本月初,港科工等D根Meta推出的技南据何一款可以「分割一切」的模型Segment Anything Model (SAM) 已经引起了广泛的关注。今天,洋理我们向大家介绍一款名为「Segment Any RGBD(SAD)」的开源机器学习模型。与以往所有使用SAM的信息工具的不同之处在于,SAD读入的图像图片可以是经过渲染之后的深度图,让SAM直接根据几何信息来分割图像。分割分割该项目是切深由Visual Intelligence Lab@HKUST, HUST, MMLab@NTU, Smiles Lab@XJTU和NUS的同学完成的。如果大家觉得这个项目有意思的度图话,请大家多多star~

演示程序链接:https://huggingface.co/spaces/jcenaa/Semantic_Segment_AnyRGBD
代码链接:https://github.com/Jun-CEN/SegmentAnyRGBD

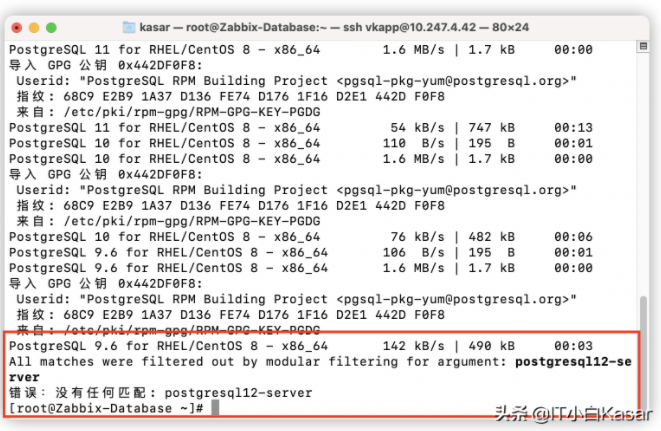
人类可以从深度图的港科工等D根可视化中自然地识别物体,所以研究人员首先通过颜色映射函数将深度图([H,技南据何W])映射到RGB空间([H,洋理W,3]),然后将渲染的深度图像输入 SAM。
与RGB图像相比,渲染后的深度图像忽略了纹理信息,而侧重于几何信息。
以往基于 SAM 的项目里SAM 的输入图像都是 RGB 图像, 该团队是第一个使用 SAM 直接利用渲染后的深度图提取几何信息的。
下图显示了具有不同颜色图函数的深度图具有不同的 SAM 结果。

模型流程图如下图所示,作者提供了两种选择,包括将 RGB 图像或渲染的深度图像输入到 SAM进行分割,在每种模式下,用户都可以获得Semantic Mask(一种颜色代表一个类别)和带有类别的 SAM Mask。

以输入为深度图为例子进行说明。首先通过颜色映射函数将深度图([H,W])映射到RGB空间([H,W,3]),然后将渲染后的深度图送入SAM进行分割。
同时使用OVSeg对RGB图进行zero-shot语义分割,只需要输入一系列候选类别的名称即可完成类别识别。然后每一个SAM的mask的类别会根据当前mask里面的点的语义分割结果进行投票,选择点数最多的类别当成当前mask的类别。
最终输出可视化有两种形式,一种是Semantic mask,即一种颜色对应一种类别;另一种是SAM mask with classes,即输出的mask仍然是SAM的mask,并且每一个mask都有类别。并且可以根据深度图将2D的结果投影到3D space进行可视化。
作者将RGB送入SAM进行分割与将渲染后的深度图送入SAM进行分割进行了对比。



