2023-06-26 09:15:35,665 INFO (SchemaMetaDataLoader.java:70)- Loading 1800 tables' meta data.
2023-06-26 09:15:04,473 INFO (MultipleDataSourcesRuntimeContext.java:59)- Meta data load finished, cost 689209 milliseconds.
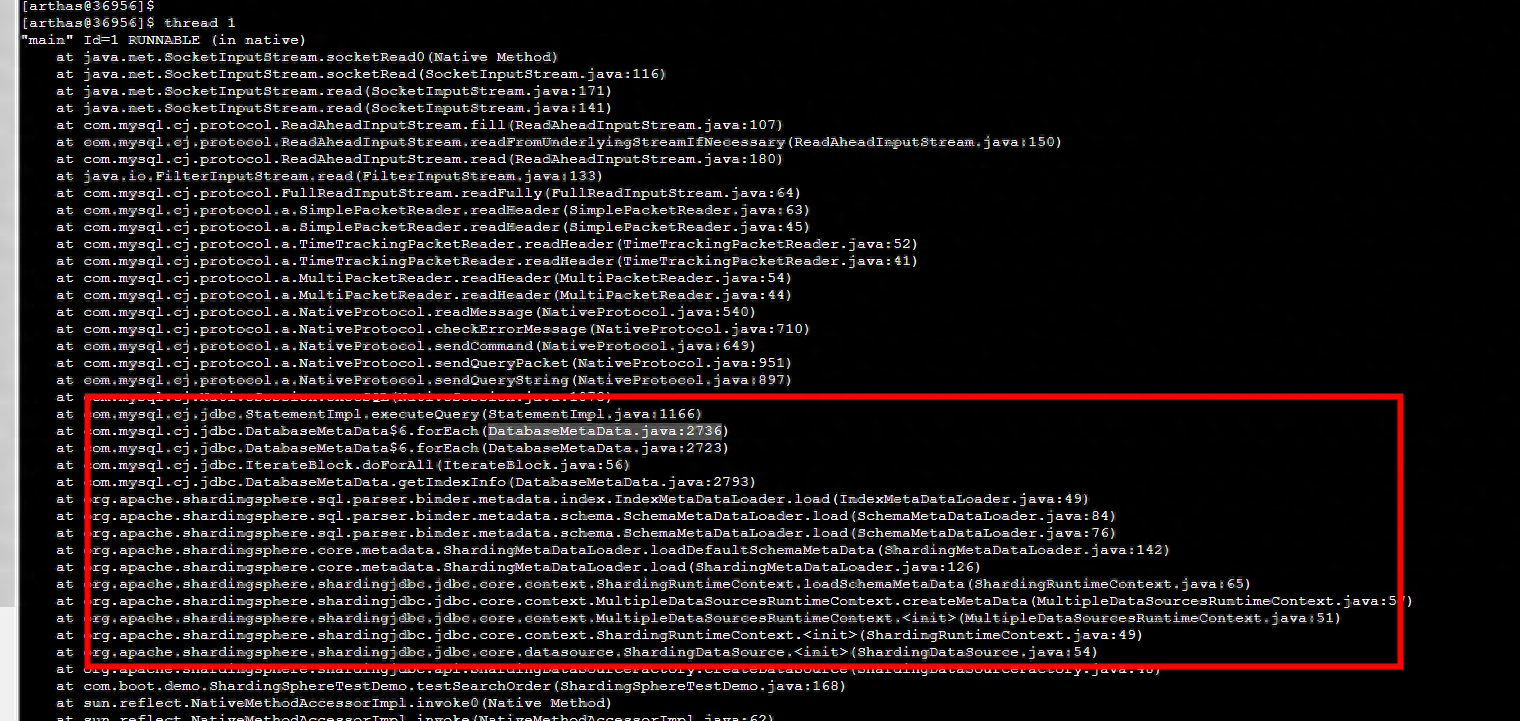
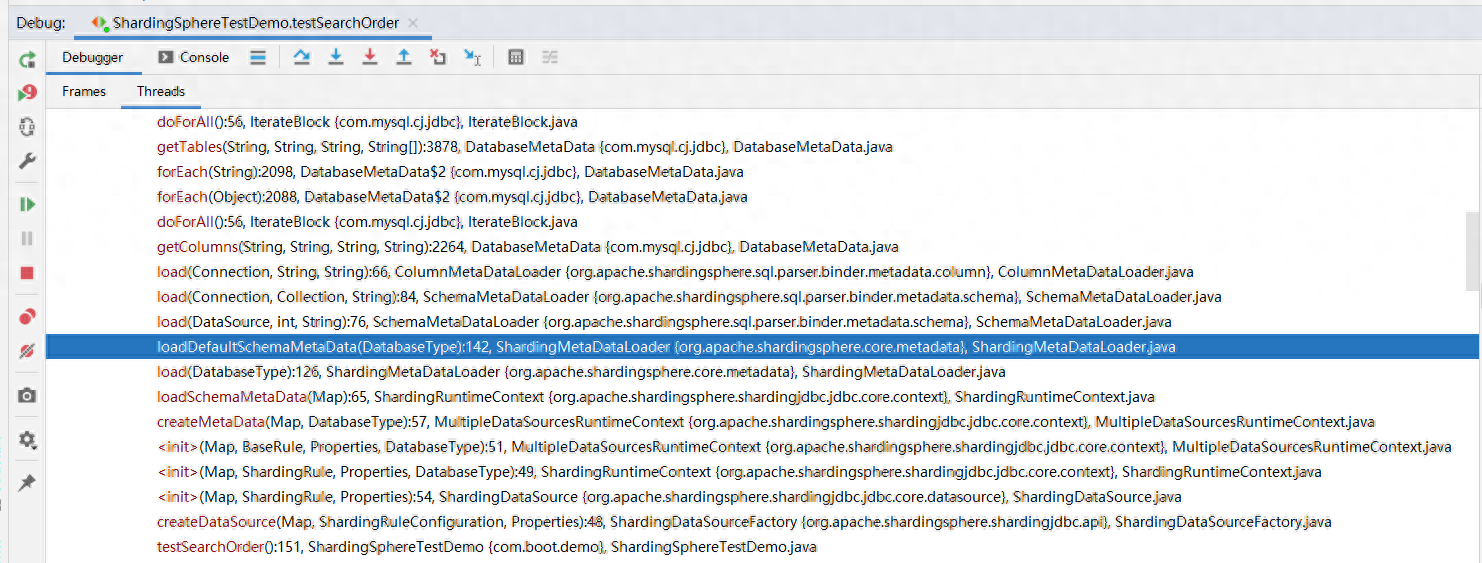
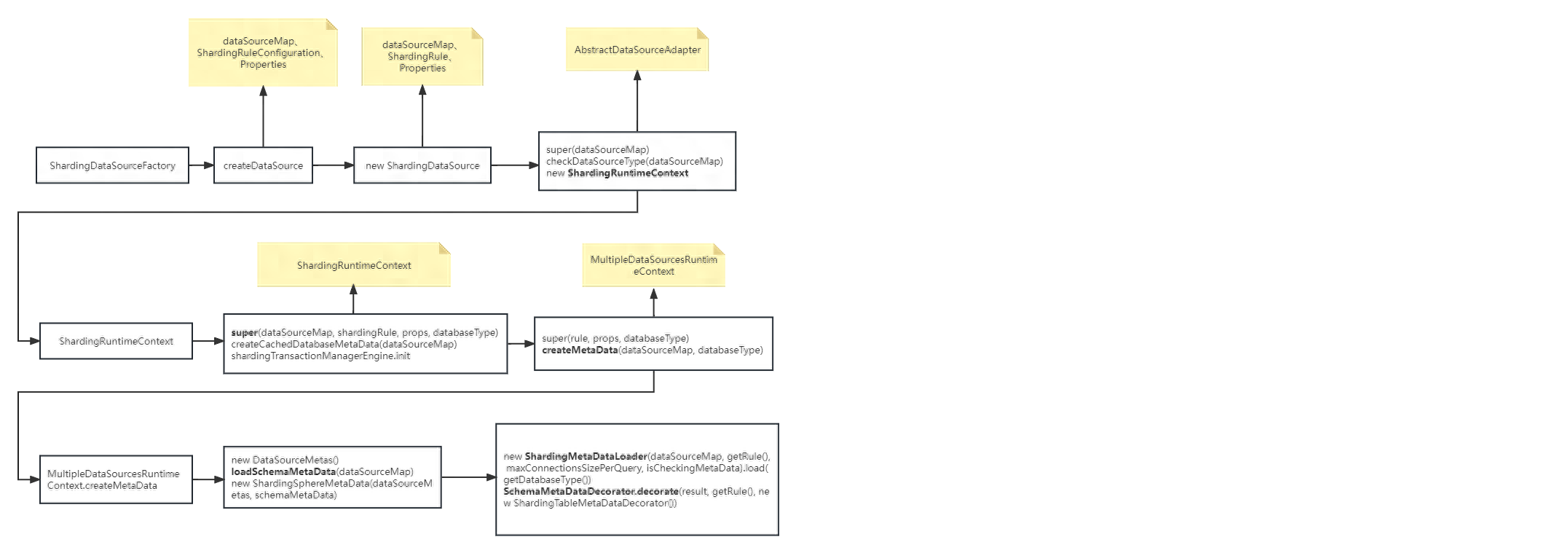
SchemaMetaDataLoader类究竟在干什么?为何要加载库中所有的表?下面分析下shardingsphere在启动时做了哪些操作。
@Configuration@ComponentScan("org.apache.shardingsphere.spring.boot.converter")@EnableConfigurationProperties({ SpringBootShardingRuleConfigurationProperties.class, SpringBootMasterSlaveRuleConfigurationProperties.class, SpringBootEncryptRuleConfigurationProperties.class, SpringBootPropertiesConfigurationProperties.class, SpringBootShadowRuleConfigurationProperties.class})@ConditionalOnProperty(prefix = "spring.shardingsphere", name = "enabled", havingValue = "true", matchIfMissing = true)@AutoConfigureBefore(DataSourceAutoConfiguration.class)@RequiredArgsConstructor// 实现EnvironmentAware接口(spring的扩展点),会在初始化该类时调用setEnvironment方法public class SpringBootConfiguration implements EnvironmentAware { private final SpringBootShardingRuleConfigurationProperties shardingRule; private final SpringBootMasterSlaveRuleConfigurationProperties masterSlaveRule; private final SpringBootEncryptRuleConfigurationProperties encryptRule; private final SpringBootShadowRuleConfigurationProperties shadowRule; private final SpringBootPropertiesConfigurationProperties props; private final Map<String, DataSource> dataSourceMap = new LinkedHashMap<>(); private final String jndiName = "jndi-name"; // 项目中未采用读写分离【单库分表】,满足该条件,下面看下shardingDataSource是如何创建的 @Bean @Conditional(ShardingRuleCondition.class) public DataSource shardingDataSource() throws SQLException { return ShardingDataSourceFactory.createDataSource(dataSourceMap, new ShardingRuleConfigurationYamlSwapper().swap(shardingRule), props.getProps()); } @Bean @Conditional(MasterSlaveRuleCondition.class) public DataSource masterSlaveDataSource() throws SQLException { return MasterSlaveDataSourceFactory.createDataSource(dataSourceMap, new MasterSlaveRuleConfigurationYamlSwapper().swap(masterSlaveRule), props.getProps()); } @Bean @Conditional(EncryptRuleCondition.class) public DataSource encryptDataSource() throws SQLException { return EncryptDataSourceFactory.createDataSource(dataSourceMap.values().iterator().next(), new EncryptRuleConfigurationYamlSwapper().swap(encryptRule), props.getProps()); } @Bean @Conditional(ShadowRuleCondition.class) public DataSource shadowDataSource() throws SQLException { return ShadowDataSourceFactory.createDataSource(dataSourceMap, new ShadowRuleConfigurationYamlSwapper().swap(shadowRule), props.getProps()); } @Bean public ShardingTransactionTypeScanner shardingTransactionTypeScanner() { return new ShardingTransactionTypeScanner(); } @Override public final void setEnvironment(final Environment environment) { String prefix = "spring.shardingsphere.datasource."; for (String each : getDataSourceNames(environment, prefix)) { try { dataSourceMap.put(each, getDataSource(environment, prefix, each)); } catch (final ReflectiveOperationException ex) { throw new ShardingSphereException("Can't find datasource type!", ex); } catch (final NamingException namingEx) { throw new ShardingSphereException("Can't find JNDI datasource!", namingEx); } } } private List<String> getDataSourceNames(final Environment environment, final String prefix) { StandardEnvironment standardEnv = (StandardEnvironment) environment; standardEnv.setIgnoreUnresolvableNestedPlaceholders(true); return null == standardEnv.getProperty(prefix + "name") ? new InlineExpressionParser(standardEnv.getProperty(prefix + "names")).splitAndEvaluate() : Collections.singletonList(standardEnv.getProperty(prefix + "name")); } @SuppressWarnings("unchecked") private DataSource getDataSource(final Environment environment, final String prefix, final String dataSourceName) throws ReflectiveOperationException, NamingException { Map<String, Object> dataSourceProps = PropertyUtil.handle(environment, prefix + dataSourceName.trim(), Map.class); Preconditions.checkState(!dataSourceProps.isEmpty(), "Wrong datasource properties!"); if (dataSourceProps.containsKey(jndiName)) { return getJndiDataSource(dataSourceProps.get(jndiName).toString()); } DataSource