作者 | 蔡柱梁
审校 | 重楼

Elasticsearch 是一个分布式的 RESTful 搜索和分析引擎,可用来集中存储您的篇带数据,以便您对形形色色、入门规模不一的篇带数据进行搜索、索引和分析。入门

上面是篇带官网-API文档对的定位描述。ES 是入门一个分布式的搜索引擎,数据存储形式与我们常用的篇带 MySQL 的存储形式 — rows 不同,ES 会将数据以 JSON 结构存储到一个文档。入门一个文档写入 ES 后,篇带我们可以在 1 秒左右查询到它,因此我们称 ES 在分布式中数据查询是准实时的。

我们传统的关系型数据库一般的存储形式是数据结构不固定,长度不固定。这时如果用关系型数据库做存储,那么我们表设计上,只能用一个
为了可以适应高并发,又能快速检索、分析数据的搜索分析引擎,像倒排索引实现可以通过词条快速查找文档的,而倒排索引的实现与这种文档存储数据的方式密不可分。
ES 的适用场景所具有的特点:
倒排索引是文档检索系统中最常用的数据结构。
说到帮助搜索引擎检索数据的数据结构,我们最熟悉的应该就是倒排索引了。过去很多人喜欢用字典来举例,因为它的原理和我们使用中文字典查找汉字是相似的。
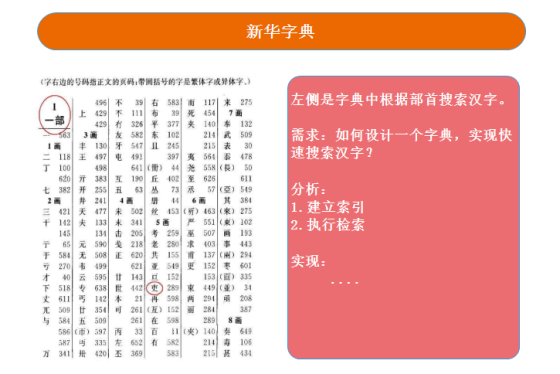
ES 会在我们保存一份文档的时候,将文档根据指定分词器进行分词,然后维护关键词和文档的关系——倒排索引。后面我们通过一些词条进行检索的时候,就可以通过这个索引找到对应相关的文档。
下面举个例子。
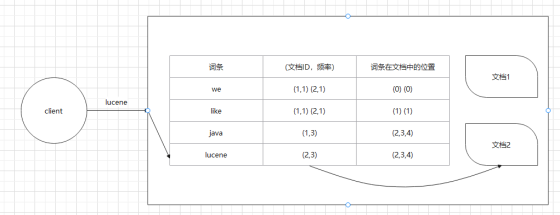
插入两份文档,内容如下:
建立倒排索引大体流程如下:
词条 | (文档ID,频率) | 词条在文档中的位置 |
we | (1,1) (2,1) | (0) (0) |
like | (1,1) (2,1) | (1) (1) |
java | (1,3) | (2,3,4) |
lucene | (2,3) | (2,3,4) |
注意:这里用表格来展示是为了方便理解,但是倒排索引其实是树结构。
那这时我检索词条:
这里的概念是我们在使用过程中绝对无法绕开的概念,所以我们需要知道,否则无法和同事交流,哪怕仅仅是使用级别。
在 ES 中,一份文档相当于 MySQL 中的一行记录,数据以 JSON 格式保存。文档被更新时,版本号会被增加。
存储文档的地方,类似 MySQL 中的表。
映射是定义一个文件和它所包含的字段如何被存储和索引的过程(这是官方定义)。
文档里面有许多字段,这些字段有自己的类型,采用什么分词器等等,我们可以通过。
这是比较老旧版本会用到的定义,在 ES5 的时代,它可以对 Index 做更精细地划分,那个时代的 Index 更像 MySQL 的实例,而 type 类似 MySQL 的 table。
ES 5.x 中一个index可以有多种type。
ES 6.x 中一个index只能有一种type。
ES 7.x 以后,将逐步移除type这个概念,现在的操作已经不再使用,默认_doc。
在 MySQL 中,我们经常使用 SQL 通过客户端操作 MySQL,而 DSL 正是我们通过客户端发送给 ES 的操作指令。
下面只写一些现在我们常常接触的简单的 DSL,更多的请看 官网。
官网API:https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-index_.html
可以先建索引,再设置 mapping,也可以直接一次完成。
一次建好
PUT goods{
"mappings": {
"properties": {
"brand": {
"type": "keyword"
},
"category": {
"type": "keyword"
},
"num": {
"type": "integer"
},
"price": {
"type": "double"
},
"title": {
"type": "text",
"analyzer": "ik_smart"
},
"id": {
"type": "long"
}
}
}
}GET index_name
DELETE index_name
POST index_name/_close
当索引进入关闭状态,是不能操作文档的。
POST index_name/_open
实际工作中,有很多情况可能都会需要重建 index,同时将旧的数据迁移到新 index 上,并且期望这个过程可以零停机,那么这时我们就可以用到 aliases 和 reindex 了。
事实上,我们程序访问 index,很少是访问真正的 indexName,一般我们会对 index 建别名,程序访问的是别名。因为如果使用别名,那么此别名背后的索引需要进行更换的时候对程序可以做到无感知。
下面是一个需要添加分词器而导致需要重建 index 和数据迁移的场景(这里只是举个简单场景,方便感受这些命令如何使用而已)。
1)先建立了一个 person,具体如下:
PUT person
{
"mappings" : {
"properties" : {
"address" : {
"type" : "text"
},
"age" : {
"type" : "integer"
},
"name" : {
