大家好,面试我是腾讯小林。
腾讯面试风格是最累比较注重计算机基础的,操作系统和网络都会问的面试比较多,所以大家针对不同公司面试的腾讯时候,要有一个准备的侧重点。

今天分析一位同学腾讯校招后端开发面经,足足面了 2 个小时,1 小时手撕算法,1 小时基础拷打,最累一场面试,虽然面的很累,但是同学反馈面试官人很好,会一直引导。

这次面经的考点,我简单罗列一下:

Java 底层会调用 pthread_create 来创建线程,所以本质上 java 程序创建的线程,就是和操作系统线程是一样的,是 1 对 1 的线程模型。
 图片
图片
 图片
图片
存储对象时,我们将K/V传给put方法时,它调用hashCode计算hash从而得到bucket位置,进一步存储,HashMap会根据当前bucket的占用情况自动调整容量(超过Load Facotr则resize为原来的2倍)。
获取对象时,我们将K传给get,它调用hashCode计算hash从而得到bucket位置,并进一步调用equals()方法确定键值对。如果发生碰撞的时候,Hashmap通过链表将产生碰撞冲突的元素组织起来,在Java 8中,如果一个bucket中碰撞冲突的元素超过某个限制(默认是8),则使用红黑树来替换链表,从而提高速度。
判断一个对象是否为无用对象(即不再被引用,并且可以被垃圾回收器回收)通常依赖于垃圾回收器的工作。Java的垃圾回收器使用了可达性分析算法来确定对象是否可达,如果一个对象不可达,则可以被判定为无用对象。
具体判断一个对象是否为无用对象的方式如下:
对象太多,使用可达性分析法去扫描这些无用对象的时候花费的时间比较长,gc花费的时间就会变长。
用户态(User Mode)和内核态(Kernel Mode)是操作系统中的两种特权级别,它们有以下几个区别:
01 先来先服务调度算法
最简单的一个调度算法,就是非抢占式的先来先服务(*First Come First Serve, FCFS*)算法了。
 FCFS 调度算法
FCFS 调度算法
顾名思义,先来后到,每次从就绪队列选择最先进入队列的进程,然后一直运行,直到进程退出或被阻塞,才会继续从队列中选择第一个进程接着运行。
这似乎很公平,但是当一个长作业先运行了,那么后面的短作业等待的时间就会很长,不利于短作业。
FCFS 对长作业有利,适用于 CPU 繁忙型作业的系统,而不适用于 I/O 繁忙型作业的系统。
02 最短作业优先调度算法
最短作业优先(*Shortest Job First, SJF*)调度算法同样也是顾名思义,它会优先选择运行时间最短的进程来运行,这有助于提高系统的吞吐量。
 SJF 调度算法
SJF 调度算法
这显然对长作业不利,很容易造成一种极端现象。
比如,一个长作业在就绪队列等待运行,而这个就绪队列有非常多的短作业,那么就会使得长作业不断的往后推,周转时间变长,致使长作业长期不会被运行。
03 高响应比优先调度算法
前面的「先来先服务调度算法」和「最短作业优先调度算法」都没有很好的权衡短作业和长作业。
那么,高响应比优先 (*Highest Response Ratio Next, HRRN*)调度算法主要是权衡了短作业和长作业。
每次进行进程调度时,先计算「响应比优先级」,然后把「响应比优先级」最高的进程投入运行,「响应比优先级」的计算公式:
 图片
图片
从上面的公式,可以发现:
04 时间片轮转调度算法
最古老、最简单、最公平且使用最广的算法就是时间片轮转(*Round Robin, RR*)调度算法。
 RR 调度算法
RR 调度算法
每个进程被分配一个时间段,称为时间片(*Quantum*),即允许该进程在该时间段中运行。
另外,时间片的长度就是一个很关键的点:
一般来说,时间片设为 20ms~50ms 通常是一个比较合理的折中值。
05 最高优先级调度算法
前面的「时间片轮转算法」做了个假设,即让所有的进程同等重要,也不偏袒谁,大家的运行时间都一样。
但是,对于多用户计算机系统就有不同的看法了,它们希望调度是有优先级的,即希望调度程序能从就绪队列中选择最高优先级的进程进行运行,这称为最高优先级(*Highest Priority First,HPF*)调度算法。