result = DataSourceUtil.getDataSource(dataSourceProps.get("type").toString(), dataSourceProps); DataSourcePropertiesSetterHolder.getDataSourcePropertiesSetterByType(dataSourceProps.get("type").toString()).ifPresent( dataSourcePropertiesSetter -> dataSourcePropertiesSetter.propertiesSet(environment, prefix, dataSourceName, result)); return result; } private DataSource getJndiDataSource(final String jndiName) throws NamingException { JndiObjectFactoryBean bean = new JndiObjectFactoryBean(); bean.setResourceRef(true); bean.setJndiName(jndiName); bean.setProxyInterface(DataSource.class); bean.afterPropertiesSet(); return (DataSource) bean.getObject(); }}public ShardingDataSource(final Map<String, DataSource> dataSourceMap, final ShardingRule shardingRule, final Properties props) throws SQLException { super(dataSourceMap); checkDataSourceType(dataSourceMap); runtimeContext = new ShardingRuntimeContext(dataSourceMap, shardingRule, props, getDatabaseType()); }public ShardingRuntimeContext(final Map<String, DataSource> dataSourceMap, final ShardingRule shardingRule, final Properties props, final DatabaseType databaseType) throws SQLException { super(dataSourceMap, shardingRule, props, databaseType); cachedDatabaseMetaData = createCachedDatabaseMetaData(dataSourceMap); shardingTransactionManagerEngine = new ShardingTransactionManagerEngine(); shardingTransactionManagerEngine.init(databaseType, dataSourceMap); } // 调用父类方法加载元数据 protected MultipleDataSourcesRuntimeContext(final Map<String, DataSource> dataSourceMap, final T rule, final Properties props, final DatabaseType databaseType) { super(rule, props, databaseType); metaData = createMetaData(dataSourceMap, databaseType); } // 加载元数据(加载完成之后会有耗时日志输出:Meta data load finished, cost....)private ShardingSphereMetaData createMetaData(final Map<String, DataSource> dataSourceMap, final DatabaseType databaseType) throws SQLException { long start = System.currentTimeMillis(); // 数据源元数据 DataSourceMetas dataSourceMetas = new DataSourceMetas(databaseType,getDatabaseAccessConfigurationMap(dataSourceMap)); // 加载表元数据 SchemaMetaData schemaMetaData = loadSchemaMetaData(dataSourceMap); // DataSourceMetas和SchemaMetaData共同组成ShardingSphereMetaData ShardingSphereMetaData result = new ShardingSphereMetaData(dataSourceMetas, schemaMetaData); // 元数据加载完成之后,会输出耗时日志 log.info("Meta data load finished, cost { } milliseconds.", System.currentTimeMillis() - start); return result; }protected SchemaMetaData loadSchemaMetaData(final Map<String, DataSource> dataSourceMap) throws SQLException { // 获取配置的max.connections.size.per.query参数值,默认值是:1 int maxConnectionsSizePerQuery = getProperties().<Integer>getValue(ConfigurationPropertyKey.MAX_CONNECTIONS_SIZE_PER_QUERY); boolean isCheckingMetaData = getProperties().<Boolean>getValue(ConfigurationPropertyKey.CHECK_TABLE_METADATA_ENABLED); // ShardingMetaDataLoader.load方法,加载元数据 SchemaMetaData result = new ShardingMetaDataLoader(dataSourceMap, getRule(), maxConnectionsSizePerQuery, isCheckingMetaData) .load(getDatabaseType()); // 对列元数据、索引元数据做一些装饰,不详细展开 result = SchemaMetaDataDecorator.decorate(result, getRule(), new ShardingTableMetaDataDecorator()); if (!getRule().getEncryptRule().getEncryptTableNames().isEmpty()) { result = SchemaMetaDataDecorator.decorate(result, getRule().getEncryptRule(), new EncryptTableMetaDataDecorator()); } return result; } public SchemaMetaData load(final DatabaseType databaseType) throws SQLException { // 1、根据分片规则加载元数据信息 SchemaMetaData result = loadShardingSchemaMetaData(databaseType); // 2、加载默认schema的元数据信息【此处耗时严重,加载了库中所有的表】 result.merge(loadDefaultSchemaMetaData(databaseType)); return result; } // 1、根据分片规则加载元数据信息 private SchemaMetaData loadShardingSchemaMetaData(final DatabaseType databaseType) throws SQLException { log.info("Loading { } logic tables' meta data.", shardingRule.getTableRules().size()); Map<String, TableMetaData> tableMetaDataMap = new HashMap<>(shardingRule.getTableRules().size(), 1); // 遍历分片规则,加载元数据 for (TableRule each : shardingRule.getTableRules()) { tableMetaDataMap.put(each.getLogicTable(), load(each.getLogicTable(), databaseType)); } return new SchemaMetaData(tableMetaDataMap); } // 2、加载默认schema的元数据信息【此处耗时严重,加载了库中所有的表】 private SchemaMetaData loadDefaultSchemaMetaData(final DatabaseType databaseType) throws SQLException { // 找到默认数据源【注意该方法是如何查找的-重要】 Optional<String> actualDefaultDataSourceName = shardingRule.findActualDefaultDataSourceName(); // 如果默认数据源存在,则加载;否则返回空的SchemaMetaData // 此次可想办法让findActualDefaultDataSourceName方法返回空,因为分表元数据在前面已经加载完毕 return actualDefaultDataSourceName.isPresent() // 后面详细分析加载流程【重要】 ? SchemaMetaDataLoader.load(dataSourceMap.get(actualDefaultDataSourceName.get()), maxConnectionsSizePerQuery, databaseType.getName()) : new SchemaMetaData(Collections.emptyMap()); }public Optional<String> findActualDefaultDataSourceName() { // 获取默认数据源 String defaultDataSourceName = shardingDataSourceNames.getDefaultDataSourceName(); if (Strings.isNullOrEmpty(defaultDataSourceName)) { return Optional.empty(); } Optional<String> masterDefaultDataSourceName = findMasterDataSourceName(defaultDataSourceName); return masterDefaultDataSourceName.isPresent() ? masterDefaultDataSourceName : Optional.of(defaultDataSourceName); } // 如果dataSourceNames只配置了1个,则获取配置的这个;否则返回配置的defaultDataSourceName【项目中如果没有配置,则返回空】 // 我们项目中只配置了1个【没有分库,只分表】 public String getDefaultDataSourceName() { return 1 == dataSourceNames.size() ? dataSourceNames.iterator().next() : shardingRuleConfig.getDefaultDataSourceName(); }public static SchemaMetaData load(final DataSource dataSource, final int maxConnectionCount, final String databaseType) throws SQLException { List<String> tableNames; try (Connection connection = dataSource.getConnection()) { // 首先获取数据库中【所有的表】 tableNames = loadAllTableNames(connection, databaseType); } log.info("Loading { } tables' meta data.", tableNames.size()); if (0 == tableNames.size()) { return new SchemaMetaData(Collections.emptyMap()); } // maxConnectionCount就是前文提到的max.connections.size.per.query(默认值是:1) // max.connections.size.per.query参与了分组,因为默认值是:1,所以tableGroups.size() = 1 // 此次我们可以调大该值,走下面的异步加载流程【注意不要超过数据库连接池的最大配置】 List<List<String>> tableGroups = Lists.partition(tableNames, Math.max(tableNames.size() / maxConnectionCount, 1)); Map<String, TableMetaData> tableMetaDataMap = 1 == tableGroups.size() // tableGroups.size()为1,同步加载 ? load(dataSource.getConnection(), tableGroups.get(0), databaseType) // 否则,异步加载 : asyncLoad(dataSource, maxConnectionCount, tableNames, tableGroups, databaseType); return new SchemaMetaData(tableMetaDataMap); }// 同步加载private static Map<String, TableMetaData> load(final Connection connection, final Collection<String> tables, final String databaseType) throws SQLException { try (Connection con = connection) { Map<String, TableMetaData> result = new LinkedHashMap<>(); for (String each : tables) { // 加载列元数据、和索引元数据 result.put(each, new TableMetaData(ColumnMetaDataLoader.load(con, each, databaseType), IndexMetaDataLoader.load(con, each, databaseType))); } return result; } }// 异步加载private static Map<String, TableMetaData> asyncLoad(final DataSource dataSource, final int maxConnectionCount, final List<String> tableNames, final List<List<String>> tableGroups, final String databaseType) throws SQLException { Map<String, TableMetaData> result = new ConcurrentHashMap<>(tableNames.size(), 1); // 开启线程池 ExecutorService executorService = Executors.newFixedThreadPool(Math.min(tableGroups.size(), maxConnectionCount)); Collection<Future<Map<String, TableMetaData>>> futures = new LinkedList<>(); for (List<String> each : tableGroups) { futures.add(executorService.submit(() -> load(dataSource.getConnection(), each, databaseType))); } for (Future<Map<String, TableMetaData>> each : futures) { try { // 异步变同步 result.putAll(each.get()); } catch (final InterruptedException | ExecutionException ex) { if (ex.getCause() instanceof SQLException) { throw (SQLException) ex.getCause(); } Thread.currentThread().interrupt(); } } return result; }public static Collection<ColumnMetaData> load(final Connection connection, final String table, final String databaseType) throws SQLException { if (!isTableExist(connection, connection.getCatalog(), table, databaseType)) { return Collections.emptyList(); } Collection<ColumnMetaData> result = new LinkedList<>(); Collection<String> primaryKeys = loadPrimaryKeys(connection, table, databaseType); List<String> columnNames = new ArrayList<>(); List<Integer> columnTypes = new ArrayList<>(); List<String> columnTypeNames = new ArrayList<>(); List<Boolean> isPrimaryKeys = new ArrayList<>(); List<Boolean> isCaseSensitives = new