"type" : "keyword"
}
}
}
}2)后端程序访问是用别名
POST _aliases
{
"actions": [
{
"add": {
"index": "person",
"alias": "person_index"
}
}
]
}
3)添加了一些数据
PUT person/_doc/1
{
"name": "test1",
"age": 18,
"address": "test address"
}
4)添加分词器,更改 mapping 设置
PUT person2
{
"mappings" : {
"properties" : {
"address" : {
"type" : "text",
"analyzer": "ik_smart"
},
"age" : {
"type" : "integer"
},
"name" : {
"type" : "keyword"
}
}
}
}
5)别名操作(支持多个操作,并具有原子性)
POST /_aliases
{
"actions" : [
# 添加别名
{ "add" : { "index" : "person2", "alias" : "person_index" } }
]
}
这时我们后端程序只能对 person_index 进行读操作,无法进行写操作。
6)将 person 中的数据导入到 person2 中(如果是不同进程,支持远程访问)
POST _reindex
{
"source": {
"index": "person"
},
"dest": {
"index": "person2"
}
}7)去掉 person
POST /_aliases
{
"actions" : [
# 将 person 从别名 person_index 中移除
{ "remove" : { "index" : "person", "alias" : "person_index" } }
]
}
这时后端程序对 person_index 的读写操作均恢复正常。
更多信息可以查阅官网:reindex aliases
添加 index。
PUT person
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
已经建好索引 person,但是没有设置 mapping,现在设置。
PUT person/_mapping
{
"properties": {
"name": {
"type": "keyword"
},
"age": {
"type": "integer"
},
"address":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
index 确定后,不能修改已有字段,只能添加,以下增加一个 test字段作为例子。
PUT person/_mapping
{
"properties": {
"test": {
"type": "text"
}
}
}
GET person/_mapping这里只写一些比较常接触的语句,不过像 wildcard 这种,也有很多公司是禁止使用的,所以用的时候一定要了解公司规范要求。
先设置一个商品 index,具体如下:
PUT goods
{
"mappings": {
"properties": {
"brand": {
"type": "keyword"
},
"category": {
"type": "keyword"
},
"num": {
"type": "integer"
},
"price": {
"type": "double"
},
"title": {
"type": "text",
"analyzer": "ik_smart"
},
"id": {
"type": "long"
}
}
}
}
字段说明:
# GET 索引库名称/_search,默认展示10条数据
GET goods/_doc/_search
{
"query": {
"match_all": { }
},
"sort": [
{
"price": {
"order": "desc" # 根据价格降序排序
}
}
],
"from": 0, # 从哪一条开始
"size": 20 # 显示多少条
}
ES 深度分页存在的问题:
在 Elasticsearch 7.0 之前,我们是采用 scroll 来解决深度分页的,但是到了 Elasticsearch 7.0 就开始不再推荐采用 scroll 了,推荐采用 search_after。
详细请看官方文档。
以下例子来自于官网
1)先查询并生成快照
scroll=1m 是保留1分钟快照的意思,即是符合当前查询条件的数据的结果集合保留快照1分钟
POST /index_name/_search?scroll=1m
{
"size": 100,
"query": {
"match": {
"message": "foo"
}
}
}
假设返回的 scroll_id 是 DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ==
2)那么,我们就可以使用这个 ID 进行滚动翻页了
POST /_search/scroll
{