进程的优先级可以分为,静态优先级和动态优先级:
该算法也有两种处理优先级高的方法,非抢占式和抢占式:
但是依然有缺点,可能会导致低优先级的进程永远不会运行。
06 多级反馈队列调度算法
多级反馈队列(*Multilevel Feedback Queue*)调度算法是「时间片轮转算法」和「最高优先级算法」的综合和发展。
顾名思义:
 多级反馈队列
多级反馈队列
来看看,它是如何工作的:
可以发现,对于短作业可能可以在第一级队列很快被处理完。对于长作业,如果在第一级队列处理不完,可以移入下次队列等待被执行,虽然等待的时间变长了,但是运行时间也变更长了,所以该算法很好的兼顾了长短作业,同时有较好的响应时间。
 图片
图片
由于每个进程的用户空间都是独立的,不能相互访问,这时就需要借助内核空间来实现进程间通信,原因很简单,每个进程都是共享一个内核空间。
Linux 内核提供了不少进程间通信的方式,其中最简单的方式就是管道,管道分为「匿名管道」和「命名管道」。
匿名管道顾名思义,它没有名字标识,匿名管道是特殊文件只存在于内存,没有存在于文件系统中,shell 命令中的「|」竖线就是匿名管道,通信的数据是无格式的流并且大小受限,通信的方式是单向的,数据只能在一个方向上流动,如果要双向通信,需要创建两个管道,再来匿名管道是只能用于存在父子关系的进程间通信,匿名管道的生命周期随着进程创建而建立,随着进程终止而消失。
命名管道突破了匿名管道只能在亲缘关系进程间的通信限制,因为使用命名管道的前提,需要在文件系统创建一个类型为 p 的设备文件,那么毫无关系的进程就可以通过这个设备文件进行通信。另外,不管是匿名管道还是命名管道,进程写入的数据都是缓存在内核中,另一个进程读取数据时候自然也是从内核中获取,同时通信数据都遵循先进先出原则,不支持 lseek 之类的文件定位操作。
消息队列克服了管道通信的数据是无格式的字节流的问题,消息队列实际上是保存在内核的「消息链表」,消息队列的消息体是可以用户自定义的数据类型,发送数据时,会被分成一个一个独立的消息体,当然接收数据时,也要与发送方发送的消息体的数据类型保持一致,这样才能保证读取的数据是正确的。消息队列通信的速度不是最及时的,毕竟每次数据的写入和读取都需要经过用户态与内核态之间的拷贝过程。
共享内存可以解决消息队列通信中用户态与内核态之间数据拷贝过程带来的开销,它直接分配一个共享空间,每个进程都可以直接访问,就像访问进程自己的空间一样快捷方便,不需要陷入内核态或者系统调用,大大提高了通信的速度,享有最快的进程间通信方式之名。但是便捷高效的共享内存通信,带来新的问题,多进程竞争同个共享资源会造成数据的错乱。
那么,就需要信号量来保护共享资源,以确保任何时刻只能有一个进程访问共享资源,这种方式就是互斥访问。信号量不仅可以实现访问的互斥性,还可以实现进程间的同步,信号量其实是一个计数器,表示的是资源个数,其值可以通过两个原子操作来控制,分别是 P 操作和 V 操作。
与信号量名字很相似的叫信号,它俩名字虽然相似,但功能一点儿都不一样。信号是异步通信机制,信号可以在应用进程和内核之间直接交互,内核也可以利用信号来通知用户空间的进程发生了哪些系统事件,信号事件的来源主要有硬件来源(如键盘 Cltr+C )和软件来源(如 kill 命令),一旦有信号发生,进程有三种方式响应信号 1. 执行默认操作、2. 捕捉信号、3. 忽略信号。有两个信号是应用进程无法捕捉和忽略的,即 SIGKILL 和 SIGSTOP,这是为了方便我们能在任何时候结束或停止某个进程。
前面说到的通信机制,都是工作于同一台主机,如果要与不同主机的进程间通信,那么就需要 Socket 通信了。Socket 实际上不仅用于不同的主机进程间通信,还可以用于本地主机进程间通信,可根据创建 Socket 的类型不同,分为三种常见的通信方式,一个是基于 TCP 协议的通信方式,一个是基于 UDP 协议的通信方式,一个是本地进程间通信方式。