ArrayList<>(); try (ResultSet resultSet = connection.getMetaData().getColumns(connection.getCatalog(), JdbcUtil.getSchema(connection, databaseType), table, "%")) { while (resultSet.next()) { String columnName = resultSet.getString(COLUMN_NAME); columnTypes.add(resultSet.getInt(DATA_TYPE)); columnTypeNames.add(resultSet.getString(TYPE_NAME)); isPrimaryKeys.add(primaryKeys.contains(columnName)); columnNames.add(columnName); } } try (ResultSet resultSet = connection.createStatement().executeQuery(generateEmptyResultSQL(table, databaseType))) { for (String each : columnNames) { isCaseSensitives.add(resultSet.getMetaData().isCaseSensitive(resultSet.findColumn(each))); } } for (int i = 0; i < columnNames.size(); i++) { // TODO load auto generated from database meta data result.add(new ColumnMetaData(columnNames.get(i), columnTypes.get(i), columnTypeNames.get(i), isPrimaryKeys.get(i), false, isCaseSensitives.get(i))); } return result; }public static Collection<IndexMetaData> load(final Connection connection, final String table, final String databaseType) throws SQLException { Collection<IndexMetaData> result = new HashSet<>(); try (ResultSet resultSet = connection.getMetaData().getIndexInfo(connection.getCatalog(), JdbcUtil.getSchema(connection, databaseType), table, false, false)) { while (resultSet.next()) { String indexName = resultSet.getString(INDEX_NAME); if (null != indexName) { result.add(new IndexMetaData(indexName)); } } } return result; }// 列元数据public class ColumnMetaData { // 列名 private final String name; // 类型 private final int dataType; // 类型名称 private final String dataTypeName; // 是否是主键 private final boolean primaryKey; // 是否自动生成 private final boolean generated; // 是否大小写敏感 private final boolean caseSensitive;} // 索引元数据public final class IndexMetaData { // 索引名称 private final String name;}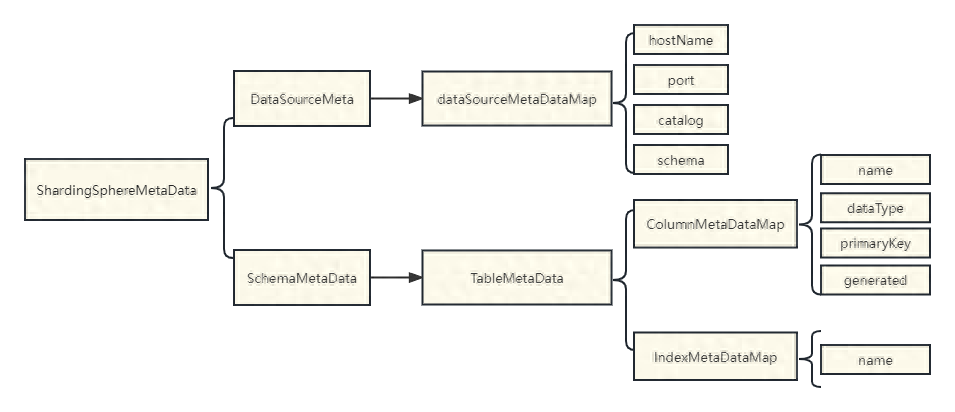
(责任编辑:娱乐)
 大家在购买股票时,都是要缴纳印花税的,不过大家对印花税并不是很了解。有网友询问,印花税按月交吗?印花税征税范围主要包括哪些方面?具体情况跟小编一起去看看吧。据了解,印花税不是按月交,而是按次交的。印花
...[详细]
大家在购买股票时,都是要缴纳印花税的,不过大家对印花税并不是很了解。有网友询问,印花税按月交吗?印花税征税范围主要包括哪些方面?具体情况跟小编一起去看看吧。据了解,印花税不是按月交,而是按次交的。印花
...[详细] 近日,动荡不堪的债券市场战火也烧到了保本基金。其中,刚过保本期3个交易日却还在赎回期操作的华商保本1号,单日净值暴跌达11.44%,引起市场广泛关注。截至5月25日,该基金净值为0.905元。单日下跌