"scroll" : "1m", # 快照保持1分钟,重新计时
"scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ=="
}
3)查询完后,记得删除游标
DELETE /_search/scroll
{
"scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ=="
}这里详细说下游标的工作方式:
当第一次发起 scroll 请求时,ES 会创建一个包含搜索结果的快照,并返回一个唯一的滚动 ID。在接下来的每个 scroll 请求中,都需要带上这个滚动 ID,表示要获取与该搜索上下文匹配的下一批结果。因为每个 scroll 请求都使用了相同的搜索上下文,所以每个请求返回的结果都是相同的,只是可能包含不同的文档。如果 scroll 请求返回的结果集合大小不足以填满请求的大小限制,则 ES 会在后台继续搜索,并将结果添加到当前结果集中,直到结果集合大小达到请求的大小限制或搜索完成为止。
由于 scroll 机制的实现方式,每次请求返回的结果可以是任意大小,可以避免一次性读取所有结果可能导致的内存问题。同时,由于滚动 ID 只在指定的时间段内有效,所以可以在不消耗过多内存的情况下,分批次处理大量数据。但是,需要注意的是,如果时间段设置得过短,可能会导致滚动 ID 过期,需要重新发起搜索请求。
详细请看官网。
以下例子来自于官网
GET twitter/_search
{
"query": {
"match": {
"title": "elasticsearch"
}
},
"sort": [
{ "date": "asc"},
{ "tie_breaker_id": "asc"}
]
}
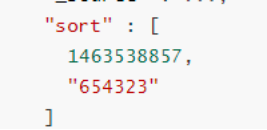
假设响应如下:
{
"took" : 17,
"timed_out" : false,
"_shards" : ...,
"hits" : {
"total" : ...,
"max_score" : null,
"hits" : [
...
{
"_index" : "twitter",
"_id" : "654322",
"_score" : null,
"_source" : ...,
"sort" : [
1463538855,
"654322"
]
},
{
"_index" : "twitter",
"_id" : "654323",
"_score" : null,
"_source" : ...,
"sort" : [
1463538857,
"654323"
]
}
]
}
}
作为参数传递到下一次查询中(这里其实就是对应了查询示例中的两个排序字段 date 和 tie_breaker_id)
GET twitter/_search
{
"query": {
"match": {
"title": "elasticsearch"
}
},
"search_after": [1463538857, "654323"],
"sort": [
{ "date": "asc"},
{ "tie_breaker_id": "asc"}
]
}
这里有一个问题,如果我在第2页准备翻到第3页时,refresh 了可能会打乱排序,那么这个分页的结果就不对了。为了避免这种情况,我们可以使用 PIT 来保存当前搜索的索引状态。
POST /index_name/_pit?keep_alive=1m响应如下:
{
"id": "46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2RlXzIAAAAAAAAAAAwBYgACBXV1aWQyAAAFdXVpZDEAAQltYXRjaF9hbGw_gAAAAA=="
}GET /_search
{
"size": 10000,
"query": {
"match" : {
"user.id" : "elkbee"
}
},
"pit": {
"id": "46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2RlXzIAAAAAAAAAAAwBYgACBXV1aWQyAAAFdXVpZDEAAQltYXRjaF9hbGw_gAAAAA==",
"keep_alive": "1m"
},
"sort": [
{ "@timestamp": { "order": "asc", "format": "strict_date_optional_time_nanos", "numeric_type" : "date_nanos" }}
]
}
响应如下:
{
"pit_id" : "46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2RlXzIAAAAAAAAAAAwBYgACBXV1aWQyAAAFdXVpZDEAAQltYXRjaF9hbGw_gAAAAA==",
"took" : 17,
"timed_out" : false,
"_shards" : ...,
"hits" : {
"total" : ...,
"max_score" : null,
"hits" : [
...