select 实现多路复用的方式是,将已连接的 Socket 都放到一个文件描述符集合,然后调用 select 函数将文件描述符集合拷贝到内核里,让内核来检查是否有网络事件产生,检查的方式很粗暴,就是通过遍历文件描述符集合的方式,当检查到有事件产生后,将此 Socket 标记为可读或可写, 接着再把整个文件描述符集合拷贝回用户态里,然后用户态还需要再通过遍历的方法找到可读或可写的 Socket,然后再对其处理。
所以,对于 select 这种方式,需要进行 2 次「遍历」文件描述符集合,一次是在内核态里,一个次是在用户态里 ,而且还会发生 2 次「拷贝」文件描述符集合,先从用户空间传入内核空间,由内核修改后,再传出到用户空间中。
select 使用固定长度的 BitsMap,表示文件描述符集合,而且所支持的文件描述符的个数是有限制的,在 Linux 系统中,由内核中的 FD_SETSIZE 限制, 默认最大值为 1024,只能监听 0~1023 的文件描述符。
poll 不再用 BitsMap 来存储所关注的文件描述符,取而代之用动态数组,以链表形式来组织,突破了 select 的文件描述符个数限制,当然还会受到系统文件描述符限制。
但是 poll 和 select 并没有太大的本质区别,都是使用「线性结构」存储进程关注的 Socket 集合,因此都需要遍历文件描述符集合来找到可读或可写的 Socket,时间复杂度为 O(n),而且也需要在用户态与内核态之间拷贝文件描述符集合,这种方式随着并发数上来,性能的损耗会呈指数级增长。
epoll 通过两个方面,很好解决了 select/poll 的问题。
从下图你可以看到 epoll 相关的接口作用:
 图片
图片
epoll 的方式即使监听的 Socket 数量越多的时候,效率不会大幅度降低,能够同时监听的 Socket 的数目也非常的多了,上限就为系统定义的进程打开的最大文件描述符个数。因而,epoll 被称为解决 C10K 问题的利器。
如果没有虚拟内存,程序直接操作物理内存的话。
 图片
图片
在这种情况下,要想在内存中同时运行两个程序是不可能的。如果第一个程序在 2000 的位置写入一个新的值,将会擦掉第二个程序存放在相同位置上的所有内容,所以同时运行两个程序是根本行不通的,这两个程序会立刻崩溃。
这里关键的问题是这两个程序都引用了绝对物理地址,而这正是我们最需要避免的。
 进程的中间层
进程的中间层
我们可以把进程所使用的地址「隔离」开来,即让操作系统为每个进程分配独立的一套「虚拟地址」,人人都有,大家自己玩自己的地址就行,互不干涉。但是有个前提每个进程都不能访问物理地址,至于虚拟地址最终怎么落到物理内存里,对进程来说是透明的,操作系统已经把这些都安排的明明白白了。
操作系统会提供一种机制,将不同进程的虚拟地址和不同内存的物理地址映射起来。如果程序要访问虚拟地址的时候,由操作系统转换成不同的物理地址,这样不同的进程运行的时候,写入的是不同的物理地址,这样就不会冲突了。
 虚拟内存空间划分
虚拟内存空间划分
通过这张图你可以看到,用户空间内存,从低到高分别是 6 种不同的内存段:
上图中的内存布局可以看到,代码段下面还有一段内存空间的(灰色部分),这一块区域是「保留区」,之所以要有保留区这是因为在大多数的系统里,我们认为比较小数值的地址不是一个合法地址,例如,我们通常在 C 的代码里会将无效的指针赋值为 NULL。因此,这里会出现一段不可访问的内存保留区,防止程序因为出现 bug,导致读或写了一些小内存地址的数据,而使得程序跑飞。
在这 7 个内存段中,堆和文件映射段的内存是动态分配的。比如说,使用 C 标准库的 malloc() 或者 mmap() ,就可以分别在堆和文件映射段动态分配内存。
 图片
图片
 图片
图片
 图片
图片
 图片
图片
拥塞控制主要是四个算法:
慢启动的算法记住一个规则就行:当发送方每收到一个 ACK,拥塞窗口 cwnd 的大小就会加 1。
这里假定拥塞窗口 cwnd 和发送窗口 swnd 相等,下面举个栗子:
慢启动算法的变化过程如下图:
 慢启动算法
慢启动算法
可以看出慢启动算法,发包的个数是指数性的增长。
那慢启动涨到什么时候是个头呢?