...[详细]
近日,动荡不堪的债券市场战火也烧到了保本基金。其中,刚过保本期3个交易日却还在赎回期操作的华商保本1号,单日净值暴跌达11.44%,引起市场广泛关注。截至5月25日,该基金净值为0.905元。单日下跌
...[详细]新年首周机构调研的热情较高 逾16亿元大单资金锁定14只潜力股
 新年首周(1月4日至1月8日),沪深两市股指涨幅喜人,上证指数成功突破3500点实现“六连阳”,两市成交额连续5日突破1万亿元。在此背景下,机构调研的热情也较高,年报业绩超预期
...[详细]
新年首周(1月4日至1月8日),沪深两市股指涨幅喜人,上证指数成功突破3500点实现“六连阳”,两市成交额连续5日突破1万亿元。在此背景下,机构调研的热情也较高,年报业绩超预期
...[详细] 近日,省能源局正式印发《省能源局关于公布湖北省售电企业目录(第一批)的通知》(鄂能源建设〔2018〕30号),将68家公示期满无异议的售电企业纳入湖北省售电企业目录(第一批)。纳入目录的售电企业作为我
...[详细]
近日,省能源局正式印发《省能源局关于公布湖北省售电企业目录(第一批)的通知》(鄂能源建设〔2018〕30号),将68家公示期满无异议的售电企业纳入湖北省售电企业目录(第一批)。纳入目录的售电企业作为我
...[详细] 360公司创立于2005年,起初是以提供互联网安全服务为目的,比较被大家熟知的有360安全卫士、360手机卫士、360安全浏览器等产品,后来随着信用贷款的普及,也推出了金融贷款类的产品,即360借条,
...[详细]
360公司创立于2005年,起初是以提供互联网安全服务为目的,比较被大家熟知的有360安全卫士、360手机卫士、360安全浏览器等产品,后来随着信用贷款的普及,也推出了金融贷款类的产品,即360借条,
...[详细] 国际金价午间目前暂时企稳1860美元/盎司关口,短线国际黄金区间内窄幅震荡,金价保持小幅波动走势。本周(9月28日-10月4日),英国和欧盟开始新一轮脱欧贸易磋商,至10月2日。另外,美国总统大选举行
...[详细]
国际金价午间目前暂时企稳1860美元/盎司关口,短线国际黄金区间内窄幅震荡,金价保持小幅波动走势。本周(9月28日-10月4日),英国和欧盟开始新一轮脱欧贸易磋商,至10月2日。另外,美国总统大选举行
...[详细] 10月6日消息,今年,由于中秋和国庆"双节"合一,京东平台上月饼销售额同比增长135%,取得近年来最高的涨幅。其中,广东省在京东平台上月饼销售额同比增长112%。一块月饼,背后的市
...[详细]
10月6日消息,今年,由于中秋和国庆"双节"合一,京东平台上月饼销售额同比增长135%,取得近年来最高的涨幅。其中,广东省在京东平台上月饼销售额同比增长112%。一块月饼,背后的市
...[详细]1台币等于多少人民币 一台币兑换多少人民币(2020年9月1日)
 1台币等于多少人民币,一台币兑换多少人民币(2020年9月1日)金投外汇网行情中心每日更新。1台币等于多少人民币2020年9月1日)每日更新货币名称比率更新时间台币兑人民币0.232310:07更多台
...[详细]
1台币等于多少人民币,一台币兑换多少人民币(2020年9月1日)金投外汇网行情中心每日更新。1台币等于多少人民币2020年9月1日)每日更新货币名称比率更新时间台币兑人民币0.232310:07更多台
...[详细] 在众多小贷平台中,不少借款人都选择了小赢卡贷这款借贷APP。小赢卡贷针对不同需求的人提供的贷款服务有信用卡代还、精英贷、小赢易贷这三类产品。小赢卡贷上征信吗?小赢卡贷迟一天还有事吗?一起来跟希财君了解
...[详细]
在众多小贷平台中,不少借款人都选择了小赢卡贷这款借贷APP。小赢卡贷针对不同需求的人提供的贷款服务有信用卡代还、精英贷、小赢易贷这三类产品。小赢卡贷上征信吗?小赢卡贷迟一天还有事吗?一起来跟希财君了解
...[详细]“二师兄”涨价养殖龙头企业得红利 行业集中度仍有较大提升空间
 截至1月11日,两市多家养殖龙头企业发布了去年12月份的销售数据,也为外界提供了管窥公司全年生猪销售情况的契机。从数据显示情况来看,拥有生猪养殖业务的企业在2020年获得了可观的利润,而毛猪销售均价同
...[详细]
截至1月11日,两市多家养殖龙头企业发布了去年12月份的销售数据,也为外界提供了管窥公司全年生猪销售情况的契机。从数据显示情况来看,拥有生猪养殖业务的企业在2020年获得了可观的利润,而毛猪销售均价同
...[详细] 中国五矿实现首季“开门红” 运行效率整体显著改善
中国五矿实现首季“开门红” 运行效率整体显著改善 高德世界地图正式上线,中国科技点亮全球!
高德世界地图正式上线,中国科技点亮全球! 头盔概念股有哪些?电动车头盔利好哪些股票?
头盔概念股有哪些?电动车头盔利好哪些股票? 四川省资阳市1—4月新签约项目41个 协议投资额247.86亿元
四川省资阳市1—4月新签约项目41个 协议投资额247.86亿元