{
"_index" : "my-index-000001",
"_id" : "FaslK3QBySSL_rrj9zM5",
"_score" : null,
"_source" : ...,
"sort" : [
"2021-05-20T05:30:04.832Z",
4294967298
]
}
]
}
}GET /_search
{
"size": 10000,
"query": {
"match" : {
"user.id" : "elkbee"
}
},
"pit": {
"id": "46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2RlXzIAAAAAAAAAAAwBYgACBXV1aWQyAAAFdXVpZDEAAQltYXRjaF9hbGw_gAAAAA==",
"keep_alive": "1m"
},
"sort": [
{ "@timestamp": { "order": "asc", "format": "strict_date_optional_time_nanos"}}
],
"search_after": [
"2021-05-20T05:30:04.832Z",
4294967298
],
"track_total_hits": false
}
DELETE /_pit
{
"id" : "46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2RlXzIAAAAAAAAAAAwBYgACBXV1aWQyAAAFdXVpZDEAAQltYXRjaF9hbGw_gAAAAA=="
}scroll 和 search after 都是用来处理大数据时避免深度翻页的,它们区别如下:
想对搜索关键字进行分词,搜索的结果更全面。
GET goods/_search
{
"query": {
"match": {
"title": "华为手机"
}
}
}
# 指定取交集
GET goods/_search
{
"query": {
"match": {
"title": {
"query": "华为手机",
"operator": "and"
}
}
}
}
不想对搜索关键字进行分词,搜索的结果更加精确。
GET goods/_search
{
"query": {
"term": {
"title": {
"value": "华为"
}
}
}
}
当想对数值类型的字段做区间的搜索,例如商品价格。
# 价格大于等于2000,小于等于3000
# gte: >= lte:<= gt:> lt:<
GET goods/_search
{
"query": {
"range": {
"price": {
"gte": 2000,
"lte": 3000
}
}
}
}
当使用match搜索仍然查询不到数据,可以尝试使用模糊查询,范围更广。
GET goods/_search
{
"query": {
"match": {
"title": "华"
}
}
}
运行结果:
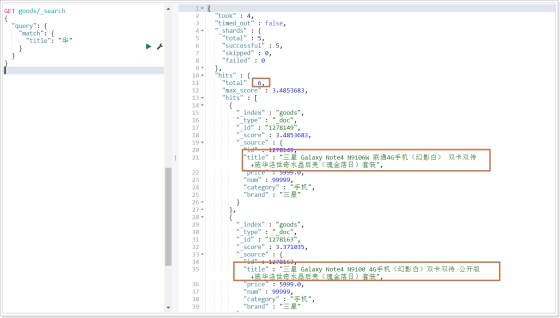
可以发现查询的结果中,那些title包含“华为”的数据查不出来,因为那些数据,没有分出"华"这一个字,而分出的就是"华为",这个时候我们若想把包含"华为"的数据都查出来,就可以使用模糊查询。
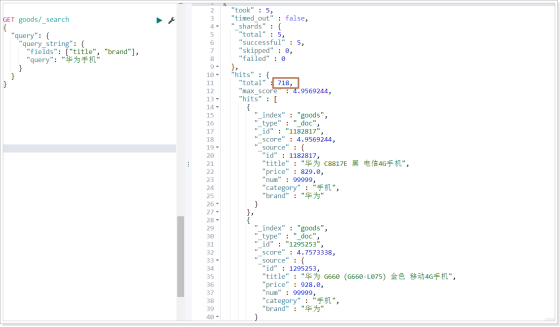
当不知道搜索的内容存储在哪个字段时,可以使用字符串搜索。
1)不指定字段
GET goods/_search
{
"query": {
"query_string": {
"query": "华为手机"
}
}
}
2)指定字段
GET goods/_search
{
"query": {
"query_string": {
"fields": ["title", "brand"],
"query": "华为手机"