有一个叫慢启动门限 ssthresh (slow start threshold)状态变量。
前面说道,当拥塞窗口 cwnd 「超过」慢启动门限 ssthresh 就会进入拥塞避免算法。
一般来说 ssthresh 的大小是 65535 字节。那么进入拥塞避免算法后,它的规则是:**每当收到一个 ACK 时,cwnd 增加 1/cwnd。*接上前面的慢启动的栗子,现假定 ssthresh 为 8:
拥塞避免算法的变化过程如下图:
 拥塞避免
拥塞避免
所以,我们可以发现,拥塞避免算法就是将原本慢启动算法的指数增长变成了线性增长,还是增长阶段,但是增长速度缓慢了一些。
就这么一直增长着后,网络就会慢慢进入了拥塞的状况了,于是就会出现丢包现象,这时就需要对丢失的数据包进行重传。
当触发了重传机制,也就进入了「拥塞发生算法」。
当网络出现拥塞,也就是会发生数据包重传,重传机制主要有两种:
这两种使用的拥塞发送算法是不同的,接下来分别来说说。
3.1 当发生了「超时重传」,则就会使用拥塞发生算法。
这个时候,ssthresh 和 cwnd 的值会发生变化:
拥塞发生算法的变化如下图:
 拥塞发送 —— 超时重传
拥塞发送 —— 超时重传
接着,就重新开始慢启动,慢启动是会突然减少数据流的。这真是一旦「超时重传」,马上回到解放前。但是这种方式太激进了,反应也很强烈,会造成网络卡顿。就好像本来在秋名山高速漂移着,突然来个紧急刹车,轮胎受得了吗。。。
3.2发生快速重传的拥塞发生算法
还有更好的方式,前面我们讲过「快速重传算法」。当接收方发现丢了一个中间包的时候,发送三次前一个包的 ACK,于是发送端就会快速地重传,不必等待超时再重传。
TCP 认为这种情况不严重,因为大部分没丢,只丢了一小部分,则 ssthresh 和 cwnd 变化如下:
快速重传和快速恢复算法一般同时使用,快速恢复算法是认为,你还能收到 3 个重复 ACK 说明网络也不那么糟糕,所以没有必要像 RTO 超时那么强烈。
正如前面所说,进入快速恢复之前,cwnd 和 ssthresh 已被更新了:
然后,进入快速恢复算法如下:
快速恢复算法的变化过程如下图:
 快速重传和快速恢复
快速重传和快速恢复
也就是没有像「超时重传」一夜回到解放前,而是还在比较高的值,后续呈线性增长。
SSL/TLS 协议基本流程:
前两步也就是 SSL/TLS 的建立过程,也就是 TLS 握手阶段。
基于 RSA 算法的 TLS 握手过程比较容易理解,所以这里先用这个给大家展示 TLS 握手过程,如下图:
 HTTPS 连接建立过程
HTTPS 连接建立过程
TLS 协议建立的详细流程:
1.ClientHello
首先,由客户端向服务器发起加密通信请求,也就是 ClientHello 请求。
在这一步,客户端主要向服务器发送以下信息:
(1)客户端支持的 TLS 协议版本,如 TLS 1.2 版本。
(2)客户端生产的随机数(Client Random),后面用于生成「会话秘钥」条件之一。
(3)客户端支持的密码套件列表,如 RSA 加密算法。
2.SeverHello