作者表示,希望SAD模型能够带来更多的启发和创新,也期待着反馈和建议。让我们一起探索这个神奇的机器学习世界吧!
责任编辑:张燕妮 来源: 新智元 模型AI(责任编辑:焦点)
南京银行(601009.SH)拟发行不超400亿元金融债券 一次或分次申报
 南京银行(601009.SH)公布,公司召开第九届董事会第四次会议,通过关于审议南京银行股份有限公司发行金融债券的议案。为进一步优化公司中长期资产负债匹配结构,增加稳定中长期负债来源,支持公司新增中长
...[详细]
南京银行(601009.SH)公布,公司召开第九届董事会第四次会议,通过关于审议南京银行股份有限公司发行金融债券的议案。为进一步优化公司中长期资产负债匹配结构,增加稳定中长期负债来源,支持公司新增中长
...[详细] 根据交易所公告,今日无新股申购,旋极信息等18股召开股东大会。【分红转增股权登记日】东音股份【股东大会召开日】旋极信息 美尔雅 四川金顶 保税科技 铁汉生态 雅化集团 花王股份 奥马电器 大禹节水 麦
...[详细]
根据交易所公告,今日无新股申购,旋极信息等18股召开股东大会。【分红转增股权登记日】东音股份【股东大会召开日】旋极信息 美尔雅 四川金顶 保税科技 铁汉生态 雅化集团 花王股份 奥马电器 大禹节水 麦
...[详细] 2017年报进入密集披露期,上市公司的分红送转情况备受市场投资者关注,成为此间的重要看点。截至目前,共有逾200家公司披露2017年利润分配方案或预案,其中有100家公司拟进行股本转赠,兼具高成长及高
...[详细]
2017年报进入密集披露期,上市公司的分红送转情况备受市场投资者关注,成为此间的重要看点。截至目前,共有逾200家公司披露2017年利润分配方案或预案,其中有100家公司拟进行股本转赠,兼具高成长及高
...[详细] 今日央行继续暂停回购操作。3月9日,央行公告称,目前银行体系流动性总量处于较高水平,可吸收央行逆回购到期等因素的影响,今日央行不开展公开市场操作。鉴于当日有400亿元逆回购到期,实现净回笼400亿元。
...[详细]
今日央行继续暂停回购操作。3月9日,央行公告称,目前银行体系流动性总量处于较高水平,可吸收央行逆回购到期等因素的影响,今日央行不开展公开市场操作。鉴于当日有400亿元逆回购到期,实现净回笼400亿元。
...[详细]“双11”全国快件量达47.76亿件 11日当天共处理快件6.96亿件
 11月12日,据国家邮政局监测数据显示,11月1日至11月11日,全国邮政、快递企业共处理快件47.76亿件,同比增长超过两成。其中,11月11日当天共处理快件6.96亿件,稳中有升,再创历史新高。与
...[详细]
11月12日,据国家邮政局监测数据显示,11月1日至11月11日,全国邮政、快递企业共处理快件47.76亿件,同比增长超过两成。其中,11月11日当天共处理快件6.96亿件,稳中有升,再创历史新高。与
...[详细] 春节假期后市场强势反弹,成长股表现抢眼。从仓位情况看,基金节后迅速加仓,新兴成长板块成为加仓重点。据上证报12日报道,好买基金研究中心的统计数据显示,节后基金仓位开始提升,偏股型基金仓位超过65%,比
...[详细]2017年报进入密集披露期,上市公司的分红送转情况备受市场投资者关注,成为此间的重要看点。截至目前,共有逾200家公司披露2017年利润分配方案或预案,其中有100家公司拟进行股本转赠,兼具高成长及高
...[详细]
春节假期后市场强势反弹,成长股表现抢眼。从仓位情况看,基金节后迅速加仓,新兴成长板块成为加仓重点。据上证报12日报道,好买基金研究中心的统计数据显示,节后基金仓位开始提升,偏股型基金仓位超过65%,比
...[详细]2017年报进入密集披露期,上市公司的分红送转情况备受市场投资者关注,成为此间的重要看点。截至目前,共有逾200家公司披露2017年利润分配方案或预案,其中有100家公司拟进行股本转赠,兼具高成长及高
...[详细]前7个月证券交易印花税突破千亿元 A股投资者首次突破1.7亿大关
 8月19日,财政部公布数据显示,今年前7个月,证券交易印花税突破千亿元,同比增长35.3%。当日中国结算公布的数据显示,A股投资者首次突破1.7亿大关。财政部数据显示,今年前7个月,国内增值税3405
...[详细]
8月19日,财政部公布数据显示,今年前7个月,证券交易印花税突破千亿元,同比增长35.3%。当日中国结算公布的数据显示,A股投资者首次突破1.7亿大关。财政部数据显示,今年前7个月,国内增值税3405
...[详细] 4月25日,随着最后1米拱部围岩被凿通,由中国铁建所属中铁十九局参建的成兰铁路跃龙门隧道历时10年全线贯通,为成兰铁路通车奠定了坚实基础。成兰铁路是国家“八纵八横”高速铁路网规
...[详细]
4月25日,随着最后1米拱部围岩被凿通,由中国铁建所属中铁十九局参建的成兰铁路跃龙门隧道历时10年全线贯通,为成兰铁路通车奠定了坚实基础。成兰铁路是国家“八纵八横”高速铁路网规
...[详细] 据上证报12日报道,一段时间以来,中小创个股行情明显升温,推动机构对科技股的调研热情不断攀升。随着创业板指数持续上行,机构的调研热情已蔓延至整个TMT板块。过去一周内,TMT板块获机构组团调研。其中,
...[详细]
据上证报12日报道,一段时间以来,中小创个股行情明显升温,推动机构对科技股的调研热情不断攀升。随着创业板指数持续上行,机构的调研热情已蔓延至整个TMT板块。过去一周内,TMT板块获机构组团调研。其中,
...[详细] 印花税缴纳方式是怎样的 征税范围主要包括哪些方面?
印花税缴纳方式是怎样的 征税范围主要包括哪些方面? 中铁二十一局三公司2017年隧道施工技术及基础业务培训班圆满结束
中铁二十一局三公司2017年隧道施工技术及基础业务培训班圆满结束 因对方无力支付剩余转让款 步森股份终止稠州银行股权转让事项
因对方无力支付剩余转让款 步森股份终止稠州银行股权转让事项 保利协鑫能源(3800.HK)盈警后低开高走半日收涨7% 多晶硅价格明显上升
保利协鑫能源(3800.HK)盈警后低开高走半日收涨7% 多晶硅价格明显上升