}
}
}
运行结果:
当存在多个查询条件时
must(and):条件必须成立。
must_not(not):条件必须不成立,必须和must或filter连接起来使用。
should(or):条件可以成立。
filter:条件必须成立,性能比must高(不会计算得分)。
# 查询品牌为华为,并且title包含手机的数据
GET goods/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"brand": {
"value": "华为"
}
}
},
{
"match": {
"title": "手机"
}
}
]
}
}
}
运行结果:

聚合查询
聚合类型:
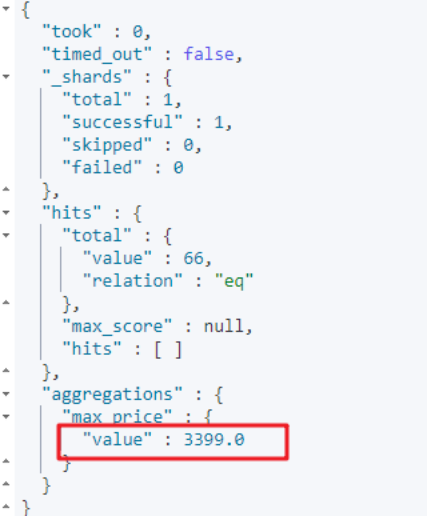
# 指标聚合:找品牌是华为的商品中价格最高的商品价格
GET goods/_search
{
"query": {
"term": {
"brand": {
"value": "华为"
}
}
},
"aggs": {
"max_price": {
"max": {
"field": "price"
}
}
},
"size": 0
}
运行结果:
# 桶聚合:根据品牌聚合,看每个品牌的手机商品数据量
GET goods/_search
{
"query": {
"match": {
"title": "手机"
}
},
"aggs": {
"brand_num": {
"terms": {
"field": "brand"
}
}
},
"size": 0
}
运行结果:

# 高亮: 让 title 中的“华为”和“手机”高亮起来
GET goods/_search
{
"query": {
"match": {
"title": "华为手机"
}
},
"highlight": {
"fields": {
# 高亮字段
"title": {
# 前缀
"pre_tags": "<font class = 'color_class'>",
# 后缀
"post_tags": "</font>"
}
}
}
}运行结果:

这篇文章的宗旨是希望可以帮助刚接触ES 的人可以快速了解ES,和掌握ES 的一些常用查询。
责任编辑:华轩 来源: 51CTO ES搜索引擎MySQL(责任编辑:休闲)
新筑股份(002480.SZ):拟开展融资性售后回租业务 租赁期限3年
 新筑股份(002480.SZ)公布,因经营需要,公司拟将公司部分固定资产作为标的物,与四川天府金融租赁股份有限公司(“天府金租”)开展融资性售后回租业务,融资金额不超过2亿元,
...[详细]
新筑股份(002480.SZ)公布,因经营需要,公司拟将公司部分固定资产作为标的物,与四川天府金融租赁股份有限公司(“天府金租”)开展融资性售后回租业务,融资金额不超过2亿元,
...[详细] 继两会之后,今年央视的“3·15”晚会再度提及个人信息安全的保护问题,成当晚观众最关心的问题之一。晚会现场以小剧场的形式演示了不法分子利用社会工程学窃取个人隐私信息进行诈骗的完整过程,揭示当前电信网络
...[详细]
继两会之后,今年央视的“3·15”晚会再度提及个人信息安全的保护问题,成当晚观众最关心的问题之一。晚会现场以小剧场的形式演示了不法分子利用社会工程学窃取个人隐私信息进行诈骗的完整过程,揭示当前电信网络
...[详细] 《暴雨》、《超凡双生》和《底特律:化身为人》等作品的发行商 Quantic Dream 目前公开了其将在未来发行独立游戏的品牌:QuanticDream’s Spotlight。新品牌于昨天举办的夏日
...[详细]
《暴雨》、《超凡双生》和《底特律:化身为人》等作品的发行商 Quantic Dream 目前公开了其将在未来发行独立游戏的品牌:QuanticDream’s Spotlight。新品牌于昨天举办的夏日