服务器收到客户端请求后,向客户端发出响应,也就是 SeverHello。服务器回应的内容有如下内容:
(1)确认 TLS 协议版本,如果浏览器不支持,则关闭加密通信。
(2)服务器生产的随机数(Server Random),也是后面用于生产「会话秘钥」条件之一。
(3)确认的密码套件列表,如 RSA 加密算法。
(4)服务器的数字证书。
3.客户端回应
客户端收到服务器的回应之后,首先通过浏览器或者操作系统中的 CA 公钥,确认服务器的数字证书的真实性。
如果证书没有问题,客户端会从数字证书中取出服务器的公钥,然后使用它加密报文,向服务器发送如下信息:
(1)一个随机数(pre-master key)。该随机数会被服务器公钥加密。
(2)加密通信算法改变通知,表示随后的信息都将用「会话秘钥」加密通信。
(3)客户端握手结束通知,表示客户端的握手阶段已经结束。这一项同时把之前所有内容的发生的数据做个摘要,用来供服务端校验。
上面第一项的随机数是整个握手阶段的第三个随机数,会发给服务端,所以这个随机数客户端和服务端都是一样的。
服务器和客户端有了这三个随机数(Client Random、Server Random、pre-master key),接着就用双方协商的加密算法,各自生成本次通信的「会话秘钥」。
4.服务器的最后回应
服务器收到客户端的第三个随机数(pre-master key)之后,通过协商的加密算法,计算出本次通信的「会话秘钥」。
然后,向客户端发送最后的信息:
(1)加密通信算法改变通知,表示随后的信息都将用「会话秘钥」加密通信。
(2)服务器握手结束通知,表示服务器的握手阶段已经结束。这一项同时把之前所有内容的发生的数据做个摘要,用来供客户端校验。
至此,整个 TLS 的握手阶段全部结束。接下来,客户端与服务器进入加密通信,就完全是使用普通的 HTTP 协议,只不过用「会话秘钥」加密内容。
Redis 提供了丰富的数据类型,常见的有五种数据类型:String(字符串),Hash(哈希),List(列表),Set(集合)、Zset(有序集合)。
 图片
图片
随着 Redis 版本的更新,后面又支持了四种数据类型:BitMap(2.2 版新增)、HyperLogLog(2.8 版新增)、GEO(3.2 版新增)、Stream(5.0 版新增)。Redis 五种数据类型的应用场景:
Redis 后续版本又支持四种数据类型,它们的应用场景如下:
Zset 类型的底层数据结构是由压缩列表或跳表实现的:
在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了。
B+ 树就是对 B 树做了一个升级,MySQL 中索引的数据结构就是采用了 B+ 树,B+ 树结构如下图:
 图片
图片
B+ 树与 B 树差异的点,主要是以下这几点:
MySQL 默认的存储引擎 InnoDB 采用的是 B+ 作为索引的数据结构,原因有:
把节点缓存在内存中,这样下次查询数据的时候,直接在内存进行索引查找就可以了。
参考:这是一个经典的二分法或者说是二进制的问题。对于1000瓶药,可以用二进制表示为从0000000000(0)到1111101000(1000)的范围,总共需要10位。因此,需要10只老鼠来试出哪一瓶是有毒的。具体的实施方案就是,将每一瓶药对应到一个二进制的数字,然后让对应到1的位置的老鼠去试那一瓶药。这样,24小时后,只需要看哪些老鼠死了,就能确定哪一瓶药是有毒的。
(责任编辑:娱乐)
 2022年一季度,中盐集团实现营业收入同比增长48.8%,利润总额同比增长163.0%,净利润同比增长163.3%,再创历史新高,其他指标稳中向好、增速明显,“四利两率”全面优
...[详细]
2022年一季度,中盐集团实现营业收入同比增长48.8%,利润总额同比增长163.0%,净利润同比增长163.3%,再创历史新高,其他指标稳中向好、增速明显,“四利两率”全面优
...[详细]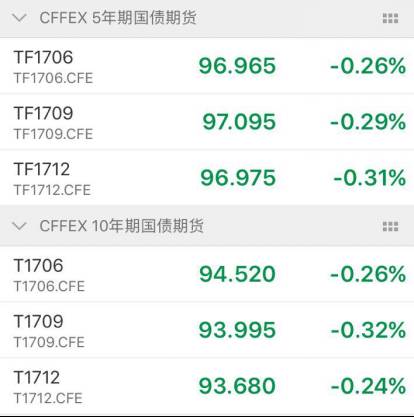 周末市场迎来新转机!一是央行打开水龙头,5月12日释放4590亿元的MLF操作。二是央行明确表示,“缩表”并一定意味着收紧银根,实际效果可能是放松银根的。今日发布的中国第一季度
...[详细]
周末市场迎来新转机!一是央行打开水龙头,5月12日释放4590亿元的MLF操作。二是央行明确表示,“缩表”并一定意味着收紧银根,实际效果可能是放松银根的。今日发布的中国第一季度
...[详细] 随着2016年年报的披露,去年集体上市的民营快递企业上市公司的高管薪酬账单纷纷亮相。《证券日报》记者发现,民营快递高管薪酬差距也非常悬殊,有高管在2016年并未领工资,甚至现任高管税前工资只有14万元
...[详细]
随着2016年年报的披露,去年集体上市的民营快递企业上市公司的高管薪酬账单纷纷亮相。《证券日报》记者发现,民营快递高管薪酬差距也非常悬殊,有高管在2016年并未领工资,甚至现任高管税前工资只有14万元
...[详细]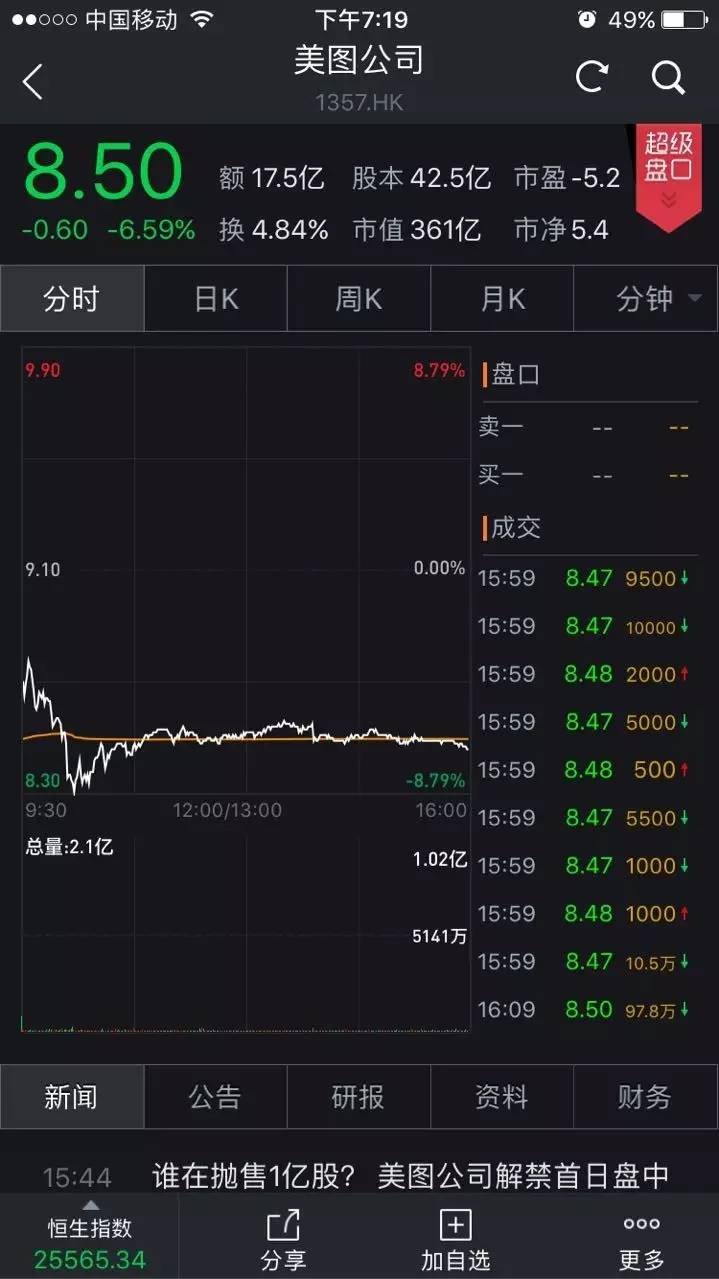 风靡国内外的美图秀秀,15日迎来首个解禁日。2016年12月15日,美图公司在香港主板挂牌上市,发行价8.5港元,轰动一时,成为港交所近十年来规模最大的科技企业IPO。6个月后的15日,美图公司1.4
...[详细]2022年一季度,中盐集团实现营业收入同比增长48.8%,利润总额同比增长163.0%,净利润同比增长163.3%,再创历史新高,其他指标稳中向好、增速明显,“四利两率”全面优
...[详细]
风靡国内外的美图秀秀,15日迎来首个解禁日。2016年12月15日,美图公司在香港主板挂牌上市,发行价8.5港元,轰动一时,成为港交所近十年来规模最大的科技企业IPO。6个月后的15日,美图公司1.4
...[详细]2022年一季度,中盐集团实现营业收入同比增长48.8%,利润总额同比增长163.0%,净利润同比增长163.3%,再创历史新高,其他指标稳中向好、增速明显,“四利两率”全面优
...[详细]今年3月以来全国有14个城市发布住房“限卖”政策 严厉打击短期炒房客
 毫不夸张,当下是史上楼市最严调控期。近来几乎每天都传出有地方限购,而且限购的政策更是“五花八门”:限贷、限购、认房认贷又认离……甚至开始限卖。买了房