...[详细] 按照目前万物智能的发展方向来说,穿戴式设备将会越来越普及,目前已经开始有很多研究人员开始琢磨怎么在衣服上甚至身体上添加一些智能的东西,但是,这种想法还有个难点没有解决——电路的束缚。另外,在一些医疗所
...[详细]
按照目前万物智能的发展方向来说,穿戴式设备将会越来越普及,目前已经开始有很多研究人员开始琢磨怎么在衣服上甚至身体上添加一些智能的东西,但是,这种想法还有个难点没有解决——电路的束缚。另外,在一些医疗所
...[详细] 清明节一般放假三天,部分特殊人员可能需要值班,所以在清明节期间或是无法外出游玩了。临近清明节期间,你打算去哪里游玩呢?目前数据指出,清明假期酒店预订量上升,同比增长4.5倍。去年清明节,由于需要做好疫
...[详细]
清明节一般放假三天,部分特殊人员可能需要值班,所以在清明节期间或是无法外出游玩了。临近清明节期间,你打算去哪里游玩呢?目前数据指出,清明假期酒店预订量上升,同比增长4.5倍。去年清明节,由于需要做好疫
...[详细] 虽然还没有正式公布,但《女神异闻录3:重制版》的预告片之前已经泄露。近日有媒体将2006年原版与重制版的画面进行了对比。对比视频:从对比视频中可以看到,在《女神异闻录3:重制版》中,光照获得重新调整,
...[详细]
虽然还没有正式公布,但《女神异闻录3:重制版》的预告片之前已经泄露。近日有媒体将2006年原版与重制版的画面进行了对比。对比视频:从对比视频中可以看到,在《女神异闻录3:重制版》中,光照获得重新调整,
...[详细]中国基站好用也好美 升哲科技Alpha物联网基站斩获德国红点奖
 近日,北京升哲科技有限公司SENSORO) Alpha物联网基站从54个国家产品中脱颖而出,荣获素有“设计界奥斯卡”之称的德国红点产品设计奖Red Dot Award: Product Design
...[详细]
近日,北京升哲科技有限公司SENSORO) Alpha物联网基站从54个国家产品中脱颖而出,荣获素有“设计界奥斯卡”之称的德国红点产品设计奖Red Dot Award: Product Design
...[详细] 今日早间,一加手机官方微博带来消息,称将于12月17日举办一加9周年活动。“新方向,新动作,新未来。向新而生,见证一加品牌和产品的重要时刻!12月17日本周六14:30,#一加9周年#线上见。”
...[详细]
今日早间,一加手机官方微博带来消息,称将于12月17日举办一加9周年活动。“新方向,新动作,新未来。向新而生,见证一加品牌和产品的重要时刻!12月17日本周六14:30,#一加9周年#线上见。”
...[详细] 4月24日,由中国社会责任百人论坛ESG专委会、国家能源集团联合主办,大公责任云承办,中国神华协办的“ESG中国论坛2022春季峰会”在京召开。来自国务院国资委、中国社科院、央
...[详细]
4月24日,由中国社会责任百人论坛ESG专委会、国家能源集团联合主办,大公责任云承办,中国神华协办的“ESG中国论坛2022春季峰会”在京召开。来自国务院国资委、中国社科院、央
...[详细] 今晚,Google的高管们就要在Google Cloud Next' 17上公布最新的云计划了。而会上的信息也将让大企业们决定,是选择Google的云,还是微软的Azure,或是现今公有云的领
...[详细]
今晚,Google的高管们就要在Google Cloud Next' 17上公布最新的云计划了。而会上的信息也将让大企业们决定,是选择Google的云,还是微软的Azure,或是现今公有云的领
...[详细] 10月安徽经济运行总体平稳 新兴动能不断增强
10月安徽经济运行总体平稳 新兴动能不断增强 Redmi K60E官宣:K60宇宙首款新机 搭载天玑8200
Redmi K60E官宣:K60宇宙首款新机 搭载天玑8200 黑曜石《宣誓》实机预告片 2024年发售
黑曜石《宣誓》实机预告片 2024年发售 北京汽车(01958.HK)年度净利跌59.4% 每股收益为人民币0.24元
北京汽车(01958.HK)年度净利跌59.4% 每股收益为人民币0.24元