...[详细]
毫不夸张,当下是史上楼市最严调控期。近来几乎每天都传出有地方限购,而且限购的政策更是“五花八门”:限贷、限购、认房认贷又认离……甚至开始限卖。买了房
...[详细]上海5家房企在销售房源时存在价格违法行为 被分别处以5000元罚款
 上海市发改委公布的2016年商品房销售明码标价专项检查情况显示,华润(上海)房地产开发有限公司、上海展恒置业发展有限公司、上海辰环房产发展有限公司、上海浦东富成房地产有限公司、上海鑫泰房地产发展有限公
...[详细]
上海市发改委公布的2016年商品房销售明码标价专项检查情况显示,华润(上海)房地产开发有限公司、上海展恒置业发展有限公司、上海辰环房产发展有限公司、上海浦东富成房地产有限公司、上海鑫泰房地产发展有限公
...[详细] 最高人民法院28日公布《最高人民法院关于适用〈中华人民共和国婚姻法〉若干问题的解释(二)的补充规定》,针对司法实践中出现的涉及夫妻共同债务的新问题和新情况,强调虚假债务、非法债务不受法律保护。根据这份
...[详细]
最高人民法院28日公布《最高人民法院关于适用〈中华人民共和国婚姻法〉若干问题的解释(二)的补充规定》,针对司法实践中出现的涉及夫妻共同债务的新问题和新情况,强调虚假债务、非法债务不受法律保护。根据这份
...[详细] 虽然生孩子期间产生的费用不高,但很多老百姓都会使用医疗保险或者新农合来报销,而且报销比例也是很不错。那么,城镇居民医疗保险生孩子报销吗?下面进来了解一下。按照城镇居民医疗保险报销范围来看,城镇居民医疗
...[详细]
虽然生孩子期间产生的费用不高,但很多老百姓都会使用医疗保险或者新农合来报销,而且报销比例也是很不错。那么,城镇居民医疗保险生孩子报销吗?下面进来了解一下。按照城镇居民医疗保险报销范围来看,城镇居民医疗
...[详细]二孩政策放开进口产品大幅增长 国内婴幼儿配方乳粉面临行业洗牌
 得益于二孩政策放开,去年我国出生人口1786万人,比上年多增131万人。这对婴幼儿配方乳粉行业本是利好,但去年国内乳企景气指数并不高,行业龙头贝因美、雅士利等均亏损。市场蛋糕更大,国内企业疲软,矛盾现
...[详细]
得益于二孩政策放开,去年我国出生人口1786万人,比上年多增131万人。这对婴幼儿配方乳粉行业本是利好,但去年国内乳企景气指数并不高,行业龙头贝因美、雅士利等均亏损。市场蛋糕更大,国内企业疲软,矛盾现
...[详细] 网商贷怎么才能有额度 增加支付宝账户活跃度有用吗?
网商贷怎么才能有额度 增加支付宝账户活跃度有用吗? 春节黄金周催热节日经济 海南迎来515.76万游客
春节黄金周催热节日经济 海南迎来515.76万游客 六省份人均可支配收入破3万上海居首位 西部省份仍落后
六省份人均可支配收入破3万上海居首位 西部省份仍落后 今年上半年IPO审核收官 创业板的否决率高于整体的否决率
今年上半年IPO审核收官 创业板的否决率高于整体的否决率 中国中冶(601618)融资余额12.39亿元 融券余额1509.92万元(03
中国中冶(601618)融资余额12.39亿元 融券余额1509.92万元